Новые методы машинного обучения Google AI для создания дифференциально-частных синтетических данных
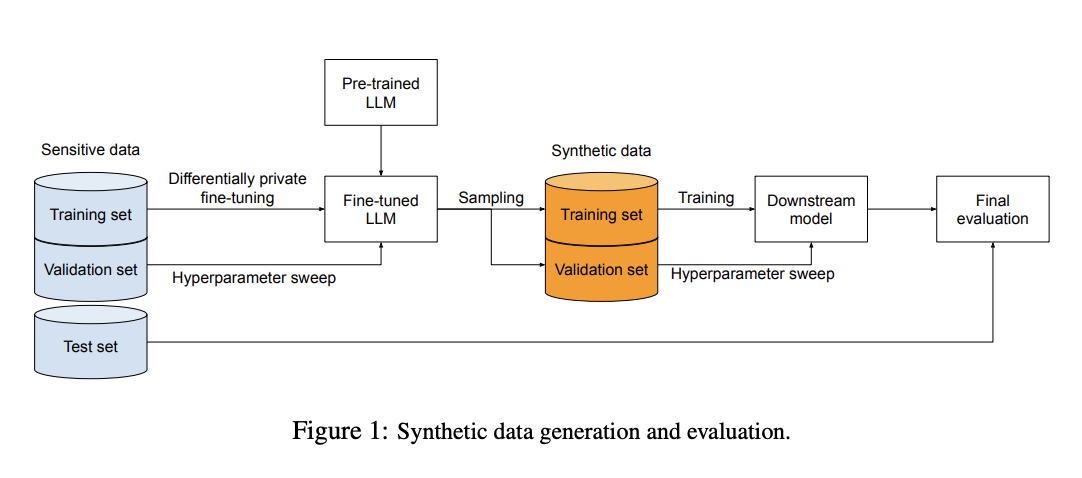
Исследователи Google AI описывают свой новый подход к созданию высококачественных синтетических наборов данных, сохраняющих конфиденциальность пользователей, что является необходимым для обучения прогностических моделей без компрометации чувствительной информации. Дифференциально-частные синтетические данные создаются путем формирования новых наборов данных, отражающих основные характеристики исходных данных, но полностью искусственных, что обеспечивает защиту конфиденциальности пользователей и одновременно обеспечивает надежное обучение моделей.
Практические решения и ценность
Новый метод Google AI позволяет генерировать дифференциально-частные синтетические данные, используя техники эффективной настройки параметров, такие как LoRa и prompt fine-tuning. Эти техники направлены на изменение меньшего количества параметров в процессе обучения, что снижает вычислительные затраты и потенциально улучшает качество синтетических данных.
Эмпирические результаты показали, что LoRa fine-tuning, модифицирующий примерно 20 миллионов параметров, превосходит другие методы настройки и позволяет обученным на синтетических данных классификаторам показать лучшую производительность.
Этот подход не только обеспечивает конфиденциальность, но и сохраняет высокую утилиту для обучения прогностических моделей, делая его ценным инструментом для организаций, стремящихся использовать чувствительные данные без ущерба для конфиденциальности пользователей.
Заключение
Подход Google к созданию дифференциально-частных синтетических данных с использованием эффективных техник настройки параметров превзошел существующие методы. Этот метод не только уменьшает вычислительные требования, но и улучшает качество синтетических данных. Эмпирические результаты демонстрируют эффективность предложенного метода, указывая на его потенциал для более широкого применения в машинном обучении, обеспечивающем конфиденциальность.

























