Reflection 70B: новый метод борьбы с галлюцинациями в больших языковых моделях
Галлюцинации — это явление, при котором большие языковые модели (LLM) производят ответы, которые не соответствуют реальности или не соответствуют предоставленному контексту, генерируя неправильную, вводящую в заблуждение или бессмысленную информацию. Эти ошибки могут иметь серьезные последствия, особенно в приложениях, требующих высокой точности, таких как медицинская диагностика, юридические консультации или другие важные сценарии. По мере распространения использования LLM, минимизация таких галлюцинаций является необходимой для обеспечения доверия и надежности в системах искусственного интеллекта.
Рефлексионная техника в борьбе с галлюцинациями
Текущие подходы к управлению галлюцинациями в LLM обычно сосредотачиваются на улучшении методов обучения или максимизации вероятности правильных ответов. Однако эти методы не решают основную проблему — как модели обрабатывают и отражают свое мышление перед генерацией выводов. Исследователи предлагают новый подход, называемый «Рефлексионная настройка», интегрированный в модель Reflection 70B, построенную на открытом исходном коде Llama 3.1-70B Instruct от Meta. Предложенный метод позволяет модели размышлять над своими рассуждениями в процессе генерации выводов для улучшения точности и последовательности.
В отличие от других моделей, которые прямо выводят один ответ, Reflection 70B добавляет различные фазы рассуждения и отражения с использованием специальных токенов. При генерации ответов модель выводит свое мышление внутри специальных тегов
Рефлексионная настройка является основой этого подхода, используя форму самостоятельного обучения для обучения модели приостанавливать, анализировать свое мышление и исправлять ошибки перед ответом. Методика обучения включает несколько этапов: генерация подсказок по различным темам, генерация ответов, размышления о сгенерированных ответах для обеспечения точности и последовательности, а также улучшение этих ответов на основе рефлексии. Это дает модели возможность реагировать и оценивать качество своих собственных ответов.
Практическое применение Reflection 70B
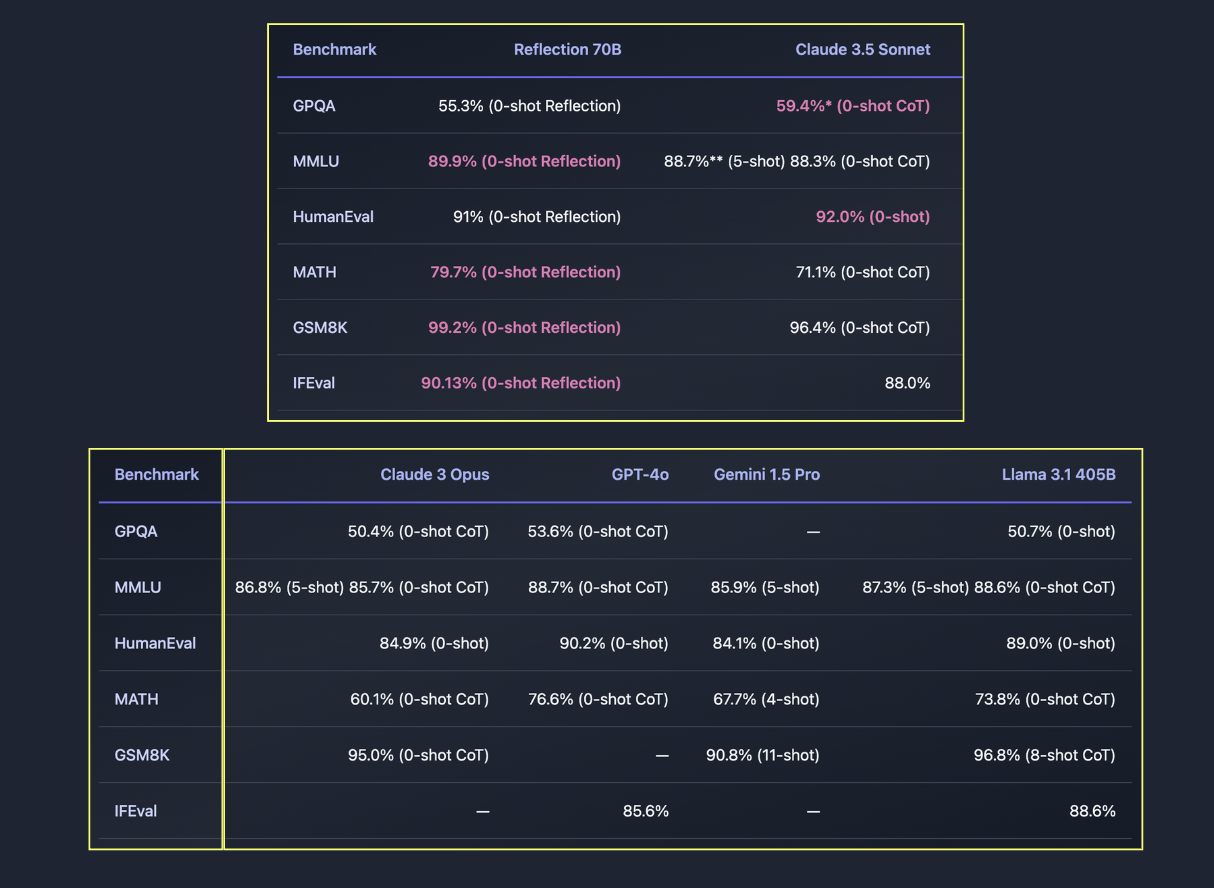
Reflection 70B показал значительное улучшение в уменьшении галлюцинаций. Тесты, такие как MMLU, MATH и IFEval, отражают его превосходство над другими моделями, такими как GPT-4 и Sonnet 3.5. Reflection 70B достиг 89,9% на MMLU, 79,7% на MATH и 90,1% на IFEval, подтверждая его эффективность в генерации точных и контекстно-связанных ответов. Кроме того, он был проверен на предмет загрязнения с использованием LLM Decontaminator от LMSys, обеспечивая его надежность и устойчивость.
В заключение, Reflection 70B представляет новый и практичный подход к уменьшению галлюцинаций в LLM через технику Reflection-Tuning. Обучение модели размышлять над своими рассуждениями перед генерацией окончательных выводов успешно снижает ошибки и повышает общую надежность ее ответов. Механизм рефлексии предлагает многообещающий путь вперед, хотя все еще есть место для дальнейших исследований и улучшения в обработке более сложных галлюцинаций.

























