Self-Play Preference Optimization (SPPO): Инновационный подход машинного обучения для настройки больших языковых моделей (LLM) отзывами от человека/ИИ
Большие языковые модели (LLM) продемонстрировали удивительные способности в генерации текста, ответах на вопросы и написании кода. Однако они сталкиваются с препятствиями, требующими высокой надежности, безопасности и этичности. Обучение с подкреплением на основе обратной связи от человека (RLHF) или предпочтительное обучение с подкреплением (PbRL) появляется как многообещающее решение. Этот фреймворк показал значительный успех в настройке LLM для соответствия предпочтениям человека, улучшая их полезность.
Практические решения и ценность:
- RLHF помогает настраивать LLM в соответствии с предпочтениями людей, улучшая их полезность.
- SPPO предлагает эффективное решение для настройки LLM, обеспечивая гарантированное решение игр двух игроков и масштабируемость для больших языковых моделей.
- Алгоритм SPPO асимптотически сходится к оптимальной политике, обеспечивая сходимость и предоставляя гарантии.
- SPPO продемонстрировал улучшенную сходимость и эффективное решение проблемы редкости данных по сравнению с существующими методами, такими как DPO и IPO.
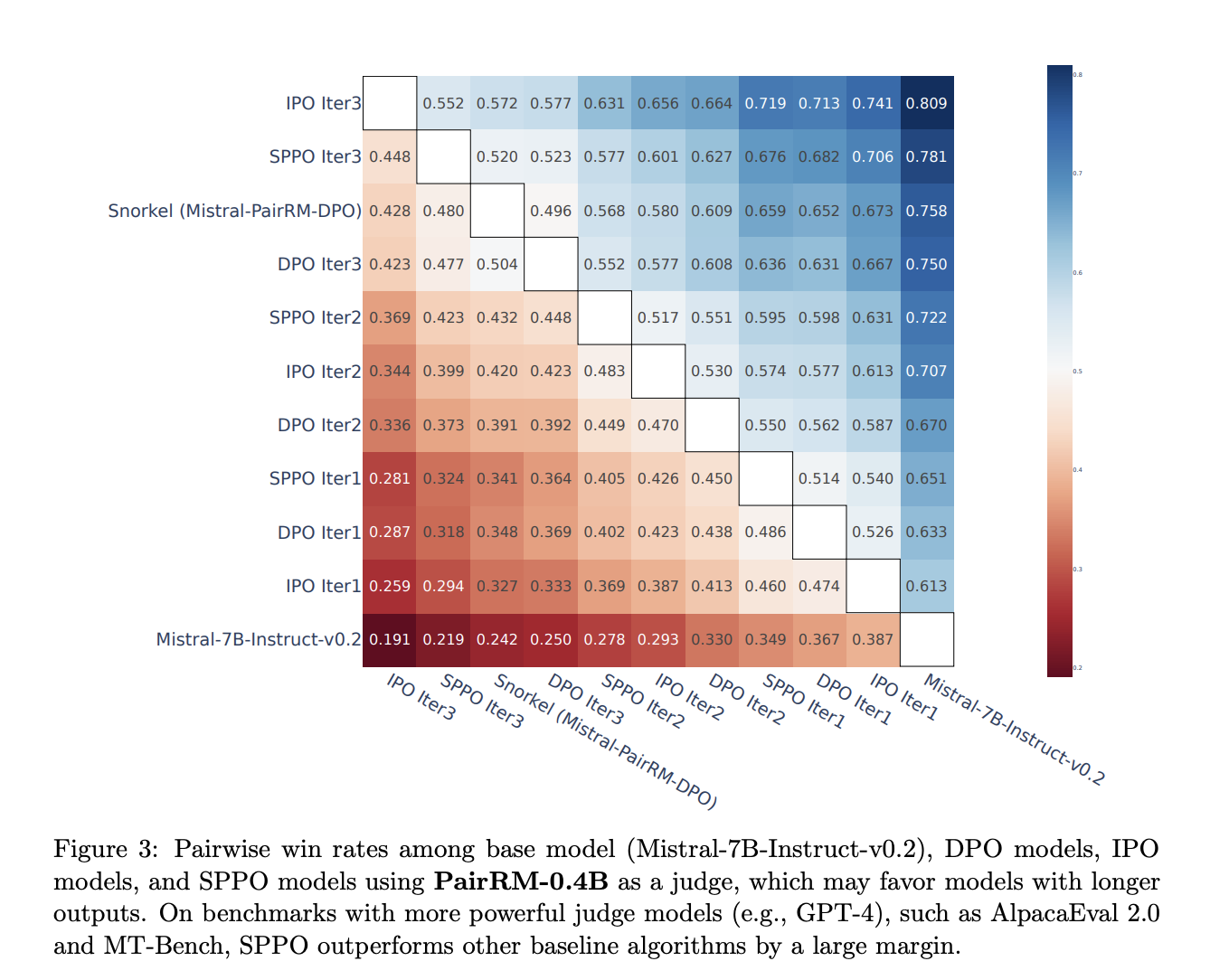
- SPPO превосходит многие современные чат-боты на AlpacaEval 2.0 и остается конкурентоспособным с GPT-4 на MT-Bench.
Подробнее ознакомиться с документом
Все права на исследование принадлежат ученым этого проекта. Также не забывайте следить за нами в Twitter. Присоединяйтесь к нашему каналу в Telegram, группе в Discord и LinkedIn.
Интеграция ИИ в ваш бизнес
Если вы хотите, чтобы ваша компания оставалась в числе лидеров и развивалась с помощью искусственного интеллекта (ИИ), рассмотрите применение метода Self-Play Preference Optimization (SPPO). Он значительно улучшает текущие методы настройки LLM и помогает выравнивать их с предпочтениями человека.
Практические шаги к интеграции ИИ:
- Проанализируйте, где возможно применение автоматизации и как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые вы хотите улучшить с помощью ИИ.
- Выберите подходящее решение из многообразия вариантов ИИ и внедряйте его постепенно, начиная с малого проекта.
- Анализируйте результаты и KPI, и на основе полученных данных и опыта расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах от Flycode.ru. Этот ИИ ассистент помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж и снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru

























