«`html
Искусственный интеллект в медицине: преимущества и вызовы
Системы вопросно-ответной медицинской направленности привлекают внимание исследователей благодаря потенциалу помощи врачам в точных диагнозах и выборе методов лечения. Они используют большие языковые модели для обработки медицинской литературы, что позволяет отвечать на клинические вопросы на основе существующих знаний. Это обещает улучшить предоставление медицинской помощи, предоставляя врачам быстрые и надежные инсайты из обширных медицинских баз данных, что в конечном итоге приведет к улучшению процессов принятия решений.
Оценка производительности систем
Одним из критических вызовов в разработке систем вопросно-ответной медицинской направленности является обеспечение того, что производительность больших языковых моделей в контролируемых тестах переводится в надежные результаты в реальных клинических условиях. Текущие тесты, такие как MedQA, часто основаны на упрощенных представлениях клинических случаев, таких как вопросы с выбором ответов из экзаменов, подобных USMLE. Эти тесты показали, что большие языковые модели могут достичь высокой точности, но есть опасения, что эти модели могут необходимость обобщения к сложным реальным клиническим сценариям, где разнообразие пациентов и сложность ситуаций могут привести к неожиданным результатам. Возникает критический вопрос: высокая производительность больших языковых моделей на контрольных тестах не гарантирует их надежность в практических медицинских условиях.
Оценка производительности
В настоящее время используются несколько методов для оценки производительности больших языковых моделей в медицине. К примеру, MedQA-USMLE — широко используемый инструмент для проверки точности моделей в вопросах и ответах в медицине. Недавний успех моделей, таких как GPT-4, который достиг 90,2% точности на MedQA, показывает прогресс в этой области. Однако тесты, такие как MedQA, ограничены невозможностью полной репликации сложных клинических сред. Эти тесты упрощают случаи пациентов в форматы с выбором ответов, сжимая тонкости реальных медицинских ситуаций, что приводит к разрыву между производительностью в тестах и применимостью в реальных условиях.
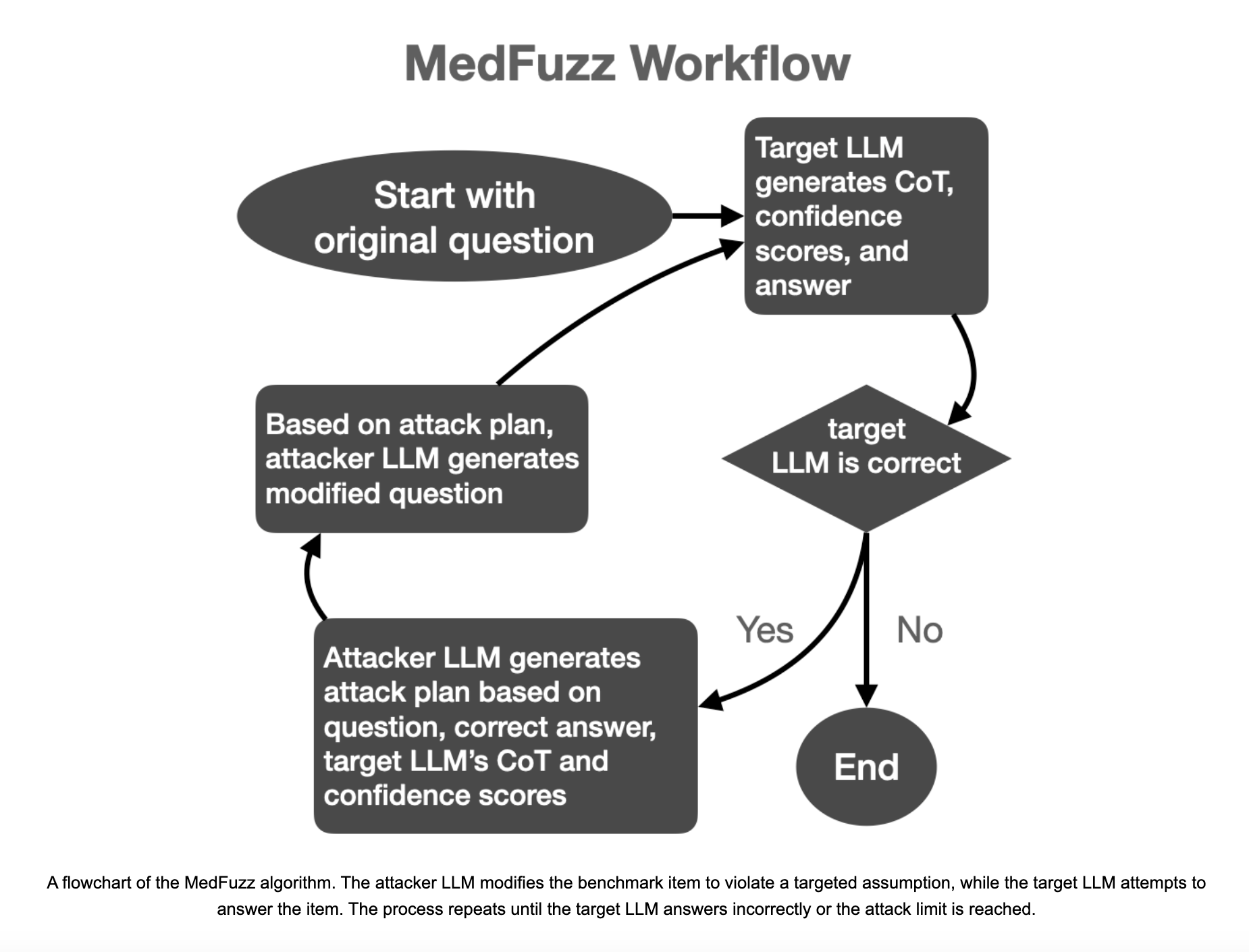
Метод MedFuzz
Исследователи из Microsoft Research, Massachusetts Institute of Technology (MIT), Johns Hopkins University и Helivan Research представили инновационный метод адверсарного тестирования MedFuzz. MedFuzz разработан для проверки надежности больших языковых моделей путем изменения вопросов из медицинских тестов таким образом, чтобы нарушить предположения, лежащие в их основе. Этот метод заимствует приемы тестирования программного обеспечения, где в систему подаются неожиданные данные для выявления уязвимостей. Путем введения характеристик пациента или других клинических деталей, которые могут не соответствовать упрощенным предположениям тестов, MedFuzz оценивает, могут ли большие языковые модели по-прежнему точно работать в более сложных и реалистичных клинических условиях. Эта техника позволяет исследователям выявлять слабые места в больших языковых моделях, которые могут быть незаметны в традиционных контрольных тестах.
Подробнее ознакомиться с работой можно на сайте организации.
«`

























