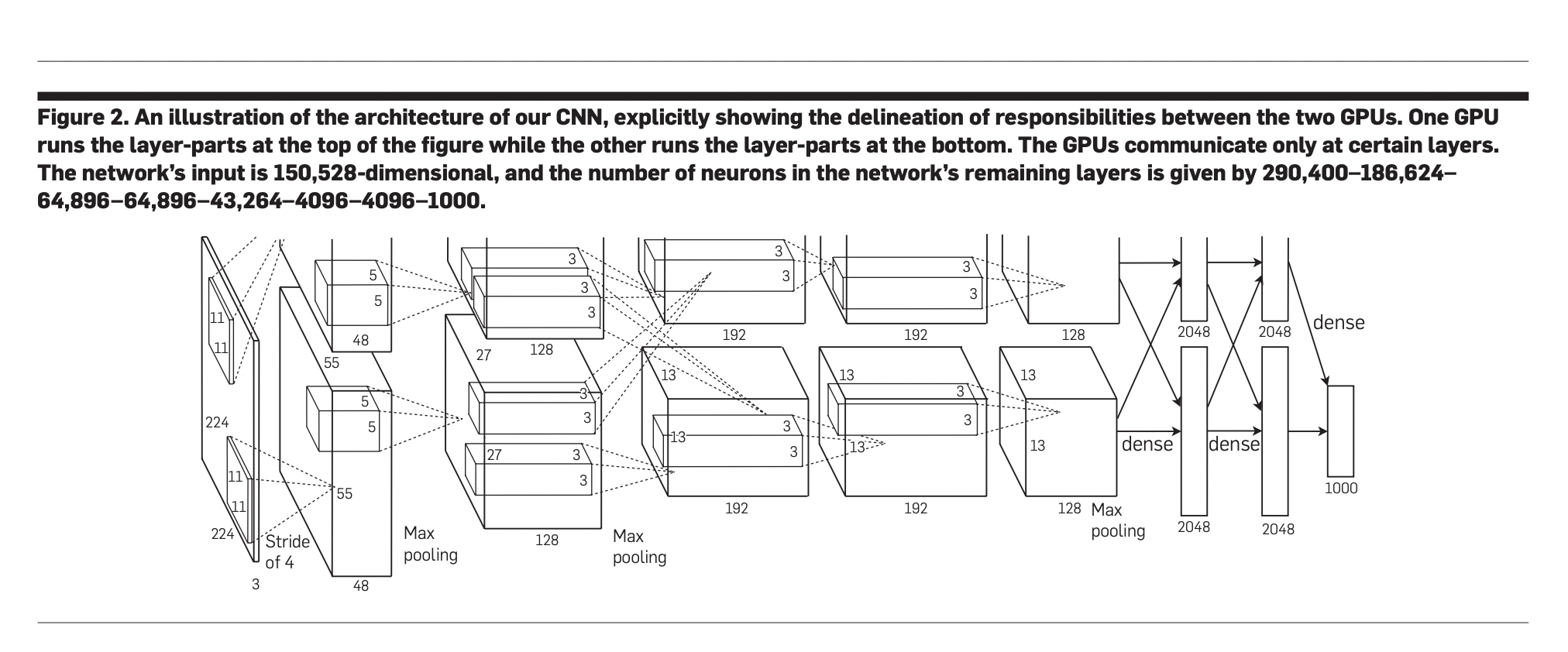
Обучение большой CNN для классификации изображений:
Исследователи разработали большую сверточную нейронную сеть (CNN) для классификации 1,2 миллиона изображений высокого разрешения из соревнования ImageNet LSVRC-2010, охватывающего 1 000 категорий. Модель, содержащая 60 миллионов параметров и 650 000 нейронов, показала впечатляющие результаты с ошибками top-1 и top-5 в 37,5% и 17,0% соответственно, значительно превосходя предыдущие методы. Архитектура включает пять сверточных слоев и три полностью связанных слоя, заканчиваясь 1 000-путевым softmax. Ключевые инновации, такие как использование ненасыщающих нейронов и применение dropout для предотвращения переобучения, позволили эффективно обучать на GPU. Производительность CNN улучшилась в соревновании ILSVRC-2012, достигнув ошибки top-5 в 15,3%, по сравнению с 26,2% следующей лучшей моделью.
Значение практических решений:
Использование больших данных и мощности вычислений ведет к улучшению эффективности и масштабируемости нейронных сетей. Применение инновационных методов, таких как ReLUs и dropout, позволяет достичь высоких результатов при обучении глубоких моделей на больших наборах данных. Эти техники помогают улучшить обобщающую способность и снизить ошибки, открывая путь к созданию более мощных и данных-ориентированных моделей в области компьютерного зрения.
Набор данных и архитектура сети:
Исследователи использовали ImageNet, обширный набор данных из более чем 15 миллионов изображений высокого разрешения по приблизительно 22 000 категориям, для обучения своей CNN. Для соревнования ILSVRC они сосредоточились на подмножестве ImageNet, содержащем около 1,2 миллиона обучающих изображений, 50 000 проверочных изображений и 150 000 тестовых изображений, равномерно распределенных по 1 000 категориям. Архитектура CNN состояла из восьми слоев, включая пять сверточных и три полностью связанных, с 1 000-путевым softmax на выходе.
Практическое применение:
Применение ReLUs, локальной нормализации ответа и перекрывающегося пулинга улучшают обобщение и снижают ошибки, обеспечивая эффективное обучение глубоких сетей. Оптимизированные реализации операций свертки на GPU позволяют достичь передовой производительности в задачах распознавания объектов.
Снижение переобучения в нейронных сетях:
Использование методов аугментации данных и dropout позволяет бороться с переобучением, что приводит к улучшению результатов и обобщающей способности модели без значительного увеличения вычислительных затрат.
Результаты на соревнованиях ILSVRC:
Модель CNN показала отличные результаты с ошибками top-1 и top-5 в 37,5% и 17,0% соответственно на наборе данных ILSVRC-2010, превзойдя предыдущие методы. Успех этой модели подтолкнул к широкому применению глубокого обучения в компаниях, революционизируя область компьютерного зрения.

























