Q-Sparse: Новый подход искусственного интеллекта для обеспечения полной разреженности активаций в LLMs
LLM отлично справляются с задачами обработки естественного языка, но сталкиваются с проблемами развертывания из-за высоких вычислительных и памятных требований во время вывода. Недавние исследования направлены на повышение эффективности LLM через квантизацию, обрезку, дистилляцию и улучшенное декодирование. Разреженность, ключевой подход, уменьшает вычисления путем исключения нулевых элементов и уменьшает передачу ввода-вывода между памятью и вычислительными блоками. В то время как разреженность весов экономит вычисления, она сталкивается с параллелизацией GPU и потерей точности. Разреженность активации, достигаемая с помощью таких техник, как механизм смеси экспертов (MoE), также требует полной эффективности и дальнейшего изучения законов масштабирования по сравнению с плотными моделями.
Эффективность Q-Sparse
Исследователи из Microsoft и Университета Китайской академии наук разработали Q-Sparse, эффективный подход для обучения разреженно-активированных LLM. Q-Sparse обеспечивает полную разреженность активации, применяя разреживание top-K к активациям и используя прямую оценку во время обучения, значительно улучшая эффективность вывода. Ключевые результаты включают достижение базовой производительности LLM при более низких затратах вывода, установление оптимального закона масштабирования для разреженно-активированных LLM и демонстрацию эффективности в различных настройках обучения. Q-Sparse работает с полными и 1-битными моделями, предлагая путь к более эффективным, экономичным и энергосберегающим LLM.
Улучшение архитектуры Transformer
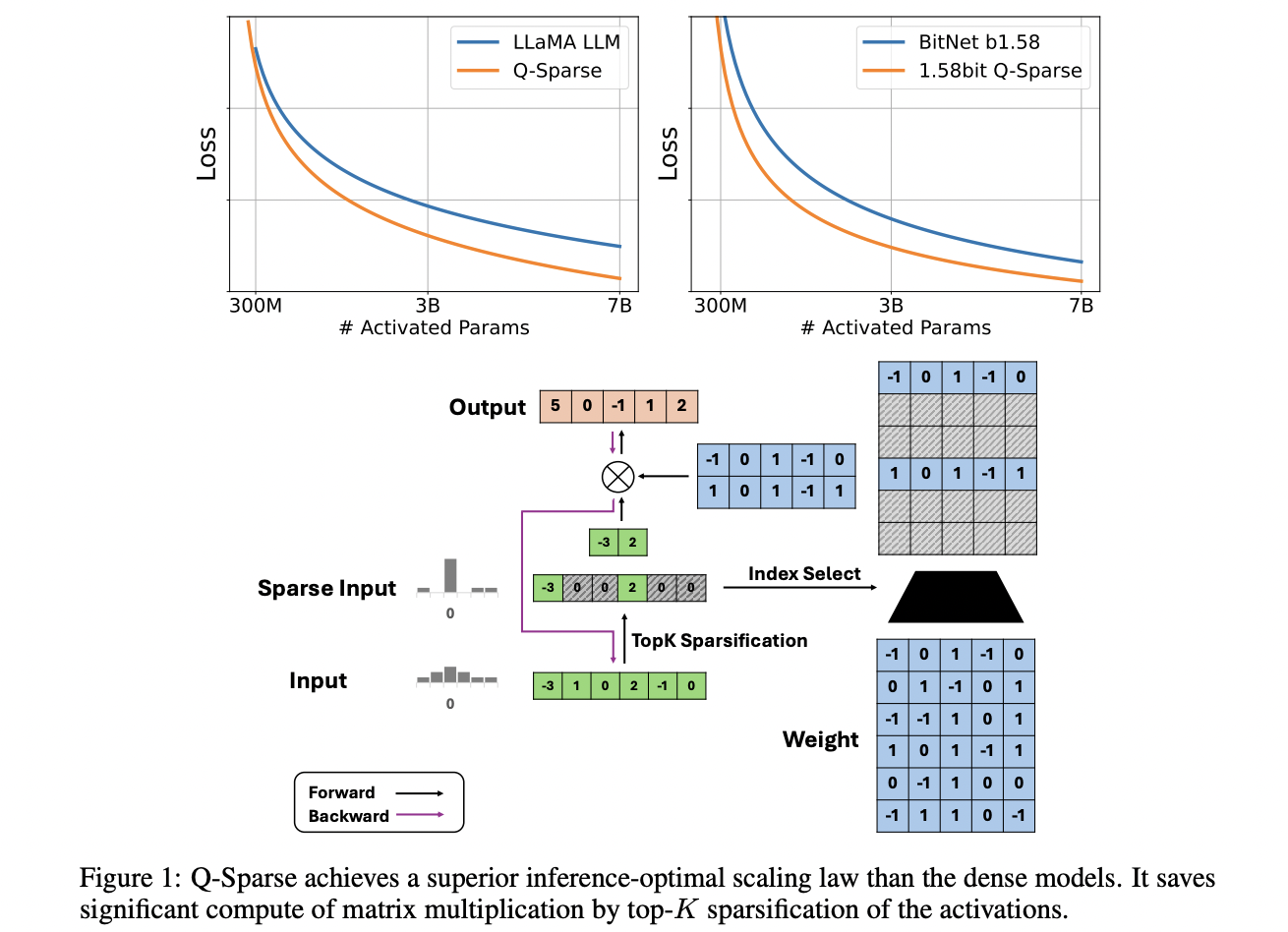
Q-Sparse улучшает архитектуру Transformer, обеспечивая полную разреженность активаций через разреживание top-K и прямую оценку (STE). Этот подход применяет функцию top-K к активациям во время умножения матриц, уменьшая вычислительные затраты и объем памяти. Он поддерживает полные и квантованные модели, включая 1-битные модели, такие как BitNet b1.58. Кроме того, Q-Sparse использует квадратичную функцию ReLU для слоев прямого распространения, чтобы улучшить разреженность активации. Для обучения он преодолевает исчезновение градиента с помощью STE. Q-Sparse эффективен для обучения с нуля, продолжения обучения и донастройки, поддерживая эффективность и производительность в различных настройках.
Масштабирование производительности
Недавние исследования показывают, что производительность LLM масштабируется с размером модели и обучающими данными по закону степени. Исследователи исследуют это для разреженно-активированных LLM, обнаруживая, что их производительность также подчиняется закону степени с размером модели и экспоненциальному закону соотношения разреженности. Эксперименты показывают, что при фиксированном соотношении разреженности производительность разреженно-активированных моделей масштабируется аналогично плотным моделям. Разрыв в производительности между разреженными и плотными моделями уменьшается с увеличением размера модели. Оптимальный закон масштабирования вывода показывает, что разреженные модели могут эффективно соответствовать или превосходить плотные модели с правильной разреженностью, с оптимальными соотношениями разреженности 45,58% для полной точности и 61,25% для 1,58-битных моделей.
Оценка эффективности Q-Sparse LLM
Исследователи оценили Q-Sparse LLM в различных настройках, включая обучение с нуля, продолжение обучения и донастройку. При обучении с нуля с 50 млрд токенов Q-Sparse соответствовал плотным базовым значениям при 40% разреженности. Модели BitNet b1.58 с Q-Sparse превзошли плотные базовые значения при том же бюджете вычислений. Продолжение обучения Mistral 7B показало, что Q-Sparse достигает сопоставимой производительности с плотными базовыми значениями, но с более высокой эффективностью. Результаты донастройки продемонстрировали, что модели Q-Sparse с около 4 млрд активированных параметров соответствуют или превосходят производительность плотных 7 млрд моделей, доказывая эффективность и эффективность Q-Sparse в различных сценариях обучения.
Заключение
Результаты показывают, что сочетание BitNet b1.58 с Q-Sparse предлагает значительные выгоды в эффективности, особенно в выводе. Исследователи планируют масштабировать обучение с более крупными моделями и токенами и интегрировать YOCO для оптимизации управления кэшем KV. Q-Sparse дополняет MoE и будет адаптирован для пакетной обработки для улучшения его практичности. Q-Sparse работает сопоставимо с плотными базовыми значениями, улучшая эффективность вывода через разреживание top-K и прямую оценку. Он эффективен в различных настройках и совместим с полными и 1-битными моделями, что делает его ключевым подходом для улучшения эффективности и устойчивости LLM.









