Улучшение Large Language Models через самокоррекцию с помощью обучения с подкреплением
Большие языковые модели (LLM) все чаще используются в областях, требующих сложного мышления, таких как решение математических задач и программирование. Эти модели могут генерировать точные результаты в нескольких областях. Однако важным аспектом их развития является способность к самокоррекции ошибок без внешнего воздействия, внутренняя самокоррекция.
Проблема и решение
Одной из основных проблем в улучшении LLM является их неспособность последовательно исправлять ошибки. Модели могут генерировать правильные ответы в отдельных частях, но им требуется помощь для исправления неправильных ответов при обнаружении ошибок. Для решения этой проблемы исследователи ищут методы, улучшающие производительность и надежность LLM в реальных приложениях.
Методика SCoRe
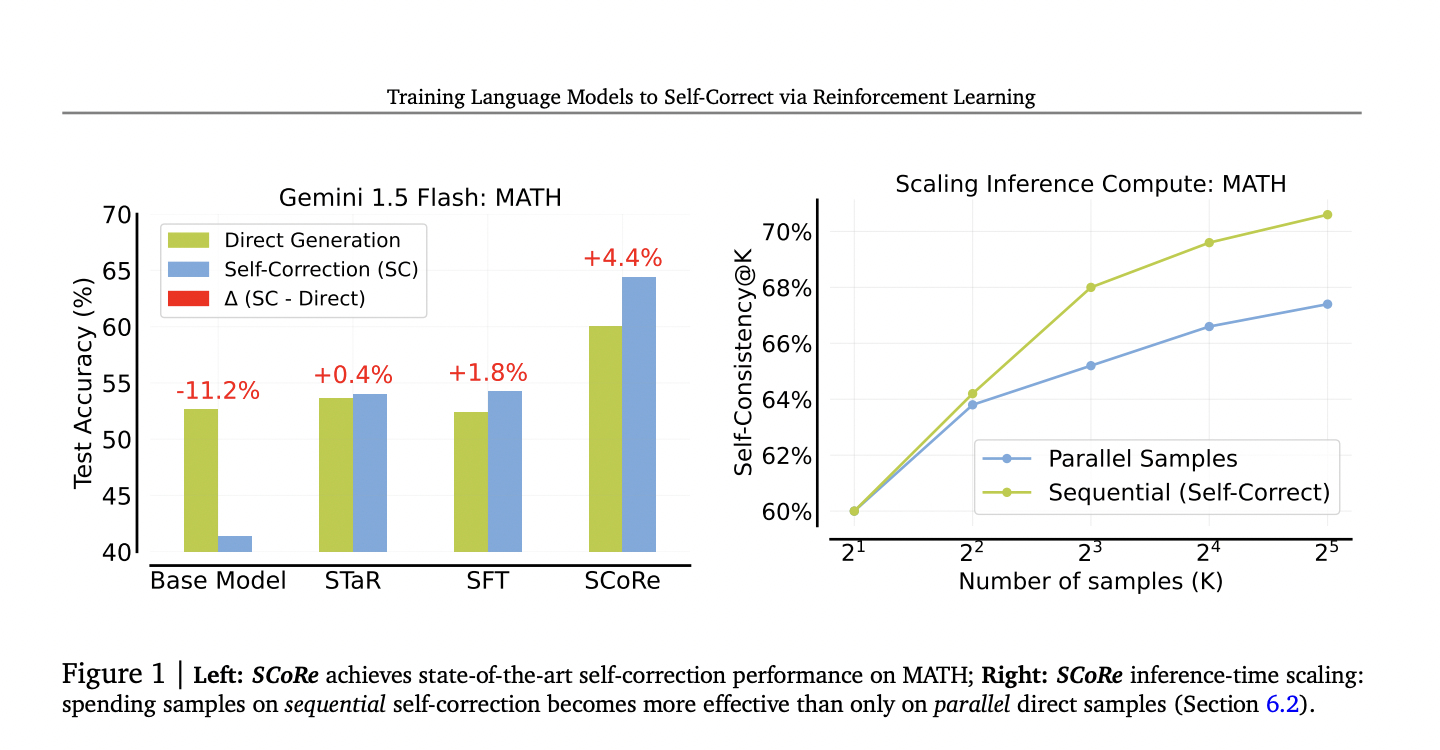
Исследователи из Google DeepMind представили новый подход под названием Self-Correction via Reinforcement Learning (SCoRe). Этот метод нацелен на обучение LLM улучшать свои ответы с использованием самогенерируемых данных, исключая необходимость во внешнем надзоре или моделях-подтверждения. SCoRe позволяет модели учиться на своих ответах и корректировать их в последующих итерациях, что существенно улучшает ее способность к самокоррекции.
Результаты метода SCoRe показывают значительное улучшение производительности самокоррекции LLM. Примененный к моделям Gemini 1.0 Pro и 1.5 Flash, SCoRe достиг 15,6% улучшения точности самокоррекции для математических задач и 9,1% для задач программирования. Эти результаты являются значительным прорывом по сравнению с традиционными методами обучения с учителем.

























