«`html
Speculative Retrieval Augmented Generation (Speculative RAG): Новая методика, повышающая точность и эффективность обработки запросов с большим объемом знаний при использовании LLM
Область обработки естественного языка сделала существенные шаги с появлением больших языковых моделей (LLM), которые проявили замечательную профессиональную компетентность в таких задачах, как вопросно-ответная система. Однако несмотря на их успех, LLM нуждаются в помощи при работе с запросами, требующими большого объема знаний. Эти запросы часто требуют актуальной информации или включают в себя малоизвестные факты, с которыми модель еще не сталкивалась во время обучения. Это ограничение может привести к фактическим неточностям или генерации вымышленного контента, особенно когда модель сталкивается с деталями вне своих запомненных знаний. Проблема становится еще более острой, когда точность и надежность имеют первостепенное значение, например, в медицинских или научных запросах.
Оптимизация баланса между точностью и эффективностью
Центральным вызовом в разработке и применении LLM является достижение оптимального баланса между точностью и эффективностью обработки. При ответе на сложные запросы, требующие интеграции информации из различных источников, LLM часто нуждаются в помощи в управлении длинными контекстами. По мере увеличения количества соответствующих документов возрастает сложность рассуждений, что может превзойти способность модели обрабатывать информацию эффективно. Эта неэффективность замедляет генерацию ответов и увеличивает вероятность ошибок, особенно в ситуациях, когда модель должна просматривать обширную контекстуальную информацию, чтобы найти наиболее релевантные детали. Таким образом, необходимость в системах, способных эффективно интегрировать внешние знания, снижая как задержку, так и риск неточностей, является критической областью исследований в области обработки естественного языка.
Новаторский подход к улучшению эффективности и точности
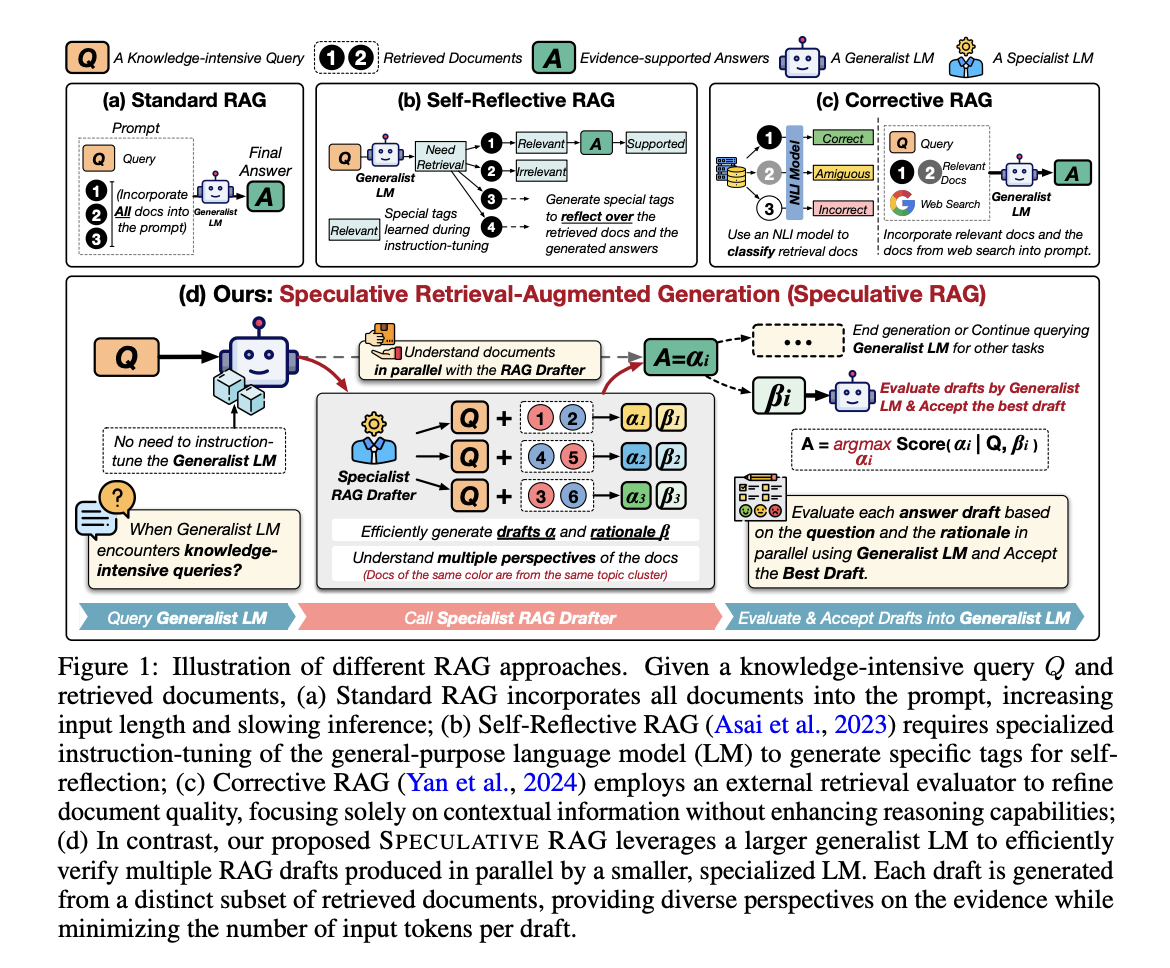
Исследователи из Университета Калифорнии в Сан-Диего, Google Cloud AI Research, Google DeepMind и Google Cloud AI представили новый подход под названием Speculative Retrieval Augmented Generation (Speculative RAG). Эта методика инновационно объединяет преимущества как специализированных, так и общих языковых моделей для повышения эффективности и точности генерации ответов. Основная идея заключается в том, чтобы использовать более маленькую, специализированную языковую модель, которая может параллельно генерировать несколько вариантов потенциальных ответов. Каждый вариант создается на основе отдельного подмножества документов, полученных в результате запроса, чтобы охватить различные точки зрения и уменьшить избыточность. После генерации этих вариантов вмешивается более крупная, общая языковая модель, чтобы их проверить. Общая языковая модель оценивает связность и релевантность каждого варианта, в конечном итоге выбирая наиболее точный для окончательного ответа. Этот метод эффективно сокращает количество токенов ввода для каждого варианта, улучшая процесс генерации ответов без ущерба точности.
Тестирование и результаты
Производительность Speculative RAG была тщательно протестирована по сравнению с традиционными методами RAG на различных бенчмарках, включая TriviaQA, PubHealth и ARC-Challenge. Результаты впечатляют: Speculative RAG повышает точность до 12,97% на бенчмарке PubHealth, сокращая задержку на 51%. На бенчмарке TriviaQA метод достиг улучшения точности на 2,15% и снижения задержки на 23,41%. На бенчмарке ARC-Challenge точность увеличилась на 2,14%, соответственно задержка уменьшилась на 26,73%. Эти цифры подчеркивают эффективность методики Speculative RAG в предоставлении высококачественных ответов более эффективно, чем у обычных систем RAG.
В заключение, Speculative RAG эффективно решает ограничения традиционных систем RAG, стратегически объединяя преимущества более маленьких, специализированных языковых моделей с большими, общими. Способность методики генерировать несколько вариантов параллельно, уменьшать избыточность и использовать разнообразные точки зрения обеспечивает точность и эффективность окончательного результата. Значительные улучшения в точности и задержке на различных бенчмарках подчеркивают потенциал методики Speculative RAG для установления новых стандартов в применении LLM для сложных запросов с большим объемом знаний. По мере развития обработки естественного языка подходы, подобные Speculative RAG, вероятно, будут играть ключевую роль в улучшении возможностей языковых моделей и их практического применения в различных областях.
«`

























