Инновационное сжатие кэша KV на основе L2 нормы для больших языковых моделей
Большие языковые модели (LLM) созданы для выполнения сложных языковых задач путем улавливания контекста и долгосрочных зависимостей. Ключевым фактором их производительности является способность обрабатывать входные данные с длинным контекстом, что позволяет глубже понять содержание на обширных текстовых последовательностях.
Однако это преимущество сопровождается увеличением потребления памяти из-за хранения и извлечения контекстуальной информации из предыдущих входов, что может потреблять значительные вычислительные ресурсы.
Практические решения:
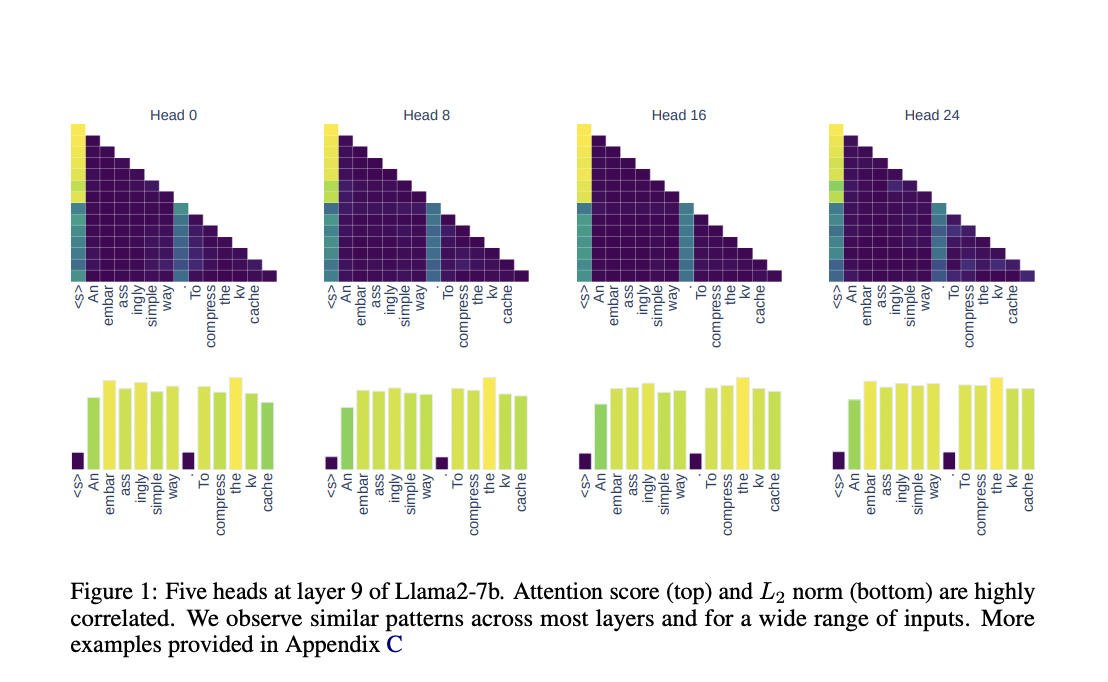
Исследователи из Университета Эдинбурга и Университета Сапиенца в Риме предложили новый подход для сжатия кэша KV, который является более простым и эффективным по сравнению с существующими решениями. Эта стратегия использует корреляцию между L2 нормой вложений ключей и соответствующими оценками внимания, позволяя модели сохранять только наиболее влиятельные пары KV. Такой подход не требует дополнительного обучения или сложных модификаций и может быть реализован непосредственно в любой декодирующей языковой модели на основе трансформера. Удерживая только пары KV с наименьшей L2 нормой, исследователи продемонстрировали, что модель может сократить потребление памяти, сохраняя при этом высокую точность.
Эксперименты показали, что сжатие кэша KV с использованием стратегии L2 нормы позволило сократить использование памяти до 50% в общих задачах языкового моделирования без значительного влияния на показатели сложности модели или точности. Для задач, требующих извлечения конкретной информации из длинных контекстов, таких как задача восстановления ключа, модель достигла 100% точности даже при сжатии 90% кэша KV.
Этот подход также успешно демонстрировал устойчивую производительность на сложных задачах с длинным контекстом, таких как тест «иголка в стоге сена», где модель поддерживала 99% точности при сжатии 50% кэша KV.
Значимость решения:
Предложенная методология обеспечивает замечательные результаты на различных задачах. Сжатие кэша KV с использованием стратегии L2 нормы позволило значительно снизить потребление памяти, сохраняя при этом высокую производительность модели. Этот подход является универсальным, совместимым с различными архитектурами моделей и легко внедряемым, что делает его ценным вкладом в область больших языковых моделей.

























