Оптимизация KV-Cache для эффективного вывода крупных языковых моделей
Большие языковые модели (LLM) — это подмножество искусственного интеллекта, фокусирующееся на понимании и генерации человеческого языка. Эти модели используют сложные архитектуры для понимания и создания текста, что облегчает их применение в области обслуживания клиентов, создания контента и не только.
Основная проблема с LLM
Однако основная проблема с LLM заключается в их эффективности при обработке длинных текстов. Архитектура Transformer, которую они используют, имеет квадратичную сложность по времени, что значительно увеличивает вычислительную нагрузку, особенно при работе с расширенными последовательностями. Эта сложность создает значительное препятствие для достижения эффективной производительности, особенно по мере увеличения длины входных текстов.
Решение проблемы
Исследователи предложили механизм KV-Cache для решения этой проблемы, который хранит ключи и значения, сгенерированные предыдущими токенами. Это снижает сложность по времени с квадратичной до линейной. Однако KV-Cache увеличивает использование памяти GPU, что масштабируется с увеличением длины разговора, создавая новое узкое место. Текущие методы направлены на балансировку этой компромиссной ситуации между вычислительной эффективностью и накладными расходами памяти, что делает эффективное использование KV-Cache необходимым.
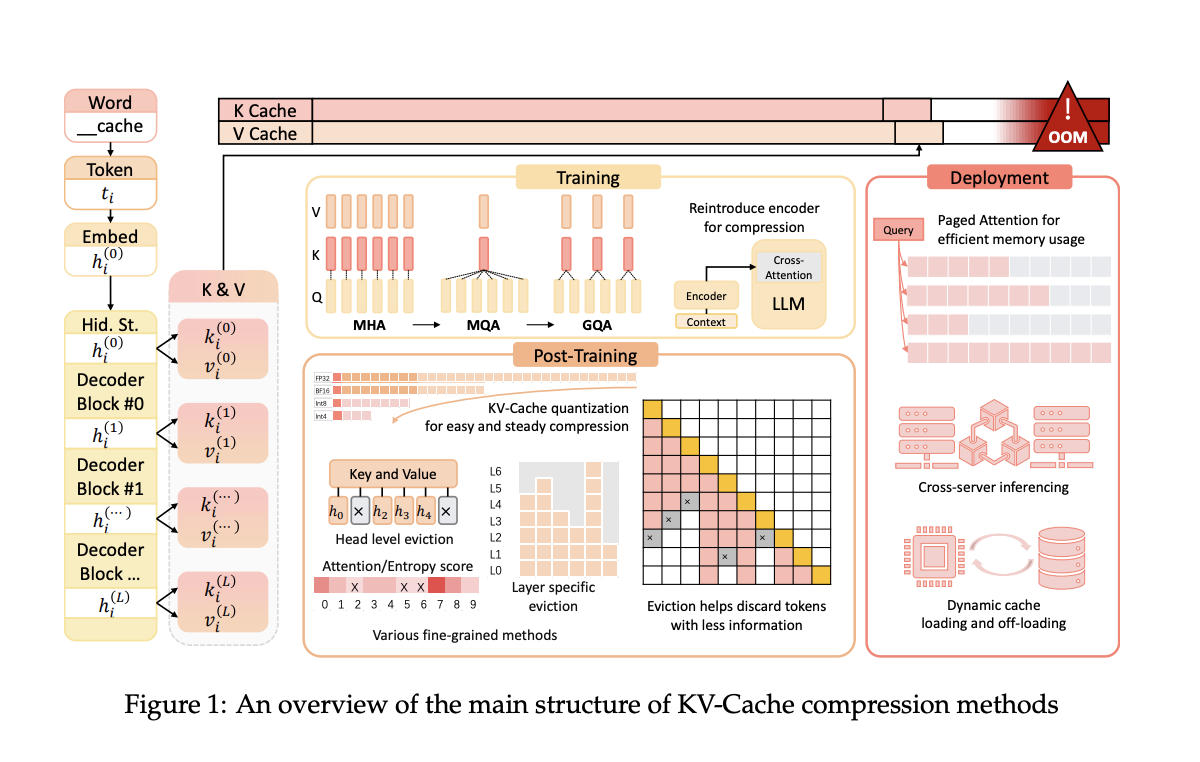
Команда исследователей из Университета Ухань и Шанхайского университета Джао Тунг представила несколько методов сжатия KV-Cache. Эти методы оптимизируют использование пространства KV-Cache во время предварительного обучения, развертывания и вывода LLM, с целью повышения эффективности без ущерба производительности.
Предложенные методы включают архитектурные корректировки во время предварительного обучения, которые уменьшают размер сгенерированных векторов ключей и значений. Во время развертывания фреймворки, такие как Paged Attention и DistKV-LLM, распределяют KV-Cache по нескольким серверам для улучшения управления памятью. Методы после обучения включают динамические стратегии вытеснения и методы квантования, которые сжимают KV-Cache без значительной потери возможностей модели.
Исследование показывает, что представленные методы значительно улучшают эффективность использования памяти и скорость вывода. Например, метод GQA, используемый в популярных моделях, таких как LLaMA2-70B, достигает лучшего использования памяти, уменьшая размер KV-Cache, сохраняя при этом уровень производительности.
Эти оптимизации демонстрируют потенциал более эффективной обработки более длинных контекстов. Модели, использующие Multi-Query Attention (MQA) и GQA, демонстрируют улучшенную пропускную способность и сниженную задержку, что является важными метриками для приложений в реальном времени.
Исследование предоставляет комплексные стратегии для оптимизации KV-Cache в LLM, решая проблему накладных расходов памяти. Путем реализации этих методов LLM могут достичь более высокой эффективности и производительности, что открывает путь для более устойчивых и масштабируемых решений в области искусственного интеллекта.

























