«`html
Развитие автономных агентов в искусственном интеллекте
Развитие автономных агентов, способных выполнять сложные задачи в различных средах, получило значительное внимание в исследованиях искусственного интеллекта. Эти агенты способны интерпретировать и выполнять инструкции на естественном языке в графических пользовательских интерфейсах (GUI), таких как веб-сайты, настольные операционные системы и мобильные устройства. Их способность беспрепятственно перемещаться и выполнять задачи в различных средах имеет важное значение для развития взаимодействия человека с компьютером, позволяя машинам обрабатывать все более сложные функции, охватывающие несколько платформ и систем.
Основные проблемы и практические решения
Одной из основных проблем в этой области является разработка надежных бенчмарков, способных точно оценивать производительность этих агентов в реальных сценариях. Традиционные бенчмарки часто не удовлетворяют этой потребности из-за ограничений, таких как узкое фокусирование на задачах в одной среде, зависимость от статических наборов данных и упрощенные методы оценки, которые не отражают динамическую природу реальных приложений. Например, существующие бенчмарки оценивают агентов на основе того, достигли ли они конечной цели, не учитывая пошагового прогресса во время задачи или несколько допустимых подходов, которые агент может выбрать. Это приводит к менее всесторонней оценке, которая может не точно отразить возможности агента.
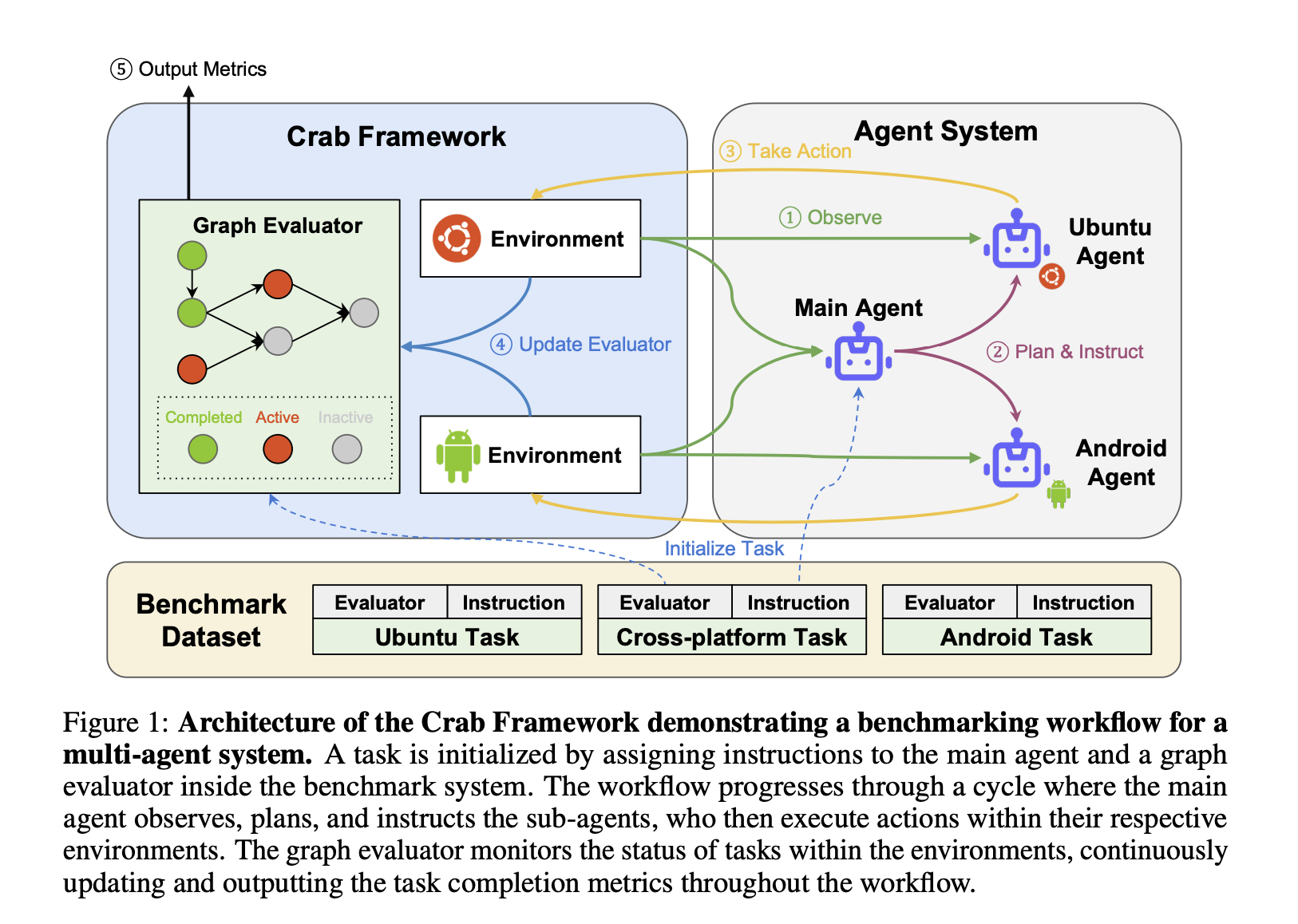
Исследователи из KAUST, Eigent.AI, UTokyo, CMU, Stanford, Harvard, Tsinghua, SUSTech и Oxford разработали Crab Framework, новый инструмент для оценки задач, охватывающих несколько сред. Этот фреймворк выделяется поддержкой функций, охватывающих несколько устройств и платформ, таких как настольные компьютеры и мобильные телефоны, а также включает графовый метод оценки, предлагающий более детальную и тонкую оценку производительности агента. В отличие от традиционных бенчмарков, Crab Framework позволяет одновременное функционирование агентов в различных средах, что делает его более отражающим сложности, с которыми сталкиваются агенты в реальных сценариях.
Crab Framework представляет инновационный подход к оценке задач путем разбиения сложных задач на более мелкие, управляемые подзадачи, каждая из которых представлена в виде узлов в направленном ациклическом графе (DAG). Эта структура на основе графов позволяет последовательное и параллельное выполнение подзадач, оцениваемых в нескольких точках, а не только в конце. Такой подход позволяет оценивать производительность агента на каждом шаге задачи, предоставляя более точное представление о том, насколько хорошо агент функционирует в различных средах. Гибкость этого метода также учитывает несколько допустимых путей выполнения задачи, обеспечивая более справедливую и всестороннюю оценку.
В Crab Benchmark-v0 исследователи реализовали набор из 100 реальных задач, охватывающих как задачи, связанные с несколькими средами, так и задачи в одной среде. Эти задачи разработаны для отражения обычных прикладных приложений, таких как управление календарями, отправка электронных писем, навигация по картам и взаимодействие с веб-браузерами и терминальными командами. Бенчмарк включает 29 задач для устройств на базе Android, 53 задачи для настольных компьютеров Ubuntu и 18 задач, требующих взаимодействия между обеими средами. Этот комплексный набор функций позволяет провести тщательную оценку того, насколько хорошо агенты могут функционировать на различных платформах, максимально приближаясь к реальным условиям.
Исследовательская группа протестировала Crab Framework с использованием четырех передовых мультимодальных языковых моделей (MLM): GPT-4o, GPT-4 Turbo, Claude 3 Opus и Gemini 1.5 Pro. Агенты были оценены в конфигурациях с одним агентом и несколькими агентами, протестировано девять различных настроек агента. Результаты показали, что наивысший коэффициент завершения задач в одиночной конфигурации с использованием модели GPT-4o составил 35,26%, что указывает на ее превосходную способность справляться с задачами в различных средах. В отличие от этого, другие модели и конфигурации показали различную эффективность, причем структуры с несколькими агентами в целом проявили себя немного хуже, чем установки с одним агентом. Введенные бенчмарком метрики производительности, такие как коэффициент завершения (CR), эффективность выполнения (EE) и экономичность выполнения (CE), успешно различали методы, выявляя сильные и слабые стороны каждой модели.
Фреймворк также предоставил понимание причин невыполнения задач, с категоризацией причин завершения как ложное завершение, достижение предела шагов и недопустимое действие. Например, структуры с несколькими агентами чаще производили недопустимые действия или неправильно завершали задачи из-за потенциальных проблем в коммуникации между агентами. Этот анализ подчеркнул важность улучшения протоколов коммуникации в системах с несколькими агентами для повышения их общей производительности.
В заключение, Crab Framework представляет детальный графовый метод оценки и поддерживает задачи, охватывающие несколько сред, предлагая более динамичную и точную оценку производительности агента. Тщательное тестирование бенчмарка с использованием передовых MLM, таких как GPT-4o и GPT-4 Turbo, предоставило ценные идеи о возможностях и проблемах текущих автономных агентов, проложив путь для будущих исследований и разработок в этой области. Способность фреймворка максимально отражать реальные условия делает его критическим инструментом для продвижения состояния исследований автономных агентов.
«`

























