Together AI представляет TEAL: революционный метод активации сжатия без обучения для оптимизации крупных языковых моделей с улучшенной эффективностью и минимальным ухудшением в ресурсо-ограниченных средах
Together AI представила новую методику под названием TEAL (Training-Free Activation Sparsity in LLMs), которая имеет потенциал значительно продвинуть область эффективного вывода моделей машинного обучения. Компания, являющаяся лидером в области открытых моделей искусственного интеллекта, исследует инновационные способы оптимизации производительности моделей, особенно в условиях ограниченных ресурсов памяти. TEAL представляет собой значительный шаг в этом направлении, предлагая новый метод сжатия активации в LLMs, обещающий улучшенную производительность с минимальным ухудшением модели.
Проблема в крупных языковых моделях
Крупные языковые модели (LLMs) известны своими впечатляющими возможностями, но печально известны своими огромными требованиями к памяти. Традиционные процессы вывода в этих моделях замедляются скоростью передачи данных между памятью и вычислительными устройствами. Эта память-зависимая природа привела к разработке нескольких техник, таких как квантизация и сжатие весов, для уменьшения размеров моделей без ущерба производительности.
Одним из более недавних достижений является сжатие активации, которое использует определенные избыточные скрытые состояния в LLMs, позволяя обрезать ненужные весовые каналы. Однако модели, такие как LLaMA, перешли от использования MLP на основе ReLU (естественно обладающих высокой разреженностью) к MLP на основе SwiGLU, которые менее подходят для сжатия активации. Это затруднило успешное применение техник сжатия активации в новых моделях.
Концепция TEAL
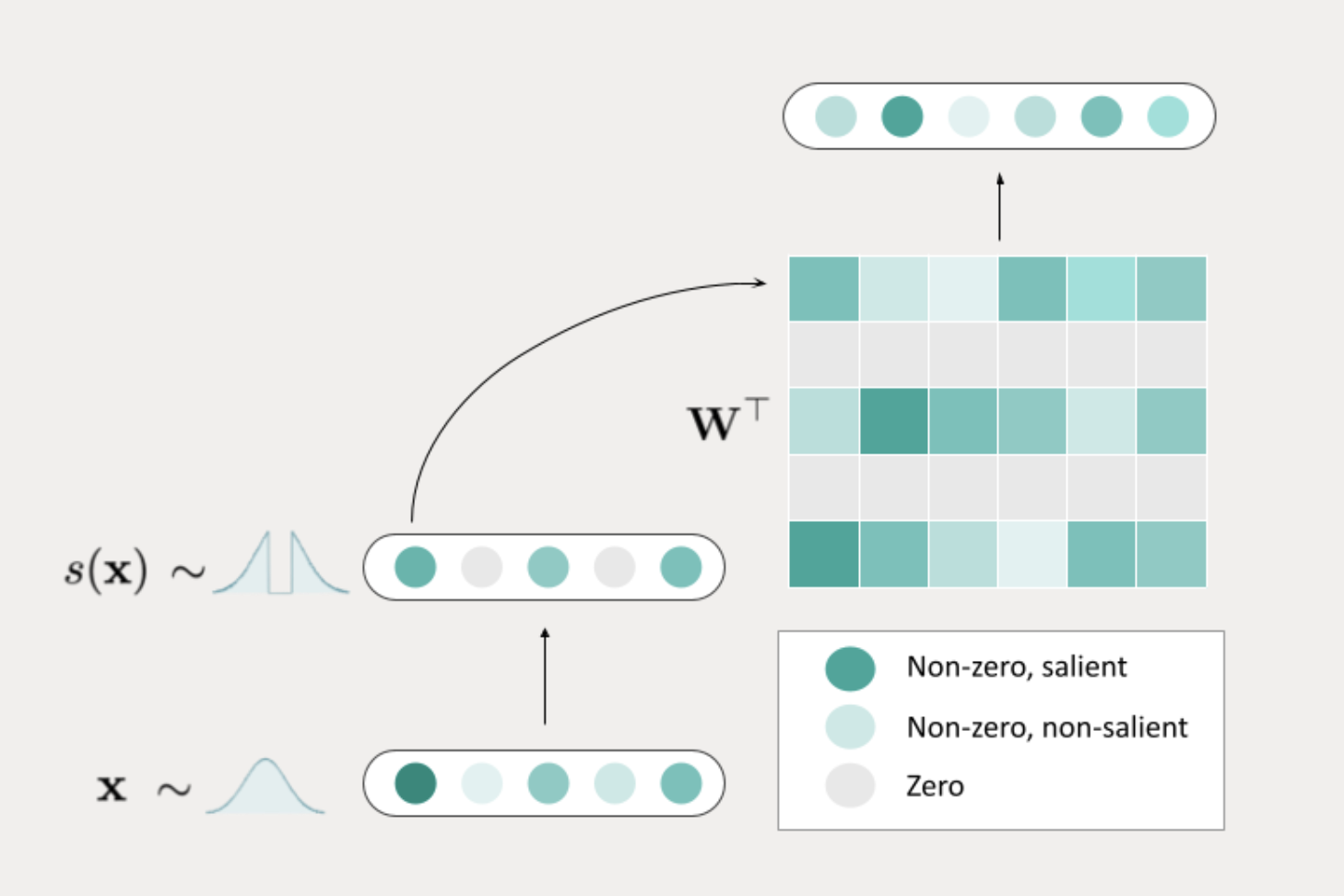
TEAL появляется как решение проблем, вызванных сжатием активации в современных LLMs. Он представляет собой простой, не требующий обучения подход, который осуществляет сжатие активации путем применения обрезки по величине к скрытым состояниям во всей модели. Этот подход позволяет достичь впечатляющей разреженности активации на уровне всей модели в размере 40-50% с минимальным влиянием на производительность.
Основное преимущество TEAL заключается в его способности оптимизировать разреженность по всем тензорам в модели. В отличие от предыдущих методов, таких как CATS, которые разреживали только определенные области модели, TEAL нацеливает каждый тензор, достигая более высокой общей разреженности без необходимости дополнительной настройки или предварительного обучения. TEAL значительно снижает пропускную способность памяти, необходимую для вывода LLM, избегая передачи в память весовых каналов со значением ноль, что приводит к ускорению времени обработки.
Техническая реализация TEAL
Реализация TEAL фокусируется на оптимизации разреженности на уровне блока трансформатора, обеспечивая выгоду от сжатия для каждого тензора в модели. При разреженности 25% модель почти не теряет производительность, а при разреженности 40-50% ухудшение остается минимальным. Это в отличие от других методов, таких как CATS, которые испытывают более значительное снижение производительности при более высоких уровнях разреженности. Одним из ключевых факторов успеха TEAL является его подход к разреживанию матриц весов. TEAL разреживает матрицы весов, а не через выходы с затворами, как в других методах. Этот выбор дизайна приводит к более низким показателям ошибок и лучшей общей производительности, даже при более высоких уровнях разреженности. В результате TEAL может достигать ускорений от 1,53x до 1,8x при декодировании одного пакета, что является значительным улучшением для прикладных задач, где скорость вывода критична.
Совместимость с аппаратным обеспечением и квантизацией
Помимо преимуществ разреженности активации, TEAL также совместим с квантизацией, еще одной ключевой техникой для уменьшения размера и улучшения эффективности LLM. Квантизация уменьшает точность параметров модели, снижая требования к памяти и вычислительным ресурсам для вывода. Подход TEAL к разреженности дополняет методы квантизации, позволяя моделям достигать еще больших ускорений при сохранении производительности. Интеграция TEAL с GPT-Fast от Together AI, а также поддержка CUDA Graphs и Torch Compile, дополнительно улучшили его аппаратную эффективность. TEAL хорошо работает на GPU, включая A100, что позволяет превзойти традиционные плотные ядра в определенных сценариях. Это делает его привлекательным вариантом для сред с ограниченными аппаратными ресурсами, особенно при выполнении задач вывода с небольшими пакетами.
Приложения и потенциал в будущем
Наиболее непосредственное применение TEAL ускоряет вывод в ресурсо-ограниченных средах, таких как устройства на краю с ограниченной памятью и вычислительной мощностью. Способность TEAL оптимизировать использование памяти и снижать задержку при выводе LLM делает его идеальным решением в этих сценариях. Он отлично справляется с выводом при небольших пакетах, где может обеспечить наибольшие ускорения. TEAL также обладает потенциалом для поставщиков вывода, управляющих большими парками GPU и моделей. Together AI, которая предлагает более 100 ведущих открытых моделей, хорошо позиционирована для использования улучшений производительности TEAL. TEAL позволяет эффективнее обслуживать эти модели, уменьшая объем памяти и улучшая скорость обработки, даже при относительно небольших размерах активных пакетов.
Заключение
Выпуск TEAL от Together AI является значительным шагом в оптимизации LLM. TEAL предлагает простое и эффективное решение для проблем с памятью, которые давно преследовали вывод LLM, представляя подход без обучения к сжатию активации. Его способность достигать разреженности на уровне всей модели с минимальным ухудшением и его совместимость с квантизацией делают его мощным инструментом для улучшения эффективности моделей машинного обучения в ресурсо-ограниченных средах и масштабных сценариях вывода.

























