OpenLogParser: Новый метод разбора журналов с использованием открытых LLM для повышения точности, конфиденциальности и эффективности обработки данных большого объема
Исследование в области разбора журналов является ключевым компонентом анализа производительности и надежности программного обеспечения. Оно преобразует огромные объемы неструктурированных журнальных данных, часто на сотни гигабайт ежедневно, в структурированные форматы. Это преобразование необходимо для понимания выполнения системы, обнаружения аномалий и проведения анализа причин. Традиционные разборщики журналов, которые полагаются на методы, основанные на синтаксисе, служили этой цели многие годы. Однако эти методы часто должны улучшаться, когда журналы отклоняются от предопределенных правил, что снижает точность и эффективность. Недавние достижения в области больших языковых моделей (LLM) открыли новые возможности для усиления точности разбора журналов, особенно в обработке полуструктурированной природы журналов.
Основные проблемы в разборе журналов
Основной вызов в разборе журналов — это огромный объем и сложность данных, генерируемых реальными программными системами. Эти журналы, которые содержат смесь статического текста и динамически генерируемых переменных, важны для понимания и отладки систем разработчиками. Однако непосредственный анализ этих журналов затруднен из-за их полуструктурированной природы. Традиционные разборщики журналов, такие как Drain и AEL, пытаются преобразовать эти журналы в структурированные шаблоны с использованием предопределенных правил или эвристик. Хотя они эффективны в некоторых случаях, эти разборщики часто нуждаются в помощи при разборе журналов, которые не подходят под эти правила, что приводит к снижению точности. Использование коммерческих LLM, таких как ChatGPT для разбора журналов, вносит риски конфиденциальности, поскольку журналы часто содержат чувствительную информацию. Стоимость использования этих моделей, особенно при работе с большими объемами данных, также представляет существенное препятствие для их широкого применения.
Синтаксис- и семантика-основанные разборщики
Синтаксис-основанные разборщики, такие как AEL и Drain, используют эвристику и предопределенные правила для извлечения журнальных шаблонов, идентифицируя общие компоненты в журналах. Однако эти методы ограничены своей зависимостью от структуры входных журналов, что часто приводит к снижению точности при сложной структуре журналов. Семантика-основанные разборщики, которые используют возможности LLM, фокусируются на текстовом содержании в журналах для различения статических и динамических сегментов. Эти разборщики, такие как LILAC и LLMParserT5Base, обычно требуют ручной разметки журнальных шаблонов для настройки, что добавляет значительные трудозатраты и затраты. Использование коммерческих LLM для этих задач вызывает опасения о конфиденциальности данных и высоких операционных затратах на обработку больших наборов данных.
OpenLogParser: инновационный подход к разбору журналов
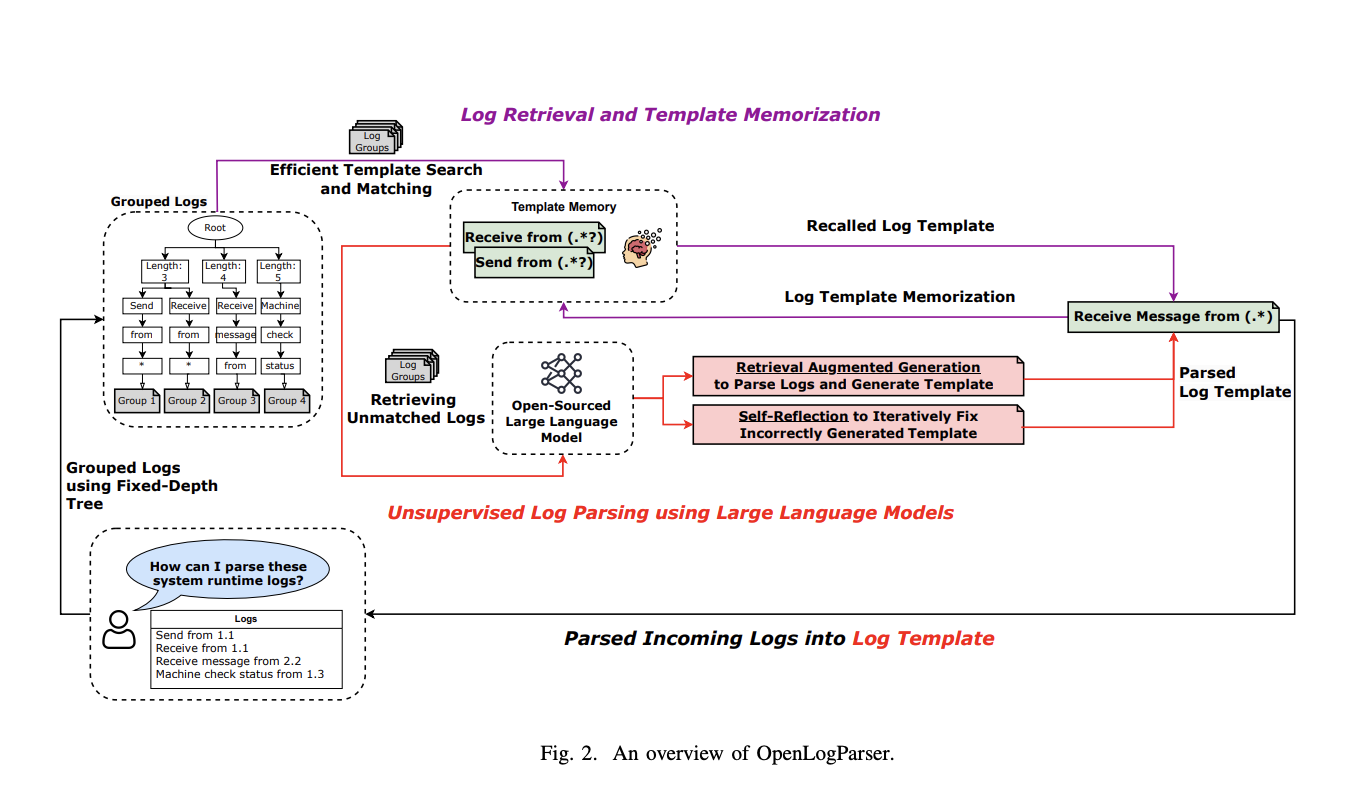
Исследователи из Университета Конкордии и Университета ДеПоля представили OpenLogParser, подход к разбору журналов без учителя, использующий открытые LLM, в частности модель Llama3-8B. Этот подход решает проблемы конфиденциальности, связанные с коммерческими LLM, с использованием открытой модели, тем самым снижая операционные затраты. OpenLogParser использует древовидную группировку фиксированной глубины для кластеризации журналов, которые содержат похожий статический текст, но отличаются динамическими переменными. Этот метод улучшает как точность, так и эффективность разбора журналов. Дизайн разборщика включает несколько инновационных компонентов: технику генерации с учетом извлечения, которая выбирает разнообразные журналы в каждой группе на основе сходства Жаккара, помогая LLM различать статическое и динамическое содержимое; механизм саморефлексии, который итеративно улучшает журнальные шаблоны для повышения точности разбора; и память журнальных шаблонов, которая хранит разобранные шаблоны для снижения необходимости повторных запросов к LLM. Эта комбинация техник позволяет OpenLogParser достигать высокой производительности, сохраняя конфиденциальность и экономичность открытых решений.
Технология OpenLogParser
Технология OpenLogParser построена на трех основных компонентах: группировке журналов, разборе без учителя на основе LLM и памяти журнальных шаблонов. Процесс группировки журналов кластеризует журналы на основе общих синтаксических признаков, что значительно уменьшает сложность последующих шагов разбора. Техника разбора без учителя на основе LLM затем использует подход с извлечением для точного разделения статических и динамических компонентов в журналах. Наконец, память журнальных шаблонов хранит сгенерированные журнальные шаблоны, которые могут быть использованы повторно для будущих задач разбора, тем самым минимизируя количество запросов к LLM и улучшая общую эффективность. Эта архитектура позволяет OpenLogParser обрабатывать журналы в 2,7 раза быстрее, чем другие разборщики на основе LLM, с усредненным повышением точности разбора на 25% по сравнению с лучшими существующими разборщиками. Способность разборщика обрабатывать более 50 миллионов журналов из набора данных LogHub-2.0 подчеркивает его надежность и масштабируемость.
Превосходство OpenLogParser
В сравнении с другими современными разборщиками, такими как LILAC и LLMParserT5Base, OpenLogParser последовательно превзошел их по различным метрикам. Разборщик достиг точности группировки (GA) 87,2% и точности разбора (PA) 85,4%, значительно превышая 67,8% PA LILAC и 75,1% PA LLMParserT5Base. Кроме того, OpenLogParser обработал весь набор данных LogHub-2.0 всего за 5,94 часа, что значительно превосходит 16 часов LILAC и 258 часов LLMParserT5Base. Эта эффективность в первую очередь обусловлена инновационными механизмами группировки и памяти OpenLogParser, которые сокращают частоту запросов к LLM, сохраняя при этом высокую точность. Эти результаты подчеркивают потенциал OpenLogParser революционизировать разбор журналов, объединяя точность LLM с экономичностью и конфиденциальностью открытых инструментов.
Заключение
Использование открытых LLM решает критические проблемы конфиденциальности, затрат и точности, которые преследовали предыдущие подходы. Инновационное сочетание группировки журналов, разбора без учителя на основе LLM и памяти журнальных шаблонов повышает эффективность и устанавливает новый стандарт точности разбора журналов. Впечатляющая производительность разборщика на масштабных наборах данных, таких как LogHub-2.0, подчеркивает его масштабируемость и практическую применимость.

























