«`html
Ограничения больших языковых моделей (LLM): новые бенчмарки и метрики для задач классификации
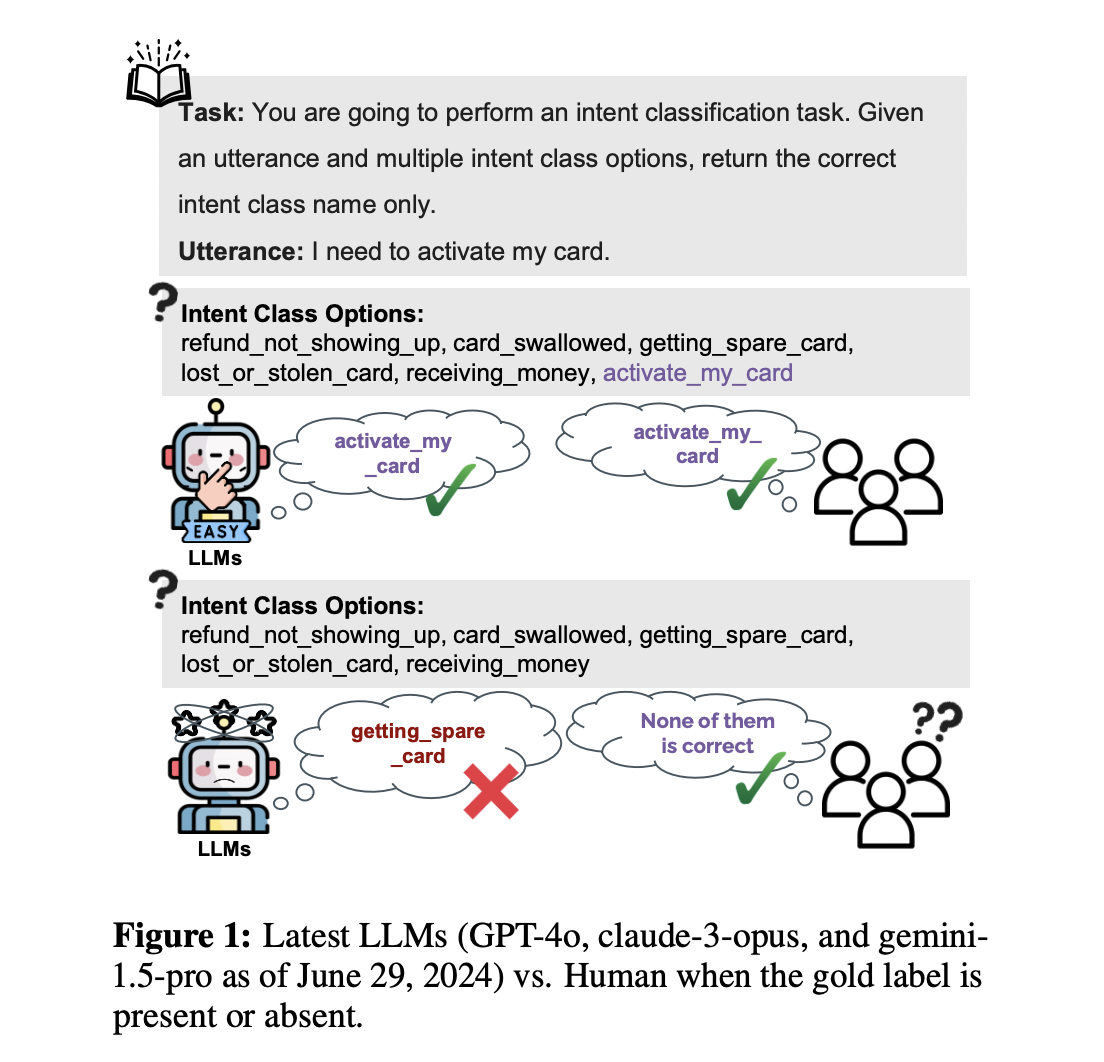
Большие языковые модели (LLM) продемонстрировали впечатляющую производительность в различных задачах, особенно в задачах классификации. Однако их способность выбирать среди вариантов, даже если ни один из них не является правильным, вызывает серьезные опасения относительно их реального понимания и интеллекта в сценариях классификации.
Основные проблемы в контексте LLM:
1. Универсальность и обработка меток: LLM могут работать с любым набором меток, даже сомнительной точности. Для избежания ввода пользователей в заблуждение они должны имитировать поведение человека, распознавая точные метки или указывая на их отсутствие.
2. Дискриминационные и генеративные возможности: Поскольку LLM в основном предназначены для генеративных моделей, они часто отказываются от дискриминационных возможностей, что может привести к переоценке их полезности.
Новые бенчмарки и метрики:
В недавних исследованиях были представлены три общих задачи категоризации в качестве бенчмарков для дальнейших исследований:
— BANK77: задача классификации намерений.
— MC-TEST: задача вопрос-ответ с множественным выбором.
— EQUINFER: задача определения правильного уравнения на основе окружающих абзацев в научных статьях.
Этот набор бенчмарков назван KNOW-NO и включает в себя задачи классификации с различными размерами, длинами и областями меток.
Была предложена новая метрика с названием OMNIACCURACY для оценки производительности LLM с большей точностью. Эта статистика оценивает категоризационные навыки LLM путем объединения результатов измерений двух измерений KNOW-NO: Accuracy-W/-GOLD и Accuracy-W/O-GOLD.
Основные вклады:
1. Это первое исследование, которое обращает внимание на ограничения LLM, когда правильные ответы отсутствуют в задачах классификации.
2. Была представлена новая CLASSIFY-W/O-GOLD, которая является новой системой оценки LLM и описывает эту задачу соответственно.
3. Был представлен бенчмарк KNOW-NO для оценки LLM в сценарии CLASSIFY-W/O-GOLD.
4. Была предложена метрика OMNIACCURACY, которая объединяет результаты при наличии и отсутствии правильных меток для оценки производительности LLM в задачах классификации.
Подробнее о статье можно узнать по ссылке на официальный источник. Вся заслуга за это исследование принадлежит исследователям проекта.
«`

























