“`html
Революция в аудио-классификации: Audio Mamba достигает производительности трансформера без самовнимания
Классификация аудиофайлов претерпела значительные изменения с принятием моделей глубокого обучения. Первоначально доминировали сверточные нейронные сети (CNN), но затем этот сегмент перешел к архитектурам на основе трансформеров, которые обеспечивают улучшенную производительность и способность обрабатывать различные задачи через унифицированный подход. Трансформеры превосходят CNN в производительности, создавая парадигмальный сдвиг в глубоком обучении, особенно для функций, требующих обширного контекстного понимания и обработки разнообразных типов входных данных.
Основные проблемы в аудио-классификации
Основной вызов в аудио-классификации – это вычислительная сложность, связанная с трансформерами, особенно из-за их механизма самовнимания, который масштабируется квадратично с длиной последовательности. Это делает их неэффективными для обработки длинных аудио-последовательностей, требуя альтернативных методов для поддержания производительности при снижении вычислительной нагрузки. Решение этой проблемы критично для разработки моделей, способных эффективно обрабатывать увеличивающийся объем и сложность аудио-данных в различных приложениях, от распознавания речи до классификации звуков окружающей среды.
Решение проблемы
В настоящее время наиболее перспективным методом для аудио-классификации является Audio Spectrogram Transformer (AST). AST использует механизмы самовнимания для захвата глобального контекста в аудио-данных, но страдает от высоких вычислительных затрат. Модели пространства состояний (SSM) были исследованы как потенциальная альтернатива, обеспечивая линейное масштабирование с длиной последовательности. SSM, такие как Mamba, показали перспективу в языковых и зрительных задачах, заменяя самовнимание на параметры, изменяющиеся со временем, для более эффективного захвата глобального контекста. Несмотря на их успех в других областях, SSM до сих пор не получили широкого распространения в аудио-классификации, представляя возможность для инноваций в этой области.
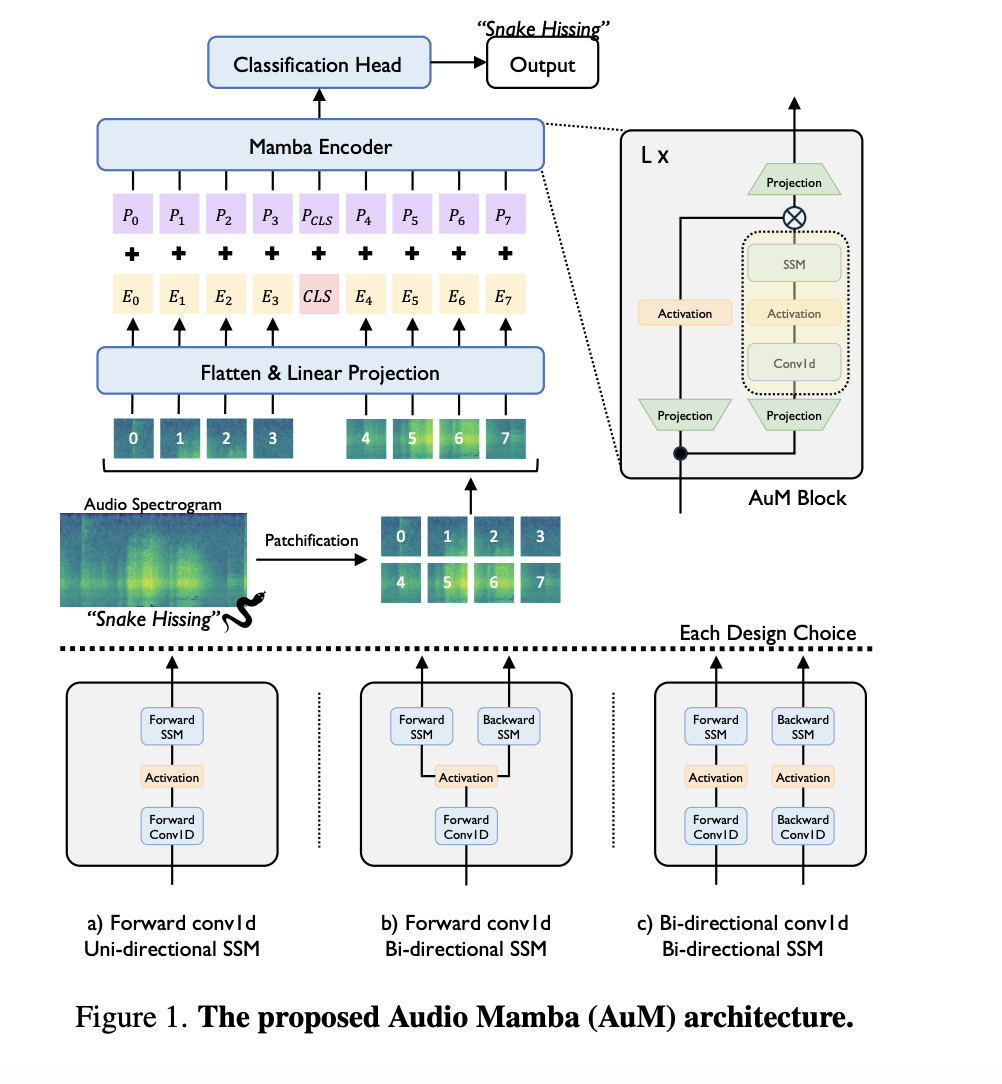
Исследователи из Корейского института науки и технологий представили Audio Mamba (AuM), новую модель без самовнимания на основе моделей пространства состояний для аудио-классификации. Эта модель эффективно обрабатывает аудио-спектрограммы с помощью двунаправленного подхода для обработки длинных последовательностей без квадратичного масштабирования, характерного для трансформеров. Модель AuM нацелена на устранение вычислительной нагрузки самовнимания, используя SSM для поддержания высокой производительности и улучшения эффективности. Решая неэффективности трансформеров, AuM предлагает перспективную альтернативу для задач аудио-классификации.
Преимущества и результаты
Архитектура Audio Mamba включает преобразование входных аудио-волн в спектрограммы, которые затем разделяются на фрагменты. Эти фрагменты преобразуются в токены встраивания и обрабатываются с использованием двунаправленных моделей пространства состояний. Модель работает в обоих направлениях, эффективно захватывая глобальный контекст и поддерживая линейную временную сложность, тем самым улучшая скорость обработки и использование памяти по сравнению с AST. Архитектура включает несколько инновационных дизайнерских решений, таких как стратегическое размещение обучаемого токена классификации посередине последовательности и использование позиционных встраиваний для улучшения способности модели понимать пространственную структуру входных данных.
Audio Mamba продемонстрировала конкурентоспособную производительность на различных бенчмарках, включая AudioSet, VGGSound и VoxCeleb. Модель достигла сравнимых или лучших результатов по сравнению с AST, особенно преуспевая в задачах с длинными аудио-последовательностями. Например, на наборе данных VGGSound Audio Mamba превзошла AST с существенным улучшением точности более чем на 5%, достигнув точности 42,58% по сравнению с 37,25% у AST. На наборе данных AudioSet AuM достигла средней средней точности (mAP) 32,43%, превзойдя 29,10% у AST. Эти результаты подчеркивают способность AuM обеспечивать высокую производительность, сохраняя вычислительную эффективность, что делает ее надежным решением для различных задач аудио-классификации.
Оценка показала, что AuM требует значительно меньше памяти и времени обработки. Например, во время обучения с аудио-клипами длиной 20 секунд AuM потребляла память, эквивалентную меньшей модели AST, обеспечивая при этом превосходную производительность. Кроме того, время вывода AuM было в 1,6 раза быстрее, чем у AST при количестве токенов 4096, демонстрируя его эффективность в обработке длинных последовательностей. Это снижение вычислительных требований без ущерба точности указывает на то, что AuM отлично подходит для реальных приложений, где ограничения ресурсов являются критическими.
В заключение, внедрение Audio Mamba является значительным прорывом в аудио-классификации, устраняя ограничения самовнимания в трансформерах. Эффективность модели и конкурентоспособная производительность подчеркивают ее потенциал как жизнеспособной альтернативы для обработки длинных аудио-последовательностей. Исследователи считают, что подход Audio Mamba может проложить путь для будущих разработок аудио- и мультимодального обучения. Возможность обработки длинных аудиофайлов становится все более важной, особенно с ростом самообучения мультимодальных данных и генерации, использующих данные из реальной жизни и автоматического распознавания речи. Кроме того, AuM может быть использована в настройках самообучения, таких как Audio Masked Auto Encoders, или в мультимодальных задачах, таких как предварительное обучение аудио-визуальных данных или контрастное языково-аудио-предварительное обучение, способствуя развитию области аудио-классификации.
“`


























