«`html
Intel Labs представляет RAG Foundry: открытую платформу на Python для расширения больших языковых моделей (LLM) для задач RAG
Открытые библиотеки упростили создание конвейера RAG, но не обладали полными возможностями обучения и оценки. Предлагаемые фреймворки для LLM на основе RAG опускали важные компоненты обучения. Новые подходы, такие как рассмотрение использования LLM в качестве языка программирования, приводили к увеличению сложности. Методологии оценки с использованием синтетических данных и критиков LLM разработаны для оценки производительности RAG. Исследования рассматривали влияние механизмов извлечения на системы RAG. Параллельные фреймворки предлагали реализации RAG и наборы данных, но часто навязывали жесткие рабочие процессы. Intel Labs представляет RAG Foundry на основе этих достижений, обеспечивая гибкий, расширяемый фреймворк для разработки и экспериментов с системами RAG.
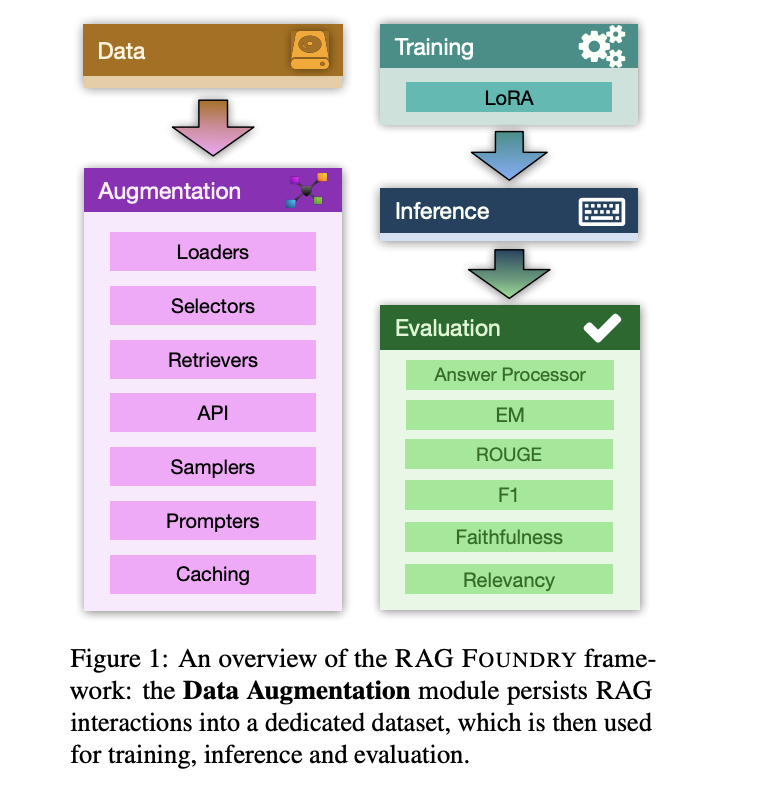
RAG Foundry – полноценное решение для задач, присущих системам Retrieval-Augmented Generation (RAG). Этот открытый фреймворк интегрирует создание данных, обучение, вывод и оценку в единую рабочую процедуру. Он позволяет быстро создавать прототипы, генерировать наборы данных и обучать модели, используя специализированные источники знаний. Модульная структура, управляемая конфигурационными файлами, обеспечивает совместимость между модулями и поддерживает изолированные эксперименты. Настраиваемый характер RAG Foundry способствует тщательным экспериментам по различным аспектам RAG, включая выбор данных, извлечение и создание запросов.
Исследователи выделяют несколько ключевых проблем в реализации и оценке систем Retrieval-Augmented Generation (RAG). Среди них сложность систем RAG, требующая глубокого понимания данных и тонких проектных решений. Сложности оценки возникают из-за необходимости оценки как точности извлечения, так и качества генерации. Проблемы воспроизводимости происходят из вариаций в обучающих данных и конфигурациях. Существующие фреймворки часто не поддерживают разнообразные варианты использования и опции настройки. Очевидна потребность в гибком фреймворке, позволяющем проводить полноценные эксперименты по всем аспектам RAG. RAG Foundry выступает в качестве решения этих проблем, предлагая настраиваемый и интегрированный подход.
Методология RAG Foundry использует модульный подход с четырьмя отдельными компонентами: создание данных, обучение, вывод и оценка. Создание данных включает выбор и подготовку соответствующих наборов данных для задач RAG. Обучение фокусируется на настройке LLM с использованием различных техник RAG. Вывод генерирует прогнозы на основе обработанных наборов данных. Оценка оценивает производительность модели с помощью локальных и глобальных метрик, включая Answer Processor для настраиваемой логики. Эксперименты проводились на задачах с интенсивным использованием знаний, таких как TriviaQA, ASQA и PubmedQA, чтобы проверить улучшения RAG. Анализ результатов сравнивал результаты на различных наборах данных, подчеркивая основные метрики, достоверность и оценки актуальности.
Эти наборы данных предлагают разнообразные сценарии вопросно-ответной деятельности, включая общие знания и биомедицинские области. Их выбор обусловлен сложностью и актуальностью задач, связанных с интенсивным использованием знаний, что позволяет провести всестороннюю оценку техник RAG. Такой подход подчеркивает важность многогранных метрик при оценке и демонстрирует эффективность фреймворка RAG Foundry в улучшении LLM для различных приложений RAG.
Эксперимент RAG Foundry оценил техники Retrieval-Augmented Generation на наборах данных TriviaQA, ASQA и PubmedQA, раскрывая разнообразные результаты производительности. Для TriviaQA интеграция извлеченного контекста и настройка RAG улучшили результаты, в то время как цепочечное мышление (CoT) ухудшило производительность. ASQA показал улучшения со всеми методами, особенно с настроенным CoT. Для PubmedQA большинство методов превзошли базовую производительность, а настроенный RAG продемонстрировал лучшие результаты. Следует отметить, что только конфигурации CoT обеспечивают оцениваемое рассуждение для бинарных ответов PubmedQA. Эти результаты подчеркивают зависимость эффективности техник RAG от набора данных и подчеркивают необходимость индивидуальных подходов к улучшению производительности модели в различных контекстах.
В заключение, исследователи представили открытую библиотеку, разработанную для улучшения больших языковых моделей для задач Retrieval-Augmented Generation. Фреймворк продемонстрировал свою эффективность через эксперименты с двумя моделями на трех наборах данных, используя полноценные метрики оценки. Модулярная структура RAG Foundry облегчает настройку и быстрые эксперименты в создании данных, обучении, выводе и оценке. Надежный процесс оценки включает как локальные, так и глобальные метрики, включая Answer Processor для настраиваемой логики. Показав потенциал техник RAG в улучшении производительности моделей, исследование также подчеркивает необходимость тщательной оценки и постоянных исследований для усовершенствования этих методов, позиционируя RAG Foundry как ценный инструмент для исследователей в этой развивающейся области.
Важно подчеркнуть, что данное исследование основано на работе исследователей данного проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему каналу в Telegram и группе в LinkedIn.
«`

























