“`html
Новая машинное обучение LLM-CI: оценка норм конфиденциальности, закодированных в LLMs
Большие языковые модели (LLM) широко используются в социотехнических системах, таких как здравоохранение и образование. Однако эти модели часто кодируют общественные нормы из данных, используемых во время обучения, что вызывает опасения относительно их соответствия ожиданиям конфиденциальности и этического поведения. Главная задача заключается в обеспечении соответствия этих моделей общественным нормам в различных контекстах, архитектурах моделей и наборах данных. Кроме того, чувствительность к запросу, при которой небольшие изменения во входных запросах приводят к различным ответам, усложняет оценку надежности кодирования этих норм LLMs. Решение этой проблемы критически важно для предотвращения этических проблем, таких как непреднамеренные нарушения конфиденциальности в чувствительных областях.
Оценка LLMs
Традиционные методы оценки LLMs фокусируются на технических возможностях, таких как связность и точность, пренебрегая кодированием общественных норм. Некоторые подходы пытаются оценить нормы конфиденциальности, используя конкретные запросы или наборы данных, но они часто не учитывают чувствительность к запросу, что приводит к ненадежным результатам. Кроме того, вариации гиперпараметров модели и стратегий оптимизации редко учитываются, что приводит к неполным оценкам поведения LLMs. Эти ограничения создают пробел в оценке этического соответствия LLMs общественным нормам.
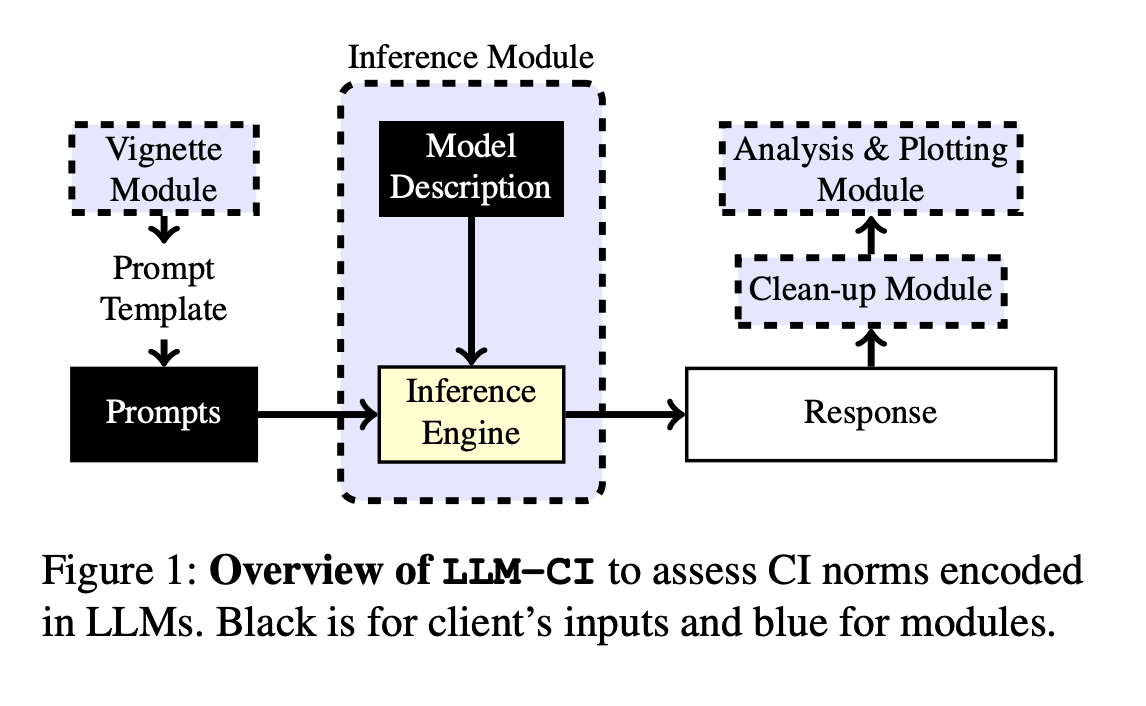
Метод LLM-CI
Команда исследователей из Университета Йорка и Университета Ватерлоо представляет LLM-CI, новую методику, основанную на теории Контекстуальной Целостности (CI), для оценки того, как LLMs кодируют нормы конфиденциальности в различных контекстах. Она использует стратегию множественных запросов для смягчения чувствительности к запросу, выбирая запросы, которые дают последовательные результаты в различных вариантах. Это обеспечивает более точную оценку соответствия нормам в различных моделях и наборах данных. Метод также включает реальные ситуационные образцы, представляющие конфиденциальные ситуации, обеспечивая тщательную оценку поведения модели в различных сценариях. Этот подход является значительным прорывом в оценке этической производительности LLMs, особенно в части конфиденциальности и общественных норм.
Результаты и преимущества
LLM-CI продемонстрировала значительное улучшение в оценке того, как LLMs кодируют нормы конфиденциальности в различных контекстах. Применение стратегии множественных запросов позволило достичь более последовательных и надежных результатов, чем при использовании одиночных запросов. Модели, оптимизированные с использованием стратегий выравнивания, показали до 92% контекстной точности в соблюдении норм конфиденциальности. Кроме того, новый метод оценки привел к увеличению согласованности ответов на 15%, подтверждая, что настройка свойств модели, таких как ее емкость, и применение стратегий выравнивания значительно улучшили способность LLMs соответствовать общественным ожиданиям. Это подтверждает надежность LLM-CI в оценке соответствия нормам.
LLM-CI предлагает всесторонний и надежный подход для оценки того, как LLMs кодируют нормы конфиденциальности с использованием методики множественных запросов. Он обеспечивает надежную оценку поведения модели в различных наборах данных и контекстах, решая проблему чувствительности к запросу. Этот метод значительно продвигает понимание того, насколько хорошо LLMs соответствуют общественным нормам, особенно в чувствительных областях, таких как конфиденциальность. Улучшая точность и последовательность ответов модели, LLM-CI представляет важный шаг к этическому применению LLMs в реальных приложениях.
“`









