Эффективное обучение с учетом квантования (EfficientQAT): новая техника квантования машинного обучения для сжатия крупных языковых моделей (LLMs)
По мере того как крупные языковые модели (LLMs) становятся все более важными для различных задач искусственного интеллекта, их огромные размеры параметров приводят к высоким требованиям к памяти и потреблению полосы пропускания. Техника обучения с учетом квантования (QAT) предлагает потенциальное решение, позволяя моделям работать с представлениями меньшего бита, но существующие методы часто требуют обширных ресурсов для обучения, что делает их непрактичными для крупных моделей.
Текущие методы квантования для LLMs
Существующие методы квантования для LLMs включают квантование после обучения (PTQ) и квантование параметров с эффективной донастройкой (Q-PEFT). PTQ минимизирует использование памяти во время вывода, преобразуя веса предварительно обученной модели в форматы с меньшим количеством бит, но это может ухудшить точность, особенно в режимах с малым количеством бит. Методы Q-PEFT, такие как QLoRA, позволяют проводить донастройку на видеокартах для потребителей, но требуют возвращения к форматам с большим количеством бит для дополнительной настройки, что требует еще одного раунда PTQ, что может ухудшить производительность.
Эффективное обучение с учетом квантования (EfficientQAT)
Исследователи предлагают Efficient Quantization-Aware Training (EfficientQAT) для преодоления этих ограничений. Эффективная структура EfficientQAT работает через две основные фазы. В фазе Block-AP проводится обучение с учетом квантования для всех параметров в каждом блоке трансформатора, используя блочную реконструкцию для поддержания эффективности. Этот подход обходит необходимость полного обучения модели, сохраняя тем самым ресурсы памяти. Затем в фазе E2E-QP фиксируются квантованные веса и обучаются только параметры квантования (шаги), что улучшает эффективность и производительность модели без накладных расходов, связанных с обучением всей модели. Эта двухфазная стратегия улучшает скорость сходимости и позволяет эффективно настраивать инструкции квантованных моделей.
Фаза Block-AP EfficientQAT начинается с стандартного метода равномерного квантования, квантования и деквантования весов блочным образом. Этот метод позволяет эффективное обучение с меньшим количеством данных и памяти по сравнению с традиционными подходами к обучению с учетом квантования от начала до конца. Обучая все параметры, включая масштабные коэффициенты и нулевые точки, Block-AP обеспечивает точную калибровку и избегает проблем переобучения, обычно связанных с одновременным обучением всей модели.
В фазе E2E-QP обучаются только параметры квантования, сохраняя квантованные веса фиксированными. Эта фаза использует надежную инициализацию, предоставляемую Block-AP, что позволяет эффективно и точно настраивать квантованную модель для конкретных задач. E2E-QP обеспечивает настройку инструкций квантованных моделей, обеспечивая эффективность использования памяти, поскольку обучаемые параметры составляют только небольшую часть общей сети.
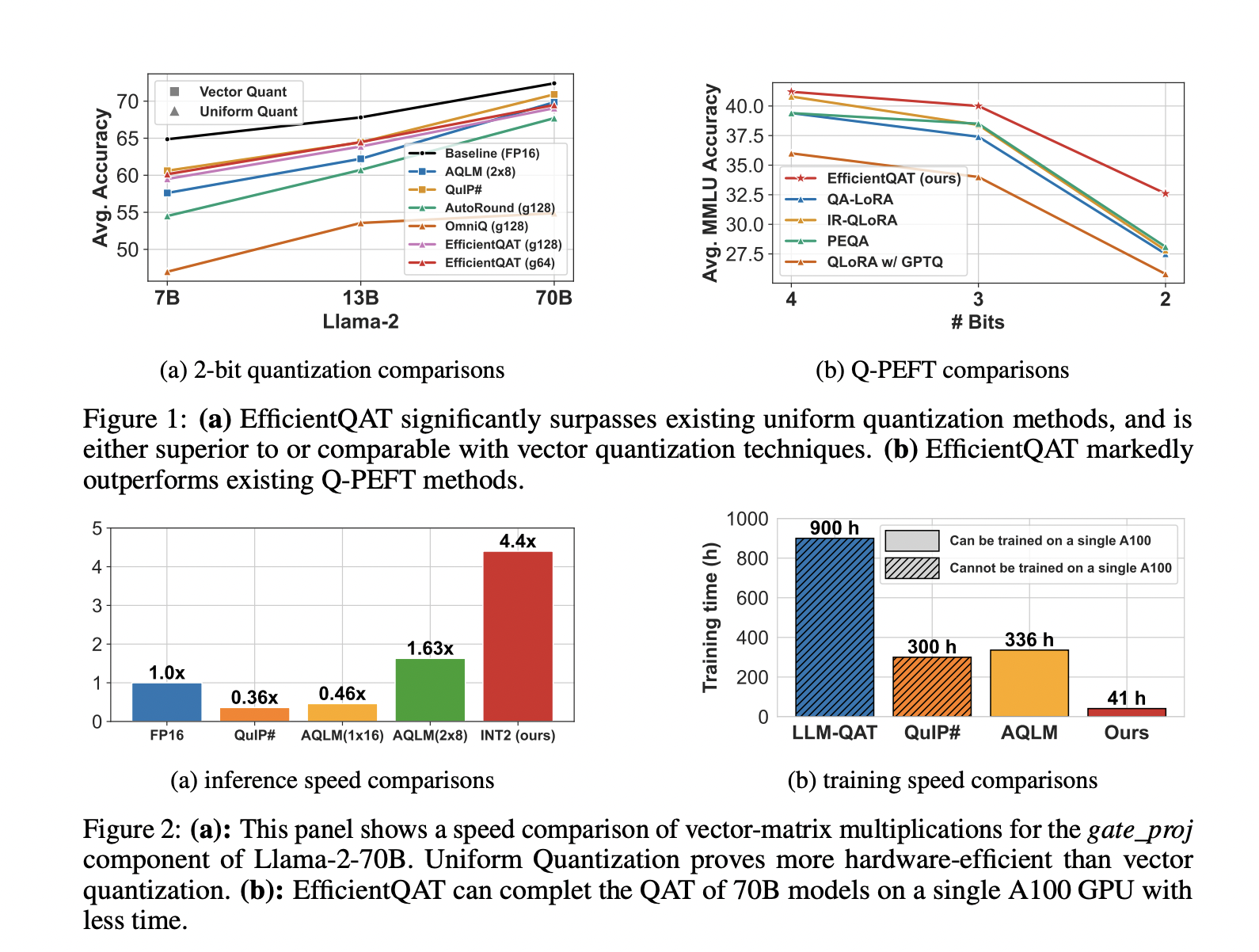
EfficientQAT демонстрирует значительные улучшения по сравнению с предыдущими методами квантования. Например, он достигает квантования 2 битов модели Llama-2-70B на одном графическом процессоре A100-80GB за 41 час, с менее чем 3% ухудшением точности по сравнению с моделью полной точности. Кроме того, он превосходит существующие методы Q-PEFT в сценариях с низким количеством бит, предоставляя более эффективное аппаратное решение.
Заключение
Структура EfficientQAT представляет собой убедительное решение для преодоления вызовов, представленных крупными языковыми моделями в плане эффективности памяти и вычислений. Представляя двухфазный подход к обучению, сосредоточенный на блочном обучении и оптимизации параметров квантования от начала до конца, исследователи эффективно снижают потребности в ресурсах обучения с учетом квантования, сохраняя при этом высокую производительность. Этот метод представляет собой значительный прогресс в области квантования моделей, предоставляя практический путь для развертывания крупных языковых моделей в ресурсоемких средах.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit.
Статья «Efficient Quantization-Aware Training (EfficientQAT): A Novel Machine Learning Quantization Technique for Compressing LLMs» впервые появилась на MarkTechPost.
Применение искусственного интеллекта в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Efficient Quantization-Aware Training (EfficientQAT): A Novel Machine Learning Quantization Technique for Compressing LLMs.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























