Оптимизация байтового представления для автоматического распознавания речи (ASR) и сравнение с представлением UTF-8
Энд-ту-энд (E2E) нейронные сети стали гибкими и точными моделями для многоязычного автоматического распознавания речи. Однако с увеличением количества поддерживаемых языков, особенно тех, у которых большие наборы символов, таких как китайский, японский и корейский (CJK), размер выходного слоя значительно увеличивается. Это отрицательно сказывается на вычислительных ресурсах, использовании памяти и размере актива. Исследователи сталкиваются с необходимостью поддержания эффективности и производительности модели, учитывая разнообразие языков и их соответствующих наборов символов в системах E2E ASR.
Практические решения и ценность
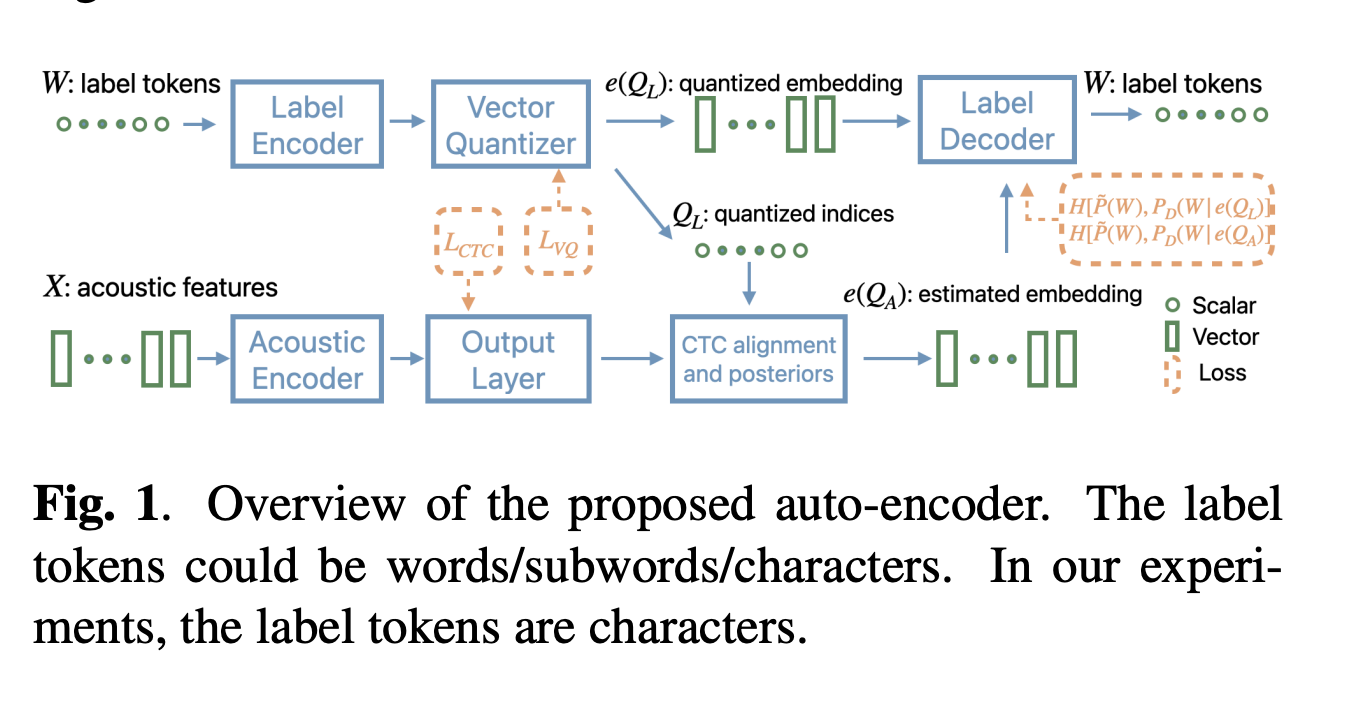
Предложенный метод формулирует проблему представления как задачу оптимизации с латентными переменными, используя архитектуру векторного квантового автоэнкодера (VQ-AE). Автоэнкодер оптимизируется с использованием функции потерь, включающей четыре термина: потери кросс-энтропии для кодировщиков меток и акустики, потери CTC для акустического кодировщика и потери квантования. Метод использует Residual VQ-VAE (RVQ-VAE) с двумя или тремя кодовыми книгами, каждая из которых содержит 256 вложений, позволяя представлять каждый токен метки 2-3 байтами. Для обработки потенциальных ошибок в последовательностях байтов система включает механизм коррекции ошибок через декодер меток. Этот декодер оценивает наиболее вероятную последовательность меток, оптимизируя точность даже при столкновении с недопустимыми последовательностями байтов. Предложенное представление на основе VQ предлагает преимущества по сравнению с UTF-8, включая кодирование фиксированной длины, задачно-специфическую оптимизацию и улучшенное восстановление ошибок.
Исследователи оценили предложенный метод представления на двуязычных английских и мандаринских задачах диктовки, сравнив его с представлениями на основе символов и UTF-8. Результаты показали, что представление на основе VQ последовательно превосходило представления на основе UTF-8 для различных размеров подслов. С подсловами 8000 метод на основе VQ достиг относительного снижения коэффициента ошибок слов в размере 5,8% для английского и 3,7% для мандаринского по сравнению с UTF-8. По сравнению с представлением на основе символов, как VQ, так и UTF-8 показали лучшие результаты на английском, сохраняя при этом схожую точность для мандаринского. Особенно следует отметить, что метод на основе VQ с 8000 подсловами продемонстрировал относительное снижение коэффициента ошибок в размере 14,8% для английского и 2,3% для мандаринского по сравнению с представлением на основе символов, подчеркивая его эффективность и гибкость в многоязычных системах ASR.
Данное исследование представляет собой надежный алгоритм для оптимизации байтового представления в ASR, предлагая альтернативу представлению UTF-8. Этот подход может быть оптимизирован с использованием аудио- и текстовых данных, с механизмом коррекции ошибок, предназначенным для повышения точности. Тестирование на английских и мандаринских наборах данных для диктовки показало относительное снижение коэффициента ошибок токенов в размере 5% по сравнению с методами, основанными на UTF-8. Хотя текущее исследование сосредоточено на двуязычном ASR, исследователи признают сложности разработки универсального представления для всех языков, такие как проблема обрушения индексов.

























