Решения для балансировки производительности и эффективности вычислений в крупных моделях языка и зрения
Проблема:
Увеличение размера моделей языка и зрения (LLVMs) до 80 миллиардов параметров приводит к впечатляющим результатам, но требует огромных вычислительных ресурсов для обучения и вывода.
Решение:
Phantom LLVM — семейство моделей с параметрами от 0,5 миллиарда до 7 миллиардов, которые улучшают обучение за счет временного увеличения скрытого измерения во время многоголового внимания само-внимания (MHSA).
Оптимизация:
Phantom Optimization (PO) сочетает в себе методы авторегрессивного обучения с прямой оптимизацией предпочтений для улучшения эффективности обработки данных.
Преимущества:
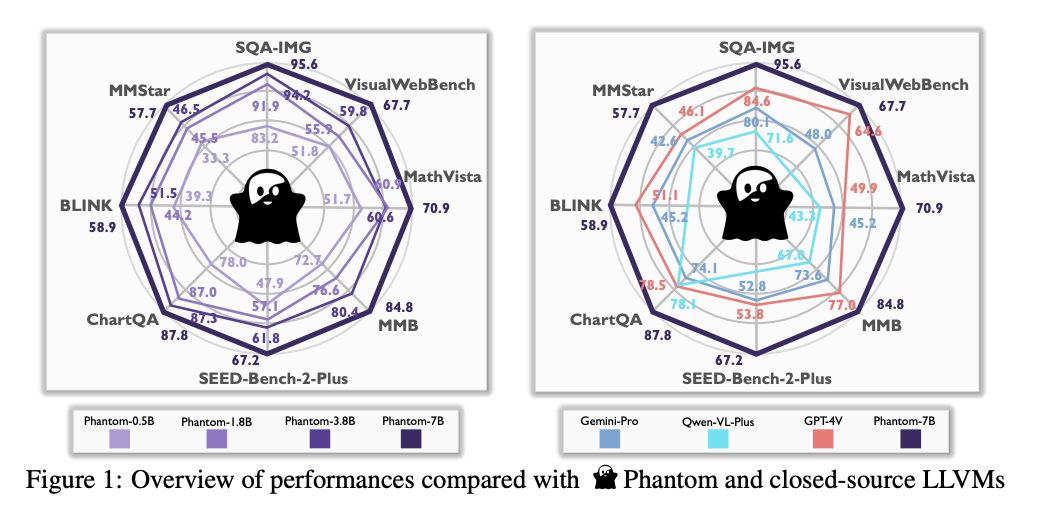
Phantom обеспечивает значительное улучшение производительности в задачах понимания изображений, интерпретации графиков и математического рассуждения, превосходя более крупные модели в точности.
Значение:
Phantom позволяет использовать более компактные модели на уровне более крупных, что снижает вычислительную нагрузку и делает их пригодными для применения в ограниченных ресурсах средах.