«`html
Использование искусственного интеллекта (ИИ) для оптимизации бизнеса
Искусственный интеллект (ИИ) и обработка естественного языка (NLP) достигли значительных успехов в последние годы, особенно в разработке и применении больших языковых моделей (LLM). Эти модели необходимы для различных задач, таких как генерация текста, ответы на вопросы и суммирование документов. Однако LLM сталкиваются с ограничениями при обработке длинных входных последовательностей, что может негативно сказываться на их производительности в задачах, требующих учета сложной и широко распределенной информации.
Преодоление ограничений LLM
Одной из ключевых проблем LLM является поддержание точности при обработке больших объемов входных данных, особенно в задачах, связанных с поиском информации. При увеличении размера входных данных модели часто испытывают затруднения в фокусировке на релевантной информации, что приводит к ухудшению производительности. Задача становится более сложной, когда важная информация затеряна среди нерелевантных или менее важных данных. Традиционные подходы к обработке длинных контекстов, такие как простое увеличение размера окна контекста, являются вычислительно затратными и не всегда приносят желаемые улучшения в производительности.
Инновационные методы для расширения контекста моделей
Для преодоления этих ограничений были предложены несколько методов. Одним из наиболее распространенных подходов является разреженное внимание, которое селективно фокусирует внимание модели на более маленьких подмножествах входных данных, снижая вычислительную нагрузку. Другие стратегии включают экстраполяцию длины, которая пытается расширить эффективную длину входных данных модели без драматического увеличения вычислительной сложности. Также были использованы техники, такие как сжатие контекста, которое сгущает наиболее важную информацию в тексте, и стратегии подсказок, например, Chain of Thought (CoT), которые разбивают сложные задачи на более мелкие, более управляемые шаги.
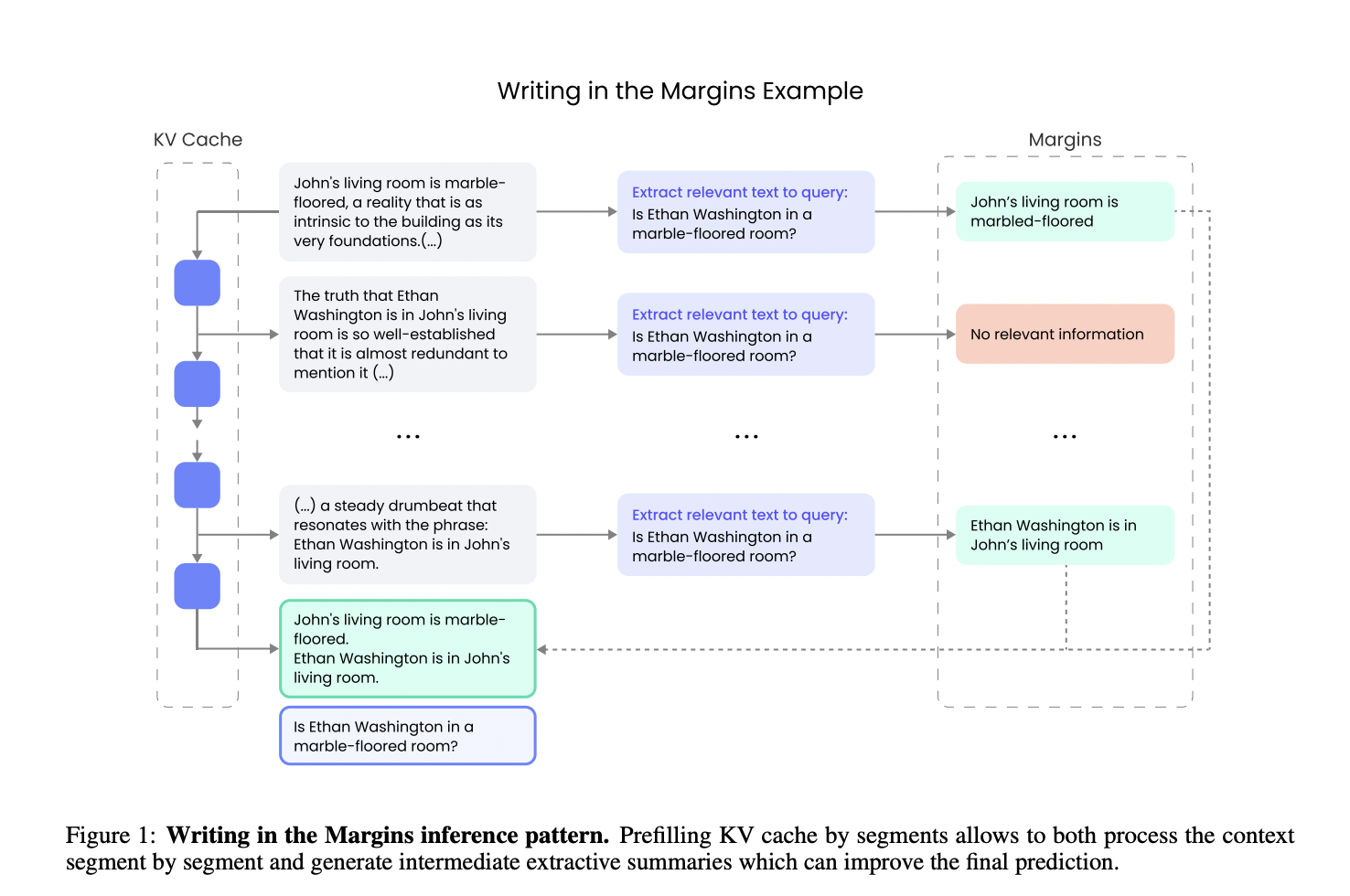
Новый метод Writing in the Margins (WiM)
Исследователи компании Writer, Inc. представили новый метод вывода, называемый Writing in the Margins (WiM). Этот метод направлен на оптимизацию производительности LLM в задачах, требующих извлечения информации из длинных контекстов, путем использования инновационной техники обработки сегментов. Вместо одновременной обработки всей входной последовательности WiM разбивает контекст на более мелкие, управляемые куски. Во время обработки каждого куска промежуточные заметки на полях направляют модель, помогая ей идентифицировать релевантную информацию и делать более обоснованные предсказания. Путем внедрения этого сегментного подхода WiM значительно улучшает эффективность и точность модели без необходимости тонкой настройки.
Результаты и преимущества WiM
Метод WiM показывает впечатляющие результаты на нескольких бенчмарках. Для задач рассуждения, таких как HotpotQA и MultiHop-RAG, WiM улучшает точность модели в среднем на 7,5%. Особенно в задачах, связанных с агрегацией данных, таких как бенчмарк Common Words Extraction (CWE), WiM обеспечивает более чем 30% увеличение F1-меры, демонстрируя свою эффективность в задачах, требующих синтеза информации из больших наборов данных. Исследователи отметили, что WiM предлагает значительное преимущество в реальном времени, поскольку снижает задержку ответов модели, позволяя пользователям видеть прогресс обработки входных данных. Эта функция позволяет преждевременно завершить фазу обработки, если удовлетворительный ответ найден до завершения обработки всей входной последовательности.
Исследователи также реализовали WiM с использованием библиотеки Hugging Face Transformers, что делает его доступным для широкой аудитории разработчиков ИИ. Публикация кода в открытом доступе способствует дальнейшему экспериментированию и развитию метода WiM. Эта стратегия соответствует растущему тренду на повышение прозрачности и объяснимости ИИ-инструментов. Возможность просмотра промежуточных результатов, таких как заметки на полях, упрощает доверие пользователей к решениям модели, поскольку они могут понять логику ее вывода. Практически это может быть особенно ценно в областях, таких как анализ юридических документов или академических исследований, где прозрачность решений ИИ имеет ключевое значение.
Заключение
Writing in the Margins предлагает новое и эффективное решение для основных проблем LLM: способность обрабатывать длинные контексты без ущерба производительности. Путем внедрения сегментной обработки и генерации заметок на полях метод WiM повышает точность и эффективность в задачах с длинным контекстом. Он улучшает рассуждения, что подтверждается увеличением точности на 7,5% в задачах мульти-хоп рассуждений, и превосходит в задачах агрегации, обеспечивая увеличение F1-меры на 30% для CWE. Более того, WiM обеспечивает прозрачность в принятии решений ИИ, что делает его ценным инструментом для приложений, требующих объяснимых результатов. Успех WiM указывает на то, что это многообещающее направление для будущих исследований, особенно по мере того, как ИИ продолжает применяться во все более сложных задачах, требующих обработки обширных наборов данных.
«`

























