Оптимизация предпочтений для увеличения разнообразия в языковых моделях
Большие языковые модели (LLMs) значительно продвинули область искусственного интеллекта, но у них есть ограничения в разнообразии ответов. Это особенно важно в творческих задачах, таких как генерация данных и рассказывание историй, где разнообразие выходов критично для поддержания интереса.
Проблемы с разнообразием ответов
Традиционные методы оптимизации предпочтений, такие как обучение с подкреплением на основе человеческой обратной связи (RLHF), часто приводят к повторяющимся ответам. Это ограничивает адаптивность моделей в креативных приложениях.
Решение: Оптимизация разнообразия предпочтений (DivPO)
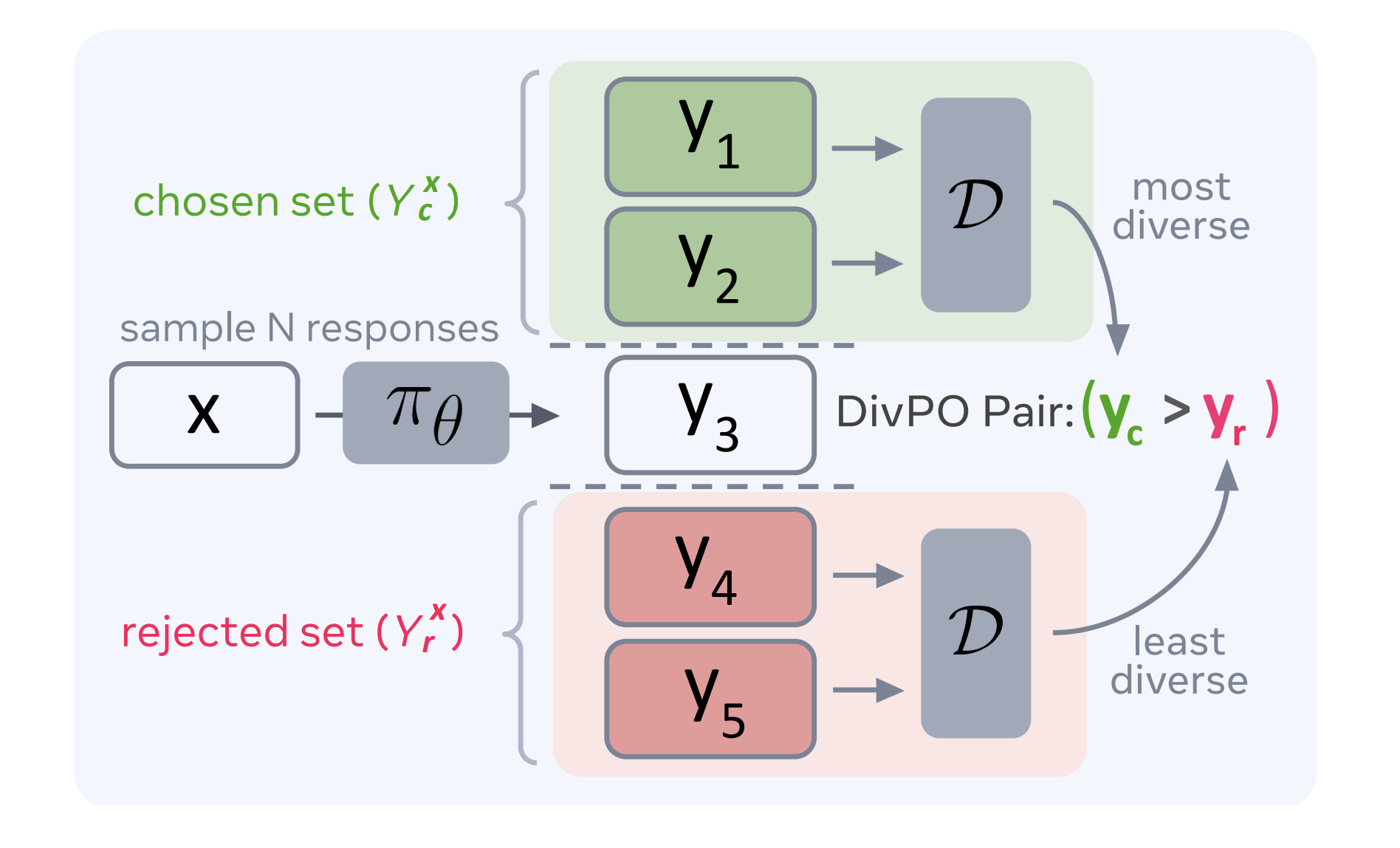
Исследователи из Meta, Нью-Йоркского университета и ETH Цюрих разработали новую технику под названием Оптимизация разнообразия предпочтений (DivPO). Она направлена на увеличение разнообразия ответов при сохранении их высокого качества.
Как работает DivPO?
DivPO выбирает не только самые высоко оцененные ответы, но и те, которые отличаются по качеству и разнообразию. Это позволяет моделям генерировать более разнообразные и качественные выходы.
Результаты экспериментов
Эксперименты показали, что DivPO увеличивает разнообразие на 45.6% в атрибутах персонажей и на 74.6% в историях, не снижая качество. Модели, обученные с использованием DivPO, показали лучшие результаты в оценках разнообразия.
Преимущества внедрения ИИ
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, рассмотрите следующие шаги:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Выберите подходящее решение из множества доступных вариантов ИИ.
- Внедряйте ИИ постепенно, начиная с небольших проектов.
- На основе полученных данных расширяйте автоматизацию.
Получите помощь в внедрении ИИ
Если вам нужны советы по внедрению ИИ, пишите нам. Попробуйте ИИ-ассистента в продажах, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Заключение
DivPO представляет собой значительный шаг вперед в оптимизации предпочтений, предлагая практическое решение проблемы недостатка разнообразия в языковых моделях. Это улучшает адаптивность и полезность LLM в различных областях, включая креативные и аналитические задачи.

























