«`html
Img-Diff: Новый набор данных для улучшения мультимодельных языковых моделей через контрастное обучение и анализ различий изображений
Мультимодельные языковые модели (MLLMs) развиваются, чтобы улучшить взаимодействие текста и изображений с помощью различных техник. Модели, такие как Flamingo, IDEFICS, BLIP-2 и Qwen-VL, используют обучаемые запросы, в то время как LLaVA и MGM используют интерфейсы на основе проекций. LLaMA-Adapter и LaVIN фокусируются на эффективную настройку параметров. Качество набора данных значительно влияет на эффективность MLLM, и недавние исследования улучшают настройку визуальных инструкций, чтобы повысить производительность в задачах вопросов и ответов. Высококачественные наборы данных для тонкой настройки с обширным разнообразием задач были использованы для превосходства в восприятии изображений, рассуждениях и задачах OCR.
Практические решения и ценность:
Мультимодельные языковые модели (MLLMs) развиваются, чтобы улучшить взаимодействие текста и изображений с помощью различных техник. Модели, такие как Flamingo, IDEFICS, BLIP-2 и Qwen-VL, используют обучаемые запросы, в то время как LLaVA и MGM используют интерфейсы на основе проекций. LLaMA-Adapter и LaVIN фокусируются на эффективную настройку параметров. Качество набора данных значительно влияет на эффективность MLLM, и недавние исследования улучшают настройку визуальных инструкций, чтобы повысить производительность в задачах вопросов и ответов. Высококачественные наборы данных для тонкой настройки с обширным разнообразием задач были использованы для превосходства в восприятии изображений, рассуждениях и задачах OCR.
Набор данных Img-Diff представляет новый подход, акцентируя анализ различий изображений, что демонстрирует эмпирическую эффективность в улучшении профессионализма MLLMs в VQA и возможностях локализации объектов. Этот подход выделяет Img-Diff среди существующих наборов данных и продолжает работы в данной области. Предыдущие методы, такие как Shikra, ASM и PINK, использовали значительные объемы данных обнаружения объектов для улучшения возможностей локализации MLLM, заложив основы для инновационного подхода Img-Diff к тонкому распознаванию и анализу изображений.
Статья представляет набор данных Img-Diff, разработанный для улучшения возможностей тонкого распознавания изображений MLLM путем фокусировки на различиях объектов между похожими изображениями. Используя генератор различий областей и генератор различий подписей, набор данных вызывает MLLM для идентификации совпадающих и различных компонентов. Модели, настроенные с помощью Img-Diff, превосходят современные модели на различных задачах различий изображений и VQA. Исследование подчеркивает важность высококачественных данных и развивающихся архитектур моделей в улучшении производительности MLLM. Оно рассматривает существующие подходы, такие как обучаемые запросы и интерфейсы на основе проекций, подчеркивая необходимость лучших наборов данных для решения сложных визуальных задач, связанных с тонкими различиями изображений. Исследование подтверждает разнообразие и качество Img-Diff, поощряя дальнейшее исследование в мультимодальном синтезе данных.
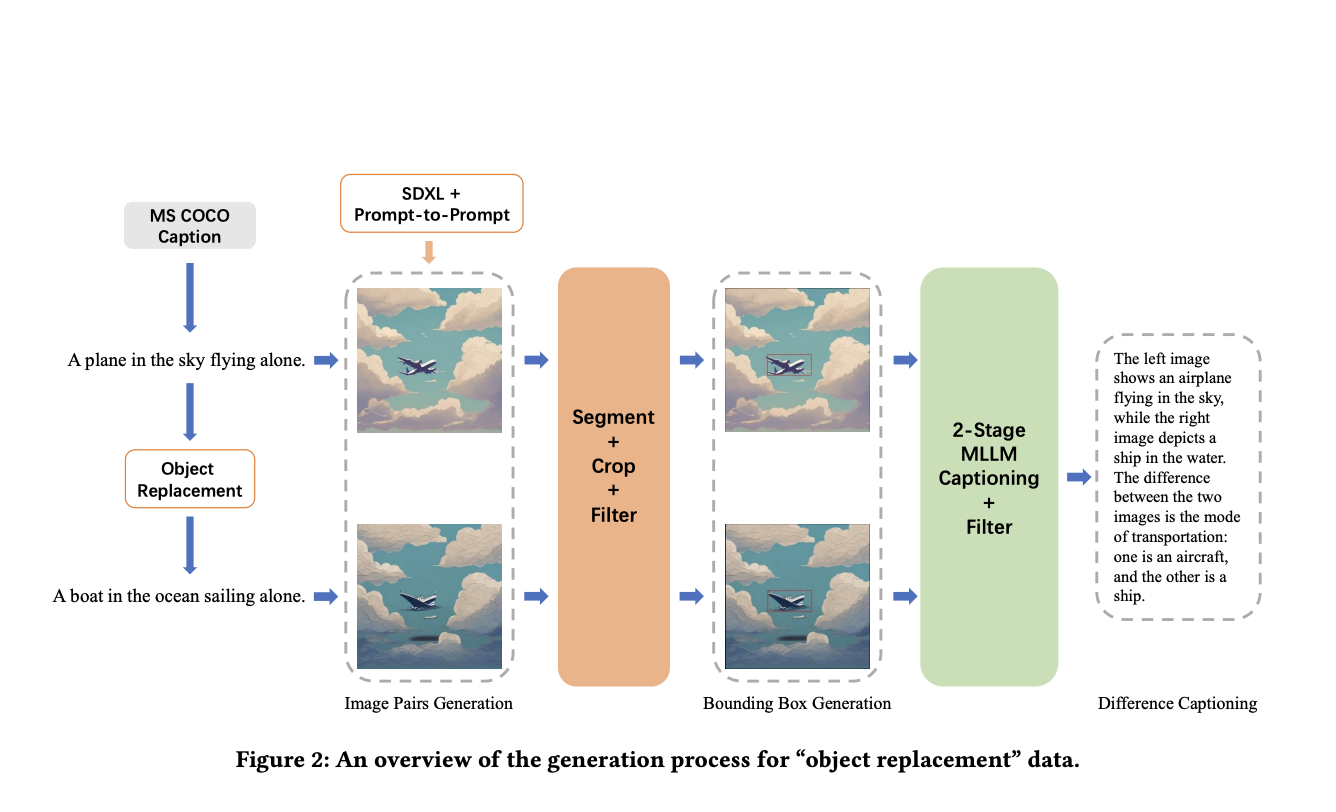
Исследователи разработали набор данных Img-Diff системным подходом. Они создали 118 000 пар изображений с использованием подписей MSCOCO, применяя фильтр сходства изображений, чтобы получить 38 533 высокосходных пары. Были выбраны области ограничительных рамок с наименьшим сходством, установив N равным 5. Два процесса фильтрации — соответствие изображения-текста и сходство подписей — обеспечили допустимость областей ограничительных рамок и подписей. Генератор различий областей создал 117 779 фрагментов данных ограничительных рамок, в то время как генератор различий подписей создал 12 688 высококачественных экземпляров «замены объекта» с подробными описаниями. Наконец, современные MLLM, такие как LLaVA-1.5-7B и MGM-7B, были настроены с использованием набора данных для улучшения производительности в задачах различий изображений и вызовах VQA, демонстрируя эффективность Img-Diff в улучшении возможностей тонкого распознавания изображений MLLM.
Набор данных Img-Diff значительно улучшил производительность MLLM на различных тестах. LLaVA-1.5-7B показала улучшенные результаты на нескольких тестах, в то время как MGM-7B имел смешанные результаты. Обе модели достигли новых рекордных результатов на тесте по запросам на редактирование изображений. LLaVA-1.5-7B достигла среднего увеличения производительности на 3,06% по всем тестам, в сравнении с 1,28% у MGM-7B. Улучшения распространяются на задачи визуального вопроса-ответа, демонстрируя эффективность Img-Diff в улучшении распознавания различий изображений и возможностей редактирования MLLM.
В заключение, статья представляет новый набор данных, разработанный для улучшения возможностей MLLM в задачах распознавания различий изображений. Набор данных Img-Diff, созданный через инновационные методы, объединяющие контрастное обучение и различие подписей изображений, фокусируется на различиях объектов в парных изображениях. Тонкая настройка MLLM с использованием этого набора данных дает конкурентоспособные результаты производительности, сравнимые с моделями, обученными на гораздо больших наборах данных. Исследование подчеркивает важность тщательной генерации данных и процессов фильтрации, предоставляя представления для будущих исследований в мультимодальном синтезе данных. Демонстрируя эффективность целевых высококачественных наборов данных в улучшении возможностей MLLM, статья поощряет дальнейшее исследование в тонком распознавании изображений и мультимодальном обучении.
«`

























