«`html
WTU-Eval: новый стандартный инструмент для оценки возможностей использования больших языковых моделей (LLM)
Большие языковые модели (LLM) отлично справляются с различными задачами, включая генерацию текста, перевод и резюмирование. Однако возникает растущая проблема в области обработки естественного языка (NLP) — как эффективно взаимодействовать с внешними инструментами для выполнения задач, выходящих за пределы их встроенных возможностей. Это особенно актуально в реальных приложениях, где LLM должны получать данные в реальном времени, выполнять сложные вычисления или взаимодействовать с API для точного выполнения задач.
Основные проблемы и решения
Одной из основных проблем является процесс принятия решений LLM о том, когда использовать внешние инструменты. В реальных сценариях часто неясно, нужен ли инструмент. Неправильное или ненужное использование инструмента может привести к значительным ошибкам и неэффективности. Поэтому основная проблема, над которой работает недавнее исследование, заключается в улучшении способности LLM различать свои границы возможностей и принимать точные решения относительно использования инструментов. Это улучшение критически важно для поддержания производительности и надежности LLM в практических приложениях.
Традиционные методы улучшения использования инструментов LLM сосредотачивались на настройке моделей для конкретных задач, где использование инструмента обязательно. Техники, такие как обучение с подкреплением и деревья решений, показали свою эффективность, особенно в математическом рассуждении и поиске веб-страниц. Были разработаны бенчмарки, такие как APIBench и ToolBench, для оценки умения LLM работать с API и реальными инструментами. Однако эти бенчмарки обычно предполагают, что использование инструмента всегда необходимо, что не отражает неопределенность и изменчивость, с которыми сталкиваются в реальных сценариях.
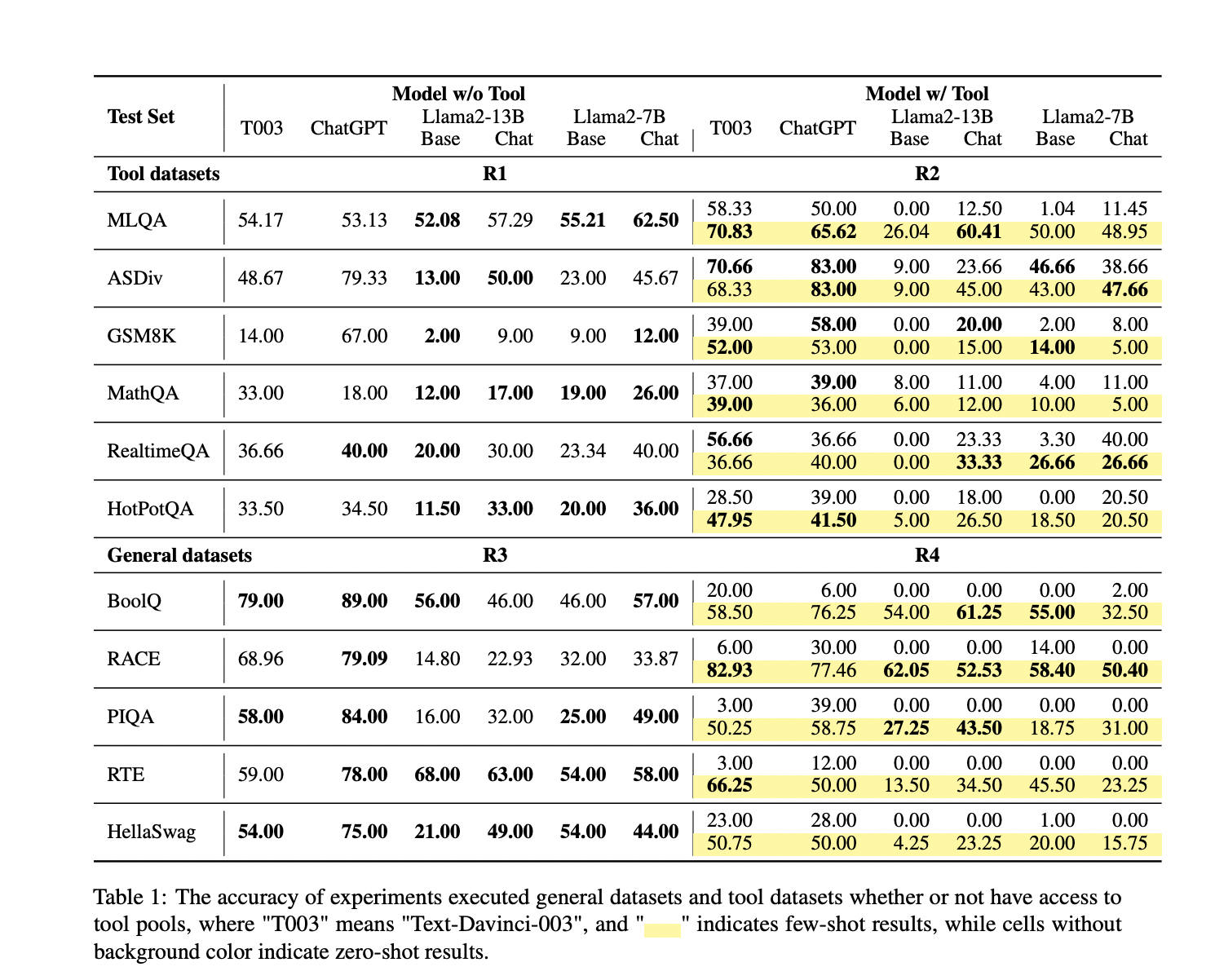
Исследователи из Университета Бэйцзяотун, Университета Фучжоу и Института автоматизации КАС представили бенчмарк оценки использования инструментов Whether-or-not tool usage Evaluation (WTU-Eval), чтобы заполнить эту пробел. Этот бенчмарк предназначен для оценки гибкости принятия решений LLM относительно использования инструментов. WTU-Eval включает одиннадцать наборов данных, из которых шесть явно требуют использование инструмента, в то время как оставшиеся пять являются общими наборами данных, которые можно решить без инструментов. Такая структура позволяет провести всестороннюю оценку способности LLM различать, когда использование инструмента необходимо. Бенчмарк включает задачи, такие как машинный перевод, математическое рассуждение и поиск веб-страниц в реальном времени, обеспечивая надежную основу для оценки.
Кроме того, исследовательская группа разработала набор данных для настройки моделей, состоящий из 4000 экземпляров, полученных из тренировочных наборов WTU-Eval. Этот набор данных предназначен для улучшения способности принятия решений LLM относительно использования инструментов. Нацеливая модели с помощью этого набора данных, исследователи стремились улучшить точность и эффективность LLM в распознавании, когда использовать инструменты, и эффективно интегрировать выводы инструментов в свои ответы.
Оценка LLM с использованием WTU-Eval
Оценка восьми ведущих LLM с использованием WTU-Eval выявила несколько ключевых результатов. Во-первых, большинству моделей требуется помощь в определении использования инструмента в общих наборах данных. Например, производительность модели Llama2-13B снизилась до 0% в некоторых вопросах об использовании инструментов в настройках zero-shot, подчеркивая сложности, с которыми сталкиваются LLM в таких сценариях. Однако производительность моделей улучшилась в наборах данных, требующих использования инструментов, когда их способности более тесно соответствовали моделям, таким как ChatGPT. Настройка модели Llama2-7B привела к улучшению средней производительности на 14% и снижению неправильного использования инструментов на 16,8%. Это улучшение было особенно заметно в наборах данных, требующих получения информации в реальном времени и выполнения математических расчетов.
Дальнейший анализ показал, что различные инструменты оказывали разное влияние на производительность LLM. Например, более простые инструменты, такие как переводчики, управлялись более эффективно LLM, в то время как более сложные инструменты, такие как калькуляторы и поисковые системы, представляли большие вызовы. В настройках zero-shot профессиональное мастерство LLM значительно снижалось с увеличением сложности инструментов. Например, производительность модели Llama2-7B снизилась до 0% при использовании сложных инструментов в некоторых наборах данных, в то время как ChatGPT показал значительные улучшения до 25% в задачах, таких как GSM8K, когда инструменты использовались правильно.
Выводы и рекомендации
Бенчмарк WTU-Eval предоставляет ценные исследования ограничений использования инструментов LLM и потенциальных улучшениях. Дизайн бенчмарка, который включает комбинацию использования инструментов и общих наборов данных, позволяет детально оценить способности моделей принятия решений. Успех набора данных для настройки в улучшении производительности подчеркивает важность целенаправленного обучения для улучшения способности LLM принимать решения об использовании инструментов.
В заключение, исследование подчеркивает критическую необходимость для LLM развивать лучшие способности принятия решений относительно использования инструментов. Бенчмарк WTU-Eval предлагает всестороннюю основу для оценки этих способностей, показывая, что хотя настройка может значительно улучшить производительность, многие модели все еще испытывают трудности с точным определением своих границ возможностей. Будущая работа должна сосредоточиться на расширении бенчмарка с добавлением большего количества наборов данных и инструментов, а также на изучении различных типов LLM для улучшения их практических применений в различных реальных сценариях.
«`

























