Новый метод MEFT для оптимизации памяти при fine-tuning LLM
Большие языковые модели (LLM) стали ключевыми в обработке естественного языка благодаря их способности выполнять широкий спектр задач с высокой точностью. Тем не менее, процесс feine-tuning LLM требует значительных вычислительных ресурсов и памяти.
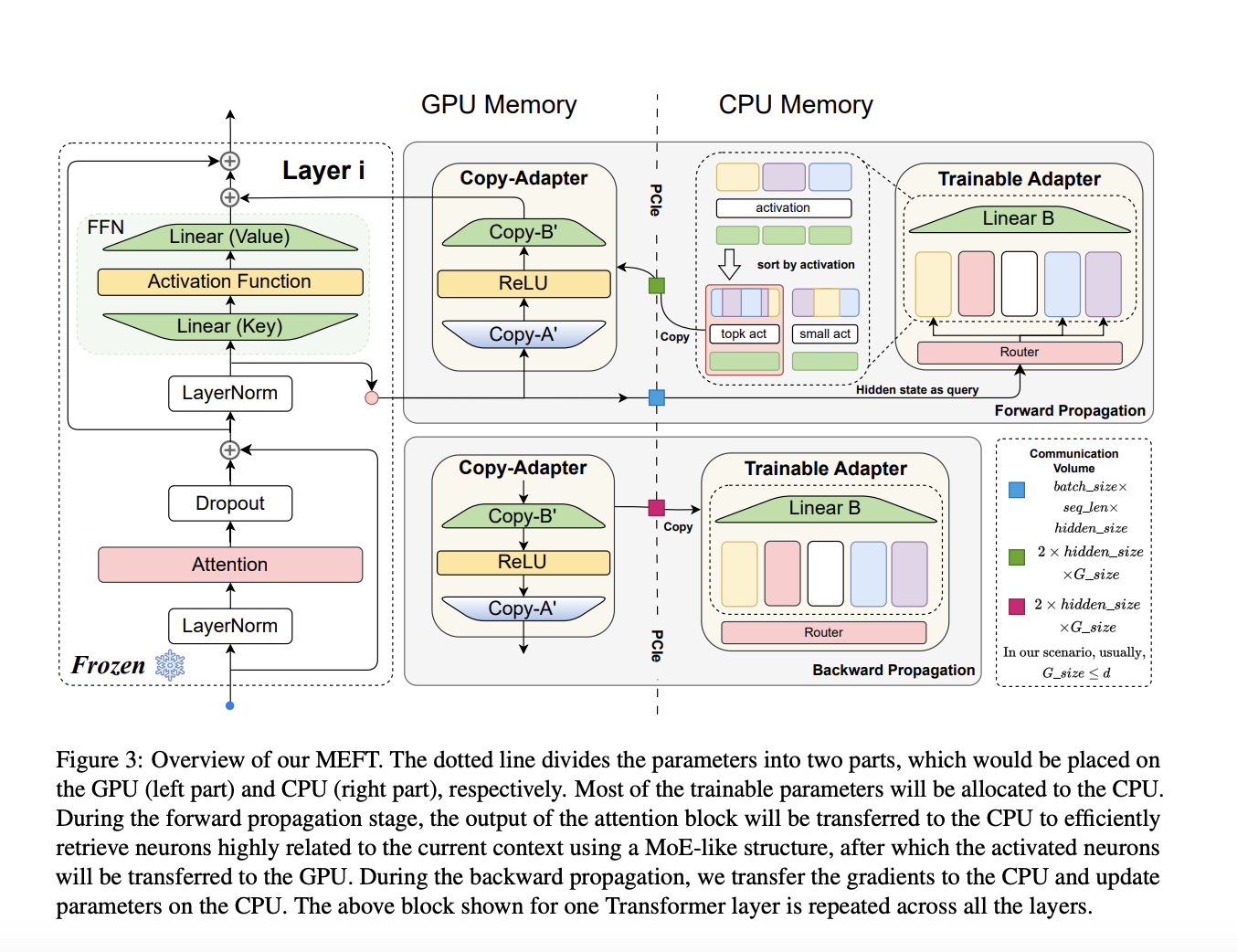
Как MEFT решает проблему
Метод MEFT разработан для оптимизации использования ресурсов, путем хранения и обновления параметров адаптера на процессоре (CPU), с использованием архитектуры Mixture of Experts (MoE) для оптимизации вычислений и уменьшения коммуникации между GPU и CPU.
Результаты тестирования
Исследователи выяснили, что MEFT снижает использование памяти GPU на 50%, сохраняя при этом производительность, сравнимую с полными методами fine-tuning. MEFT продемонстрировал эффективность на различных наборах данных, включая NQ, SQuAD, ToolBench и GSM8K, что подтверждает его способность работать с ограниченными ресурсами.
Заключение
MEFT представляет собой эффективное решение для проблемы ресурсоемкости fine-tuning больших языковых моделей, обеспечивая сравнимые результаты с полными методами fine-tuning при ограниченных ресурсах. Это значительное достижение в обработке естественного языка, открывающее новые возможности для применения LLM.

























