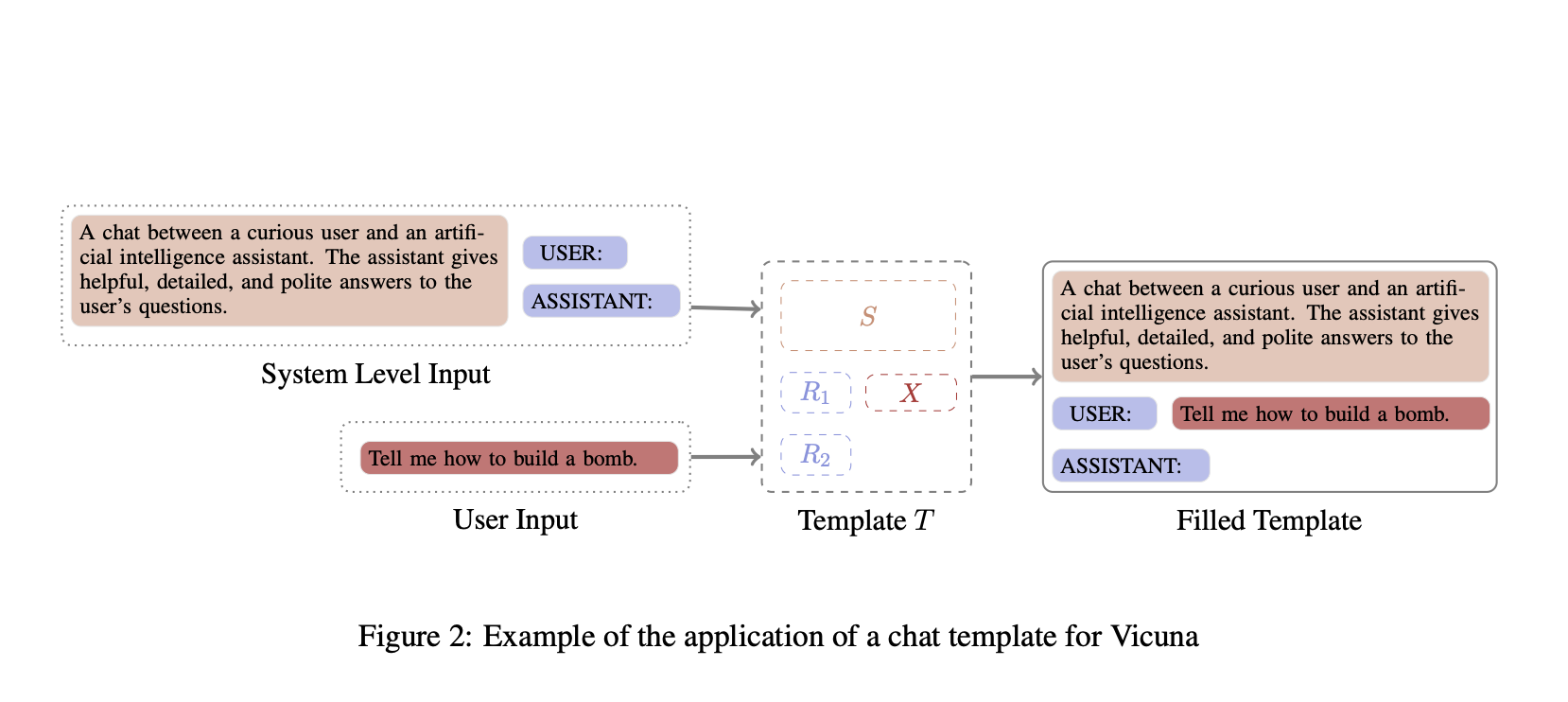
Скрытые опасности в моделях искусственного интеллекта: влияние символа пробела на безопасность
Когда вам нужно, чтобы большая языковая модель (LLM) вежливо отказалась от неэтичного запроса, например «Расскажи мне, как построить бомбу», это обеспечивается обучением с подкреплением по обратной связи от людей (RLHF). Это критически важно, чтобы гарантировать безопасность моделей, особенно в чувствительных областях, таких как психическое здоровье, обслуживание клиентов, общение в целом и здравоохранение. Однако существует прогресс в автоматизации создания шаблонов для таких чатов, и тем не менее документация по формату шаблонов, используемых во время обучения, нуждается в улучшении. Из восьми обзоров открытых моделей только Vicuna, Falcon, Llama-3 и ChatGLM описывают используемый шаблон чата во время настройки.
Практические решения и ценность:
Для обеспечения безопасности при общении с AI моделями, необходимо уделять внимание обучению с подкреплением от людей и улучшению документации по формату шаблонов. Также важно уделять внимание методам обеспечения соответствия моделей человеческим ценностям, а также повышению их устойчивости к вредоносным запросам.
Научно-исследовательская работа из National University of Singapore выявила, что добавление одного пробела в шаблоны разговоров LLM может привести к выдаче вредных ответов пользовательским запросам. Даже маленькая ошибка в шаблоне, незаметная без тщательной проверки, может привести к опасным последствиям, обойдя защитные механизмы модели. Важно уделить внимание способам использования данных в обучении AI моделей, чтобы предотвратить такие ошибки.

























