Compositional GSM: Новый AI-бенчмарк для оценки способностей к рассуждению крупных языковых моделей в задачах с несколькими шагами
Практические решения и ценность:
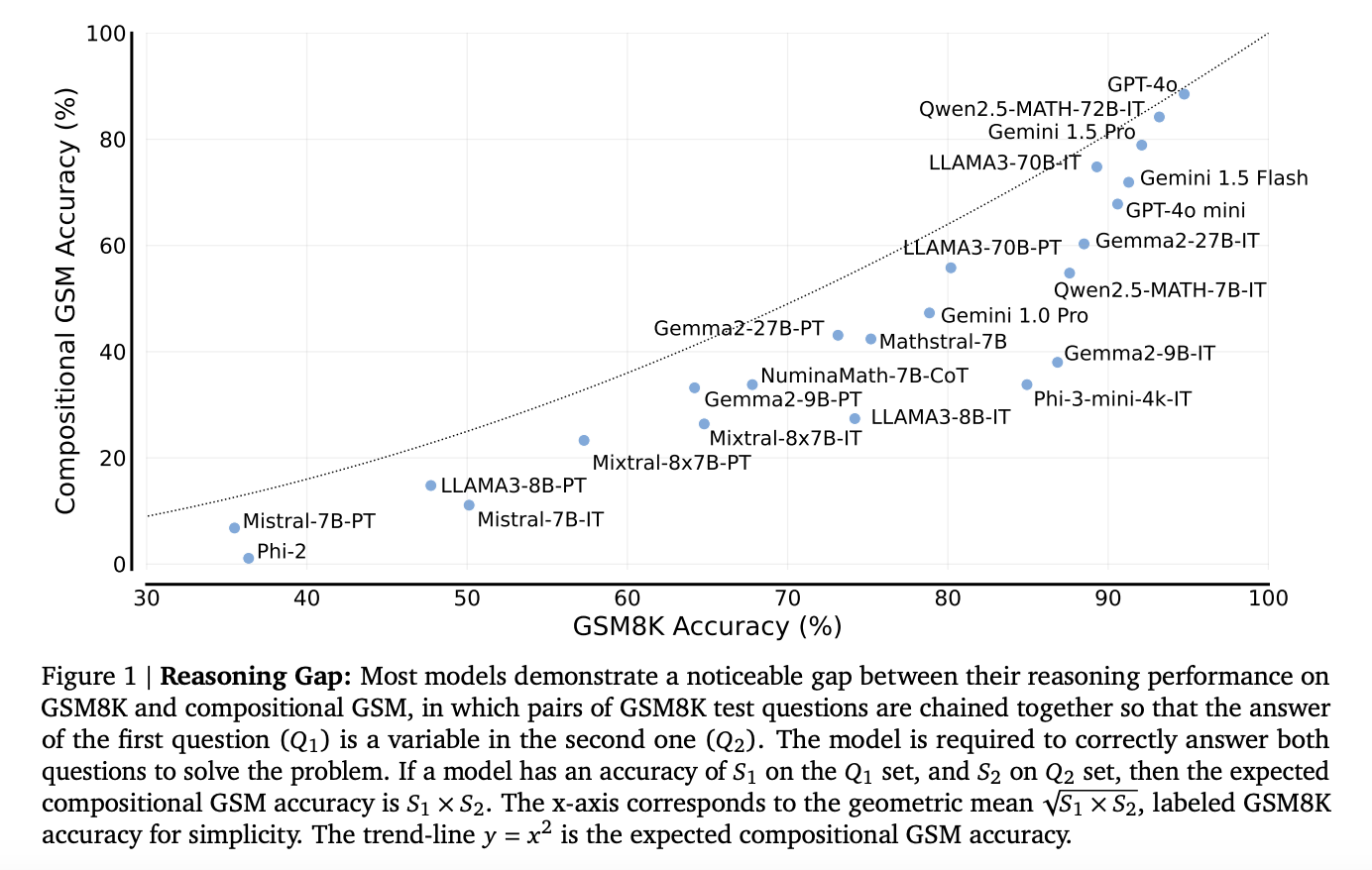
Исследователи выявили значительные пробелы в способностях к рассуждению. Например, модели с невысокой стоимостью, такие как GPT-4o mini, показали 2-12 раз худшую способность к рассуждению в составной GSM по сравнению с результатами на стандартном GSM8K. Это подчеркивает, что для подготовки моделей к многошаговым задачам требуется более специализированное обучение в математике.
Использование генерации кода вместо естественного языка привело к улучшению от 71% до 149% для некоторых небольших моделей в составной GSM. Это указывает на то, что генерация кода помогает уменьшить разрыв в рассуждениях, но не устраняет его, сохраняя систематические различия в способностях к рассуждению между различными моделями.
Исследование показывает, что текущие языковые модели, несмотря на успех на стандартных бенчмарках, продолжают испытывать трудности с составными задачами рассуждения. Бенчмарк Compositional GSM предлагает ценный инструмент для оценки способностей к рассуждению языковых моделей за пределами изолированного решения проблем.

























