«`html
Новое исследование: Data-Augmented Contrastive Tuning для борьбы с галлюцинациями объектов в мультимодальных языковых моделях
Недавнее исследование рассматривает критический вопрос в мультимодальных больших языковых моделях (MLLMs): явление галлюцинации объектов. Галлюцинация объектов происходит, когда эти модели генерируют описания объектов, которых нет во входных данных, что приводит к неточностям, подрывающим их надежность и эффективность. Например, модель может неправильно утверждать наличие «галстука» на изображении «свадебного торта» или неправильно идентифицировать объекты на сцене из-за выученных ассоциаций, а не фактических наблюдений. Эта проблема особенно актуальна, поскольку MLLMs все чаще применяются в приложениях, требующих высокой точности, таких как визуальное вопросно-ответное взаимодействие и подписи изображений.
Практические решения и ценность
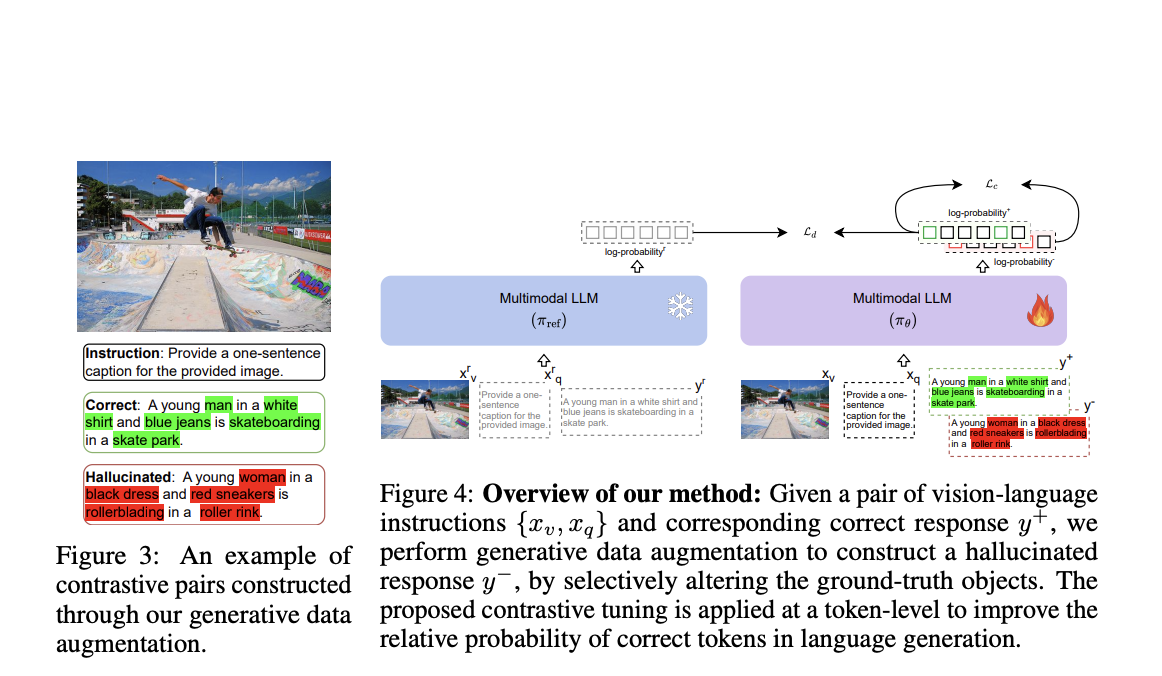
Для решения этой проблемы исследователи предлагают новый метод под названием Data-Augmented Contrastive Tuning (DACT). Этот подход основан на существующих фреймворках MLLM, но вводит более эффективный механизм для снижения уровня галлюцинаций без ущерба для общих возможностей модели. MLLMs, обученные с использованием этой методики, называются Hallucination Attenuated Language and Vision Assistant (HALVA).
Результаты показывают, что HALVA значительно снижает уровень галлюцинаций, сохраняя или даже улучшая общую производительность модели на общих задачах. Например, на бенчмарке AMBER варианты HALVA демонстрируют заметное снижение уровня галлюцинаций по сравнению с существующими методами тонкой настройки, такими как HA-DPO и EOS. Визуально-вопросно-ответные задачи также показывают, что HALVA превосходит базовую модель и другие методы тонкой настройки, достигая более высоких показателей F1 и демонстрируя свою эффективность в уменьшении галлюцинаций при сохранении общей точности.
В заключение, исследование представляет убедительное решение проблемы галлюцинации объектов в MLLMs через внедрение Data-Augmented Contrastive Tuning. Этот метод адресует значительное вызов в развертывании мультимодальных моделей, предлагая многообещающий путь для повышения надежности MLLMs и их более широкого применения в задачах, требующих точного визуального понимания и генерации языка.
«`

























