EMOVA: Новая модель Omni-Modal LLM для безшовного интегрирования видения, языка и речи
Практические решения и ценность:
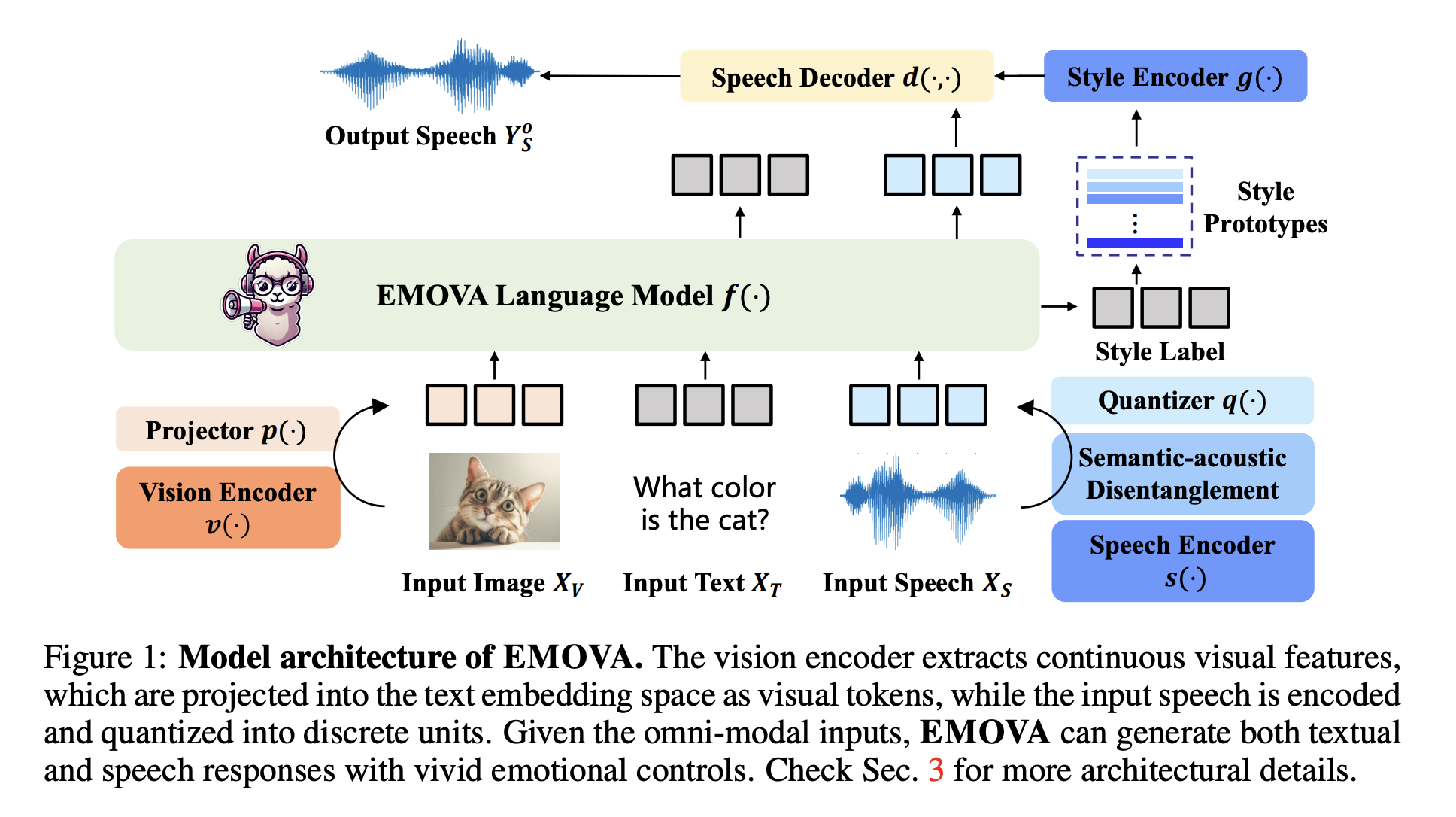
EMOVA представляет собой значительное достижение в исследованиях LLM, объединяя возможности видения, языка и речи. Модель обладает уникальной архитектурой, позволяющей выполнять обработку речи и визуальных входов end-to-end. Это позволяет генерировать речь с различными эмоциональными оттенками, что важно для систем реального времени.
EMOVA обеспечивает высокую точность на различных задачах, превосходя существующие модели. Модель способна поддерживать высокую точность как в задачах речи, так и в задачах видения одновременно, что редко встречается. Это делает EMOVA первой моделью LLM, способной поддерживать эмоционально насыщенные диалоги в реальном времени.
EMOVA закрывает важный разрыв в интеграции возможностей видения, языка и речи в одной модели ИИ. Благодаря инновационному разделению семантики и акустики и эффективной стратегии выравнивания мультимодальности, модель не только показывает выдающиеся результаты на стандартных бенчмарках, но и обеспечивает гибкость в управлении эмоциональной речью, что делает ее универсальным инструментом для продвинутого взаимодействия с ИИ.

























