Новый подход к синтезу речи на основе непрерывных токенов
В области больших языковых моделей (LLM) произошло значительное изменение в генерации текста, что побудило исследователей исследовать их потенциал в синтезе звука. Основной вызов заключается в адаптации этих моделей для задач преобразования текста в речь (TTS), сохраняя при этом высокое качество вывода. Текущие методологии, такие как нейронные кодек-модели языка, например VALL-E, сталкиваются с несколькими ограничениями. Это включает в себя более низкую достоверность по сравнению с мел-спектрограммами, проблемы устойчивости, происходящие от случайных стратегий выборки, и необходимость сложных двухпроходных процессов декодирования. Эти вызовы затрудняют эффективность и качество синтеза звука, особенно в задачах TTS с нулевой адаптацией, которые требуют многоязычных, многоголосых и многодоменных возможностей.
Практические решения и ценность
Для решения этих вызовов исследователи предприняли попытки в области синтеза речи. Традиционные методы включают конкатенативные системы, которые собирают аудиофрагменты, и параметрические системы, которые используют акустические параметры для синтеза речи. Энд-ту-энд нейронные TTS системы, такие как Tacotron, TransformerTTS и FastSpeech, упростили процесс, генерируя мел-спектрограммы непосредственно из текста.
Недавние достижения сосредотачиваются на возможностях TTS с нулевой адаптацией. Модели, такие как VALL-E, рассматривают TTS как условную языковую задачу, используя нейронные кодек-коды в качестве промежуточных представлений. VALL-E X расширила этот подход до многоголосных сценариев. Mega-TTS предложила разделение речевых атрибутов для более эффективного моделирования. Другие модели, такие как ELLA-V, RALL-E и VALL-E R, нацелены на улучшение устойчивости и стабильности.
Некоторые исследователи исследовали неавторегрессионные подходы для более быстрого вывода, такие как параллельная схема декодирования SoundStorm и модель диффузии StyleTTS 2. Однако эти методы часто сталкиваются с проблемами поддержания качества звука или эффективной обработки многоголосых, многоголосных сценариев.
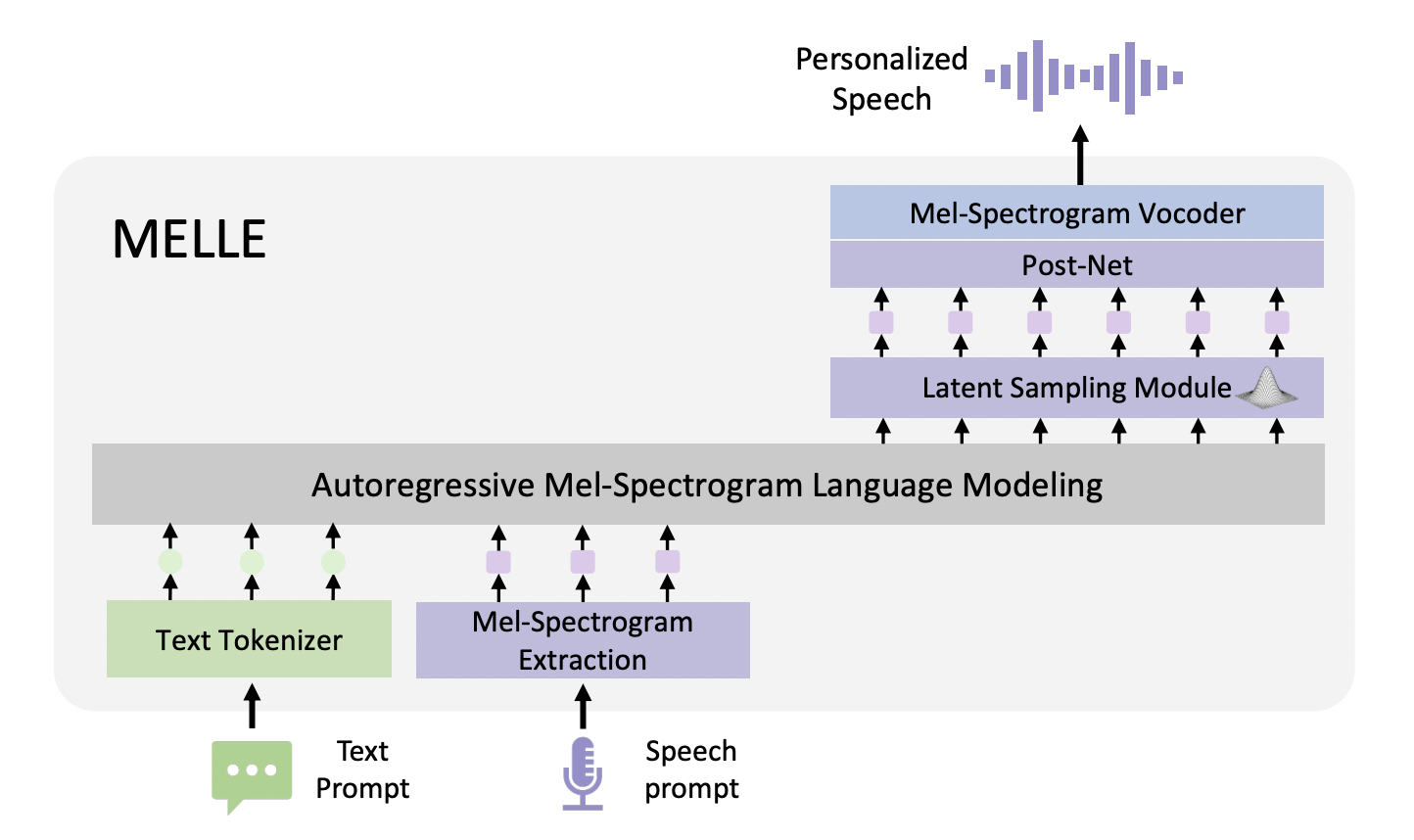
Исследователи из Китайского университета Гонконга и корпорации Microsoft представляют MELLE, уникальный подход к синтезу речи, использующий непрерывные токены на основе мел-спектрограмм. Этот метод направлен на преодоление ограничений дискретных кодек-кодов путем непосредственной генерации непрерывных кадров мел-спектрограмм из входного текста. Подход решает две ключевые проблемы: установление соответствующей целевой функции обучения для непрерывных представлений и обеспечение механизмов выборки в непрерывном пространстве.
Для решения этих вызовов MELLE использует функцию потерь регрессии с функцией потерь потока спектрограммы вместо потери перекрестной энтропии. Эта новая функция потерь помогает более эффективно моделировать вероятностное распределение непрерывных токенов. Кроме того, MELLE включает вариационное вывод для облегчения механизмов выборки, улучшая разнообразие вывода и устойчивость модели.
Модель работает как однопроходная система TTS с нулевой адаптацией, авторегрессивно предсказывая кадры мел-спектрограммы на основе предыдущих мел-спектрограмм и текстовых токенов. Этот подход направлен на устранение проблем устойчивости, связанных с выборкой дискретных кодек-кодов, что потенциально предлагает улучшенную достоверность и эффективность в синтезе речи.
Архитектура MELLE интегрирует несколько инновационных компонентов для эффективного синтеза речи из текста. Она использует слой встраивания, авторегрессивный декодер Transformer и уникальный модуль выборки латентных переменных, улучшающий разнообразие вывода. Модель включает слой предсказания остановки и пост-сеть свертки для улучшения спектрограммы. В отличие от нейронных кодек-моделей, MELLE не требует отдельной неавторегрессивной модели, что улучшает эффективность. Она может генерировать несколько кадров мел-спектрограммы за один шаг, дополнительно улучшая производительность. Архитектура завершается вокодером для преобразования мел-спектрограммы в волну, предлагая упрощенный, однопроходный подход, который потенциально превосходит предыдущие методы как по качеству, так и по эффективности.
MELLE демонстрирует превосходную производительность в задачах синтеза речи с нулевой адаптацией по сравнению с VALL-E и его вариантами. Она значительно превосходит базовый VALL-E по устойчивости и сходству диктора, достигая 47,9% относительного снижения WER-H в задаче продолжения и 64,4% снижения в задаче между предложениями. В то время как VALL-E 2 показывает сопоставимые результаты, MELLE проявляет лучшую устойчивость и сходство диктора в задаче продолжения, подчеркивая ее превосходную способность к контекстному обучению.
Производительность MELLE остается постоянно высокой даже с увеличенными коэффициентами снижения, что позволяет более быстрое обучение и вывод. Модель превосходит большинство последних работ как по устойчивости, так и по сходству диктора, даже с более крупными коэффициентами снижения. MELLE-limited, обученная на более малом корпусе, все равно превосходит VALL-E и его варианты, за исключением VALL-E 2. Использование множественной выборки с более крупным коэффициентом снижения может улучшить производительность, сокращая время вывода, как показывают результаты пятикратной выборки, демонстрирующие постоянно высокую устойчивость при различных настройках коэффициента снижения.
Это исследование представляет MELLE, представляющую значительный прогресс в синтезе речи с нулевой адаптацией, представляя подход к языковому моделированию на основе непрерывного акустического представления. Путем непосредственного предсказания мел-спектрограмм из текстового содержания и речевых подсказок он устраняет необходимость в дискретной векторной квантизации и двухпроходных процедурах, характерных для нейронных кодек-моделей языка, таких как VALL-E. Включение латентной выборки и функции потерь потока спектрограммы позволяет MELLE производить более разнообразные и устойчивые предсказания. Эффективность модели может быть дополнительно улучшена путем настройки коэффициента снижения для более быстрого декодирования. Особенно стоит отметить, что MELLE достигает результатов, сравнимых с человеческой производительностью в субъективной оценке, что является существенным шагом в области синтеза речи.









