Усиление обучения на основе обратной связи от человека (RLHF): ключевая техника для согласования крупных языковых моделей с человеческими ценностями
Практическое применение и ценность:
RLHF играет критическую роль в обеспечении понятного и надежного поведения систем искусственного интеллекта. Он улучшает возможности языковых моделей, обучая их на основе обратной связи, что позволяет моделям создавать более полезные, безопасные и честные результаты. Этот подход широко используется при разработке различных инструментов ИИ, начиная от разговорных агентов и заканчивая продвинутыми системами поддержки принятия решений, с целью интеграции человеческих предпочтений непосредственно в поведение модели.
Проблемы и вызовы:
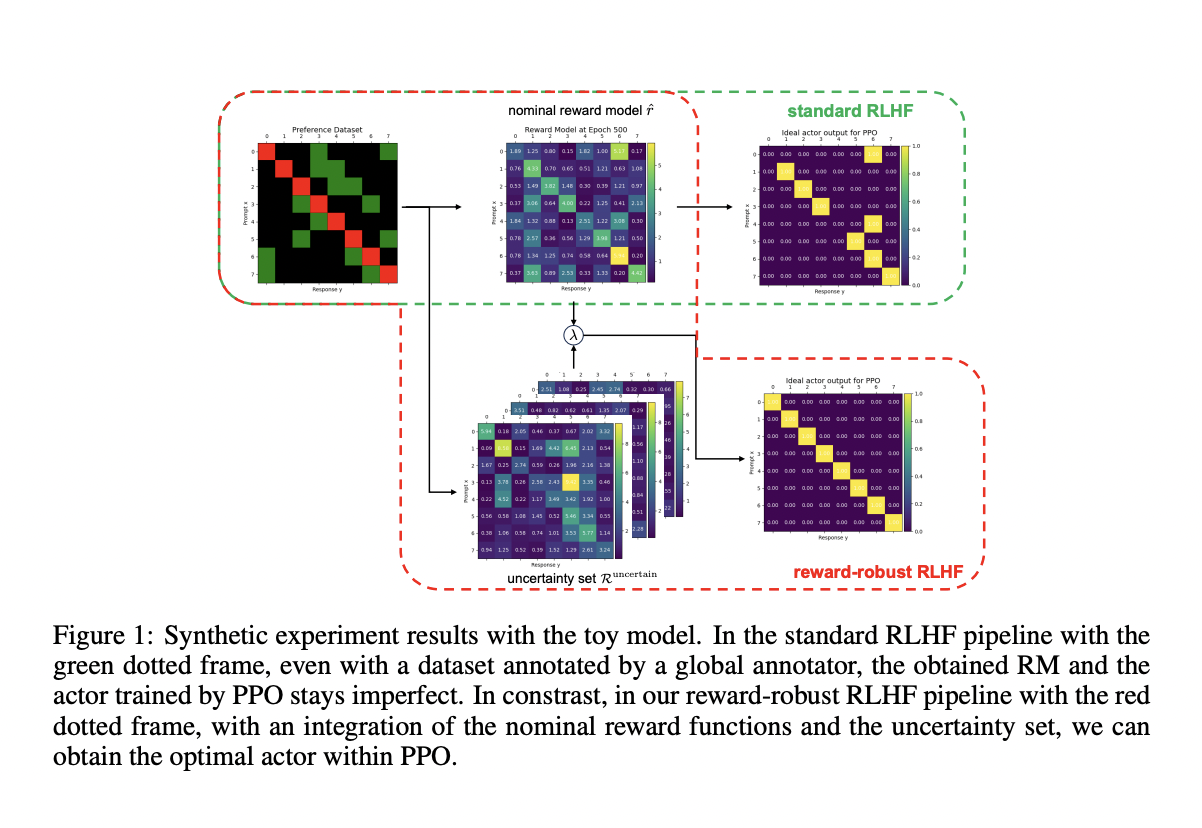
Одной из основных проблем RLHF является нестабильность и врожденные недостатки в моделях вознаграждения, которые направляют процесс обучения. Эти модели вознаграждения часто неправильно отражают человеческие предпочтения из-за присутствия предвзятостей в обучающих данных. Такие предвзятости могут привести к проблемам, таким как взлом вознаграждения, когда модели используют уязвимости в функции вознаграждения для получения более высоких вознаграждений, не улучшая при этом производительность задачи. Кроме того, модели вознаграждения часто страдают от переобучения и недообучения, что означает, что они плохо обобщаются на невидимые данные или не улавливают важные закономерности.
Решение и практическая ценность:
Исследователи из Университета Цинхуа и Baichuan AI представили новую надежную рамку RLHF с устойчивым вознаграждением. Эта инновационная рамка использует ансамбли моделей вознаграждения Байеса (BRME) для эффективного управления неопределенностью в сигналах вознаграждения. Использование BRME позволяет рамке включать несколько точек зрения в функцию вознаграждения, тем самым снижая риск несоответствия и нестабильности. Предложенная рамка разработана для балансирования производительности и надежности, что делает ее более устойчивой к ошибкам и предвзятостям. Путем интеграции BRME система может выбирать наиболее надежные сигналы вознаграждения, обеспечивая более стабильное обучение несмотря на неполные или предвзятые данные.
Итак, разработанная рамка RLHF с устойчивым вознаграждением продемонстрировала впечатляющую производительность, последовательно превосходя традиционные методы RLHF на различных бенчмарках. Это не только улучшает производительность, но и обеспечивает долгосрочную стабильность во время продолжительных периодов обучения, что является ключевым преимуществом рамки.