«`html
Решения в области распознавания речи с улучшенной точностью временных меток, устойчивостью к шуму и точным обнаружением дисфлюенций для клинических приложений
Точное транскрибирование устной речи в письменный текст становится все более важным в области распознавания речи. Эта технология необходима для доступности услуг, обработки языка и клинических оценок. Однако основной вызов заключается в точном воспроизведении слов и тонких деталей человеческой речи, включая паузы, заполнительные слова и другие дисфлюенции. Эти нюансы предоставляют ценную информацию о когнитивных процессах и особенно важны в клинических условиях, где точный анализ речи может помочь в диагностике и мониторинге речевых нарушений.
Одним из наиболее значительных вызовов в этой области является точность временных меток на уровне слов. Это особенно важно в ситуациях с несколькими дикторами или фоновым шумом, где традиционные методы часто нуждаются в улучшении. Точное транскрибирование дисфлюенций, таких как заполнительные паузы, повторения слов и исправления, трудно, но важно. Эти элементы не являются просто артефактами речи; они отражают скрытые когнитивные процессы и являются ключевыми показателями для оценки состояний, таких как афазия. Существующие модели транскрибирования часто нуждаются в помощи с этими нюансами, что приводит к ошибкам как в транскрибировании, так и в определении временных меток. Эти неточности ограничивают их эффективность, особенно в клинических и других ответственных средах, где точность играет ключевую роль.
Практические решения и ценность
В этой области одним из практических решений является модель CrisperWhisper, разработанная исследователями в компании Nyra Health. Эта модель улучшила архитектуру Whisper, повысив устойчивость к шуму и сосредоточив внимание на речи одного диктора. Исследователи значительно улучшили точность временных меток на уровне слов, тщательно настраив токенизатор и модель. CrisperWhisper использует алгоритм динамического временного искажения, который выравнивает речевые сегменты с большей точностью, даже в условиях фонового шума. Это улучшение повышает производительность модели в шумных средах и снижает ошибки в транскрибировании дисфлюенций, что делает ее особенно полезной для клинических приложений.
Улучшения CrisperWhisper в значительной степени обусловлены несколькими ключевыми инновациями. Модель удаляет ненужные токены и оптимизирует словарный запас для более точного обнаружения пауз и заполнительных слов, таких как «э-э» и «э-эм». Она внедряет эвристику, ограничивающую длительность пауз до 160 мс, различая значимые паузы в речи и незначительные артефакты. CrisperWhisper использует матрицу стоимости, построенную на нормализованных векторах кросс-внимания, чтобы гарантировать, что временная метка каждого слова максимально точна. Этот метод позволяет модели создавать транскрипции, которые не только более точны, но и более надежны в шумных условиях. Результатом является модель, способная точно зафиксировать время речи, что критически важно для приложений, требующих детального анализа речи.
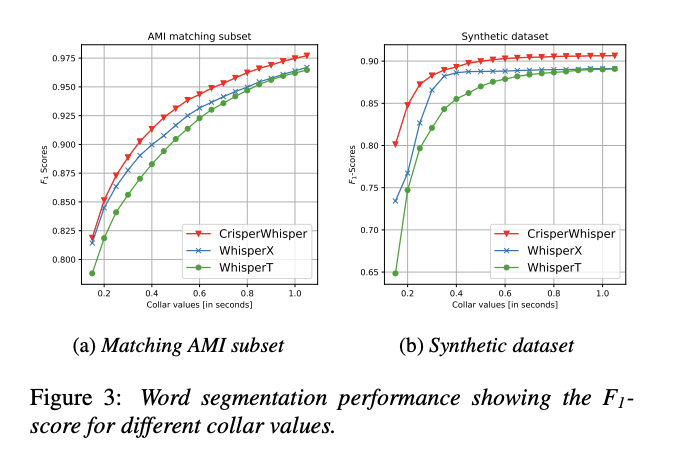
Производительность CrisperWhisper впечатляет по сравнению с предыдущими моделями. Она достигает F1-оценки 0,975 на синтетическом наборе данных и значительно превосходит WhisperX и WhisperT в устойчивости к шуму и точности сегментации слов. Например, CrisperWhisper достигает F1-оценки 0,90 на поднаборе дисфлюенций AMI, по сравнению с 0,85 у WhisperX. Модель также демонстрирует превосходную устойчивость к шуму, поддерживая высокие оценки mIoU и F1 даже в условиях соотношения сигнал/шум 1:5. В тестах на наборах данных вербатимного транскрибирования CrisperWhisper снизила коэффициент ошибок слов (WER) на корпусе совещаний AMI с 16,82% до 9,72% и на наборе данных TED-LIUM с 11,77% до 4,01%. Эти результаты подчеркивают способность модели предоставлять точные и надежные транскрипции, даже в сложных условиях.
В заключение, компания Nyra Health представила CrisperWhisper, которая решает проблемы точности временных меток и устойчивости к шуму. CrisperWhisper предоставляет надежное решение, улучшающее точность транскрибирования речи. Ее способность точно зафиксировать дисфлюенции и поддерживать высокую производительность в шумных условиях делает ее ценным инструментом для различных приложений, особенно в клинических условиях. Улучшения в коэффициенте ошибок слов и общей точности транскрибирования подчеркивают потенциал CrisperWhisper установить новый стандарт в технологии распознавания речи.
«`

























