«`html
Большие языковые модели (LLM) в области обработки естественного языка (NLP)
Большие языковые модели (LLM) сделали существенный прогресс в области обработки естественного языка (NLP). Путем увеличения количества параметров модели LLM показывают более высокую производительность в задачах, таких как генерация кода и ответы на вопросы. Однако большинство современных LLM, такие как Mistral, Gemma и Llama, являются плотными моделями, что означает, что во время вывода они используют каждый параметр. Несмотря на силу этой плотной архитектуры, требуется много вычислительной мощности, что затрудняет создание доступного и широко доступного ИИ.
Условные вычисления
Условные вычисления были изучены как решение для повышения эффективности. Путем включения только некоторых нейронов модели в ответ на вход, эта техника сокращает бесполезные вычисления. Условные вычисления могут быть реализованы с помощью двух основных методов. Первый метод — это стратегия Mixture-of-Experts (MoE). Предопределяя ограничения структуры модели перед обучением, такие как определение количества экспертов для активации для конкретного ввода, MoE вводит условные вычисления. Эта техника маршрутизации экспертов повышает эффективность путем выборочной активации конкретных компонентов модели без увеличения вычислительной сложности.
Новые методы активации
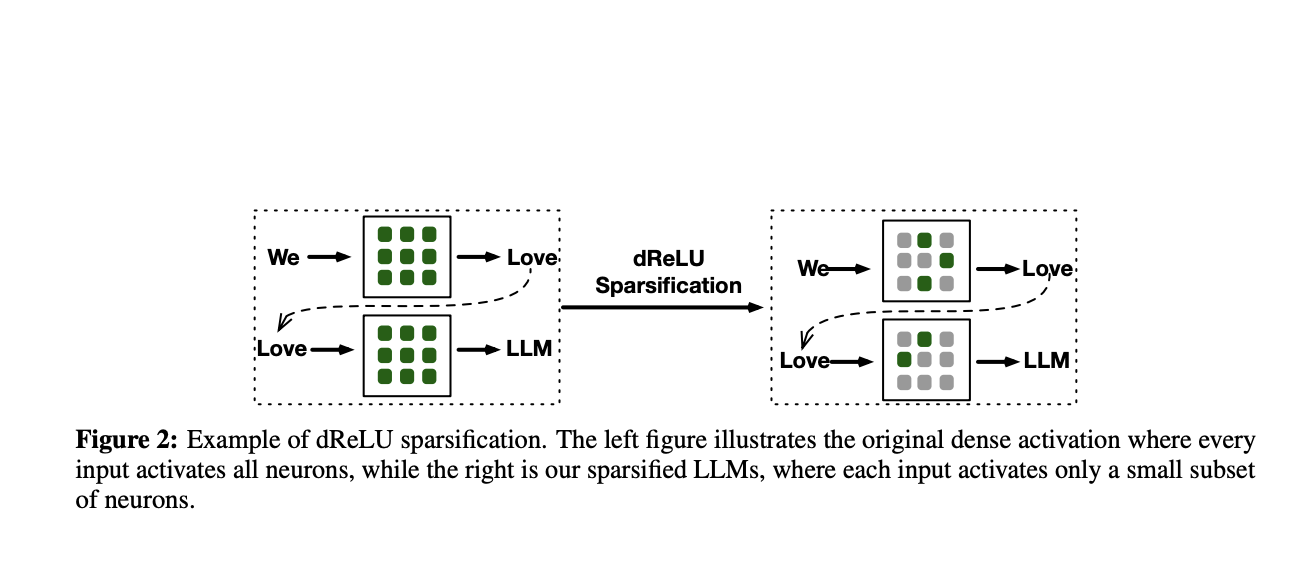
Второй метод использует функции активации, такие как внутренняя разреженность ReLU. Для не положительных входов ReLU интринсеки создает ноль, что приводит к множеству неактивных нейронов, не вносящих вклад в вычисления. Эта внутренняя разреженность может повысить эффективность вывода.
Новая функция активации dReLU
Команда исследователей из Китая предложила новую функцию активации dReLU, которая решает проблемы негативных активаций в компоненте GLU. Тесты на масштабных LLM, предварительно обученных с применением dReLU в дополнение к SwiGLU, показали, что модели с dReLU проявляют производительность на уровне моделей SwiGLU, при этом уровень разреженности достигает 90%. Команда улучшила процесс ReLUfication, собрав гетерогенные данные предварительного обучения из других источников, таких как код, веб-сайты и математические наборы данных.
Применение в практике
Применение этих методов к моделям Mistral-7B и Mixtral-47B подтвердило их эффективность. Результаты показали, что модели TurboSparse-Mixtral-47B и TurboSparse-Mistral-7B не только сравнимы с оригинальными версиями, но часто превосходят их. Объединение этих моделей с PowerInfer продемонстрировало среднее ускорение в задачах генерации в 2,83 раза, подтверждая эффективность предложенного подхода в увеличении производительности.
Основные выводы
Введена функция dReLU, которая повышает разреженность активации. Объявлено о выпуске моделей TurboSparse-Mistral7B и TurboSparse-Mixtral-47B, которые демонстрируют превосходную производительность по сравнению с их оригинальными плотными версиями. Оценка показала, что с помощью этих моделей можно достичь ускорения вывода от 2 до 5 раз. С помощью TurboSparse-Mixtral-47B можно выполнять до 10 токенов без необходимости использования GPU.
«`

























