Искусственный интеллект (ИИ) в современном мире
Искусственный интеллект (ИИ) значительно продвинулся благодаря разработке больших языковых моделей (LLM), которые следуют инструкциям пользователя. Эти модели стремятся предоставлять точные и актуальные ответы на запросы людей, часто требуя настройки для улучшения их производительности в различных приложениях, таких как обслуживание клиентов, поиск информации и генерация контента. Возможность точно инструктировать эти модели стала угловым камнем современного ИИ, расширяя границы того, что эти системы могут достичь в практических сценариях.
Преодоление проблемы длинной биаса
Одной из проблем при разработке и оценке моделей, следующих за инструкциями, является врожденный биас в сторону длины. Этот биас возникает потому, что человеческие оценщики и алгоритмы обучения предпочитают более длинные ответы, что приводит к созданию моделей, генерирующих излишне длинные выводы. Это предпочтение усложняет оценку качества и эффективности модели, поскольку более длинные ответы не всегда более информативны или точны. Следовательно, вызов состоит в разработке моделей, понимающих инструкции и обеспечивающих их способность генерировать ответы соответствующей длины.
Практические решения
Текущие методы для преодоления длинного биаса включают в себя внедрение штрафов за длину в оценочные бенчмарки. Например, AlpacaEval и MT-Bench внедрили эти штрафы, чтобы противодействовать тенденции моделей производить более длинные ответы. Кроме того, применяются различные методики настройки, такие как обучение с подкреплением с обратной связью от человека (RLHF), для оптимизации моделей с целью улучшения их способности следовать инструкциям. Эти методы направлены на улучшение способности моделей генерировать краткие, но полные ответы, сбалансировав длину и качество вывода.
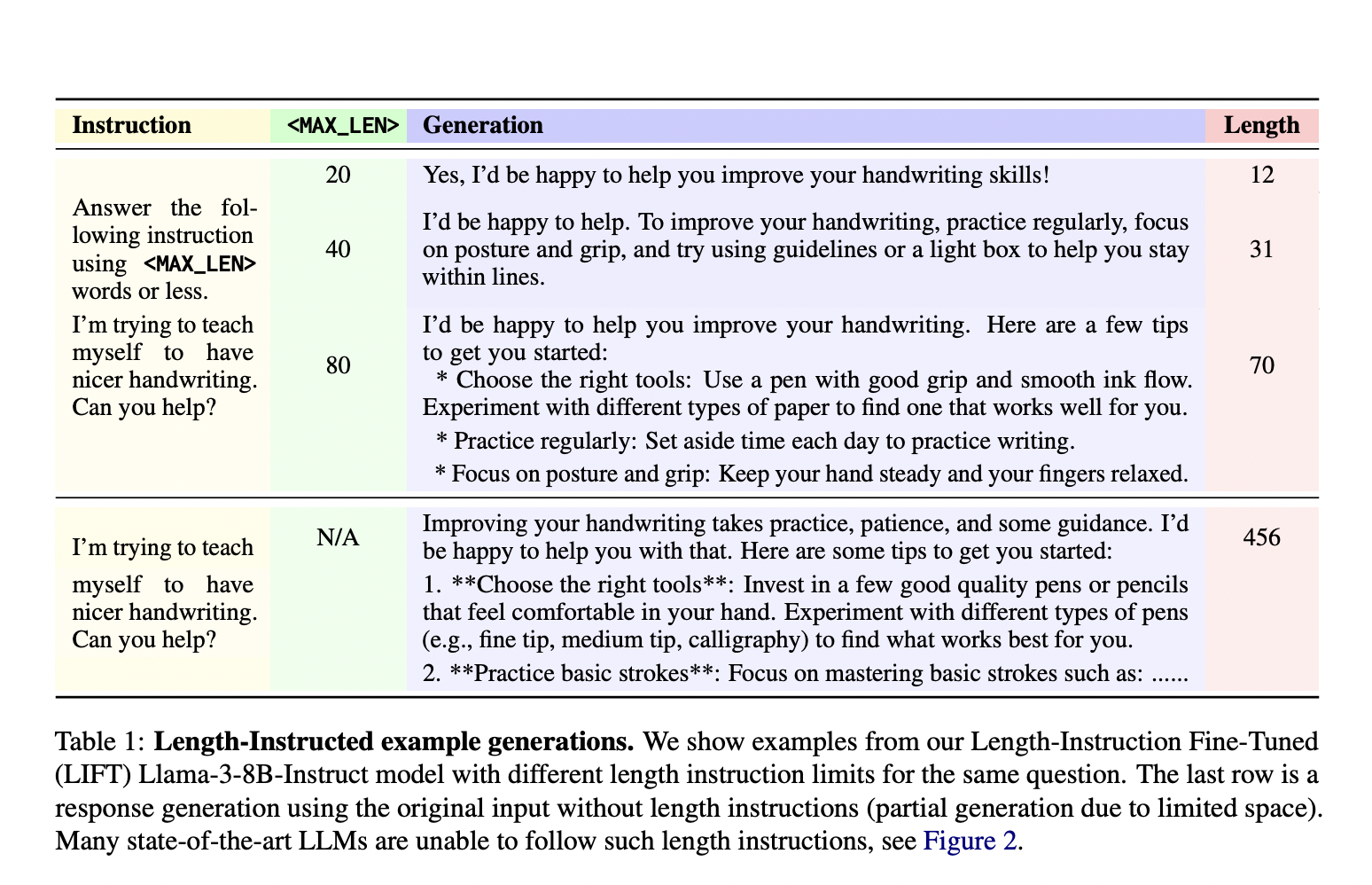
Исследователи из Meta FAIR и Нью-Йоркского университета представили новый подход под названием Length-Instruction Fine-Tuning (LIFT), который включает добавление инструкций по длине в обучающие данные. Этот метод позволяет контролировать модели во время вывода, чтобы они соответствовали указанным ограничениям длины. Команда исследователей, включая представителей Meta FAIR и Нью-Йоркского университета, разработала этот подход для устранения длинного биаса и улучшения соблюдения моделями инструкций по длине. Модели учатся уважать эти ограничения в реальных приложениях, интегрируя детальные инструкции в обучающие данные.
Метод LIFT включает в себя прямую оптимизацию предпочтений (DPO) для настройки моделей с использованием дополненных данных с инструкциями по длине. Этот процесс начинается с добавления обычного набора данных, следующего за инструкциями, путем вставки ограничений длины в подсказки. Метод формирует пары предпочтений, отражающие как ограничения длины, так и качество ответа. Эти дополненные наборы данных затем используются для настройки моделей, таких как Llama 2 и Llama 3, обеспечивая их способность обрабатывать запросы с и без инструкций по длине. Этот систематический подход позволяет моделям учиться на различных инструкциях, улучшая их способность генерировать точные и соответствующие по длине ответы.
Предложенные модели LIFT-DPO продемонстрировали превосходную производительность в соблюдении ограничений длины по сравнению с существующими передовыми моделями, такими как GPT-4 и Llama 3. Например, исследователи обнаружили, что модель GPT-4 Turbo нарушала ограничения длины почти в 50% случаев, выявляя значительный недостаток в ее конструкции. В отличие от этого, модели LIFT-DPO проявляли значительно более низкие уровни нарушений. В частности, модель Llama-2-70B-Base при стандартной настройке DPO показала уровень нарушений 65,8% на AlpacaEval-LI, который значительно снизился до 7,1% при настройке LIFT-DPO. Аналогично, уровень нарушений модели Llama-2-70B-Chat снизился с 15,1% при стандартной настройке DPO до 2,7% при использовании LIFT-DPO, демонстрируя эффективность метода в контроле длины ответа.
Более того, модели LIFT-DPO сохраняли высокое качество ответов, соблюдая ограничения длины. Уровни побед значительно улучшились, указывая на то, что модели могут генерировать высококачественные ответы в пределах указанных ограничений длины. Например, уровень побед для модели Llama-2-70B-Base увеличился с 4,6% при стандартной настройке DPO до 13,6% при использовании LIFT-DPO. Эти результаты подчеркивают успех метода в сбалансировании контроля длины и качества ответа, предоставляя надежное решение для оценки по длине.
Заключение
Исследование решает проблему длинного биаса в моделях, следующих за инструкциями, путем внедрения метода LIFT. Этот подход улучшает управляемость и качество ответов модели путем интеграции ограничений длины в процесс обучения. Результаты показывают, что модели LIFT-DPO превосходят традиционные методы, предоставляя более надежное и эффективное решение для следования инструкциям по длине. Сотрудничество между Meta FAIR и Нью-Йоркским университетом значительно улучшило разработку ИИ-моделей, способных генерировать краткие ответы высокого качества, устанавливая новый стандарт для возможностей следования инструкциям в исследованиях по ИИ.

























