“`html
Продвижение ИИ-моделей с помощью открытого набора данных Synthetic-GSM8K-reflection-405B от Gretel.ai
С использованием искусственного интеллекта возрастает потребность в высококачественных наборах данных, способных поддерживать обучение и оценку моделей в различных областях. Одним из значительных событий стало открытие набора данных Synthetic-GSM8K-reflection-405B компанией Gretel.ai, который обещает значительные возможности для задач рассуждения, особенно тех, которые требуют многошагового решения проблем. Этот набор данных, размещенный на платформе Hugging Face, был синтетически создан с использованием инструмента Gretel Navigator, а в качестве модели языка-агента (LLM) выступает Meta-Llama-3.1-405B. Его создание отражает прогресс в использовании синтетической генерации данных и отражений ИИ для разработки надежных моделей ИИ.
Создание синтетических данных с использованием техник отражения
Одной из ключевых особенностей набора данных Synthetic-GSM8K-reflection-405B является его основание на синтетической генерации данных. Синтетически созданные данные, а не собранные из реальных событий, становятся все более важными для обучения моделей ИИ. В данном случае набор данных был создан с использованием инструмента Gretel Navigator, утонченного инструмента синтетической генерации данных. Этот уникальный набор данных использует Meta-Llama-3.1-405B, передовую модель LLM, в качестве генерирующего агента.
Набор данных черпает вдохновение из популярного набора данных GSM8K, но идет дальше, включая техники отражения. Эти техники позволяют модели вовлекаться в многошаговые рассуждения на этапах вопросов и ответов многошаговых задач. Цель использования отражений – имитировать человекоподобное рассуждение, где ИИ систематически разбивает сложные вопросы на более мелкие, управляемые шаги, отражаясь на каждом из них перед продвижением вперед. Этот подход улучшает способность модели понимать и решать задачи, требующие логического мышления, делая его бесценным активом для задач рассуждения.
Разнообразные контексты реального мира и тщательная проверка
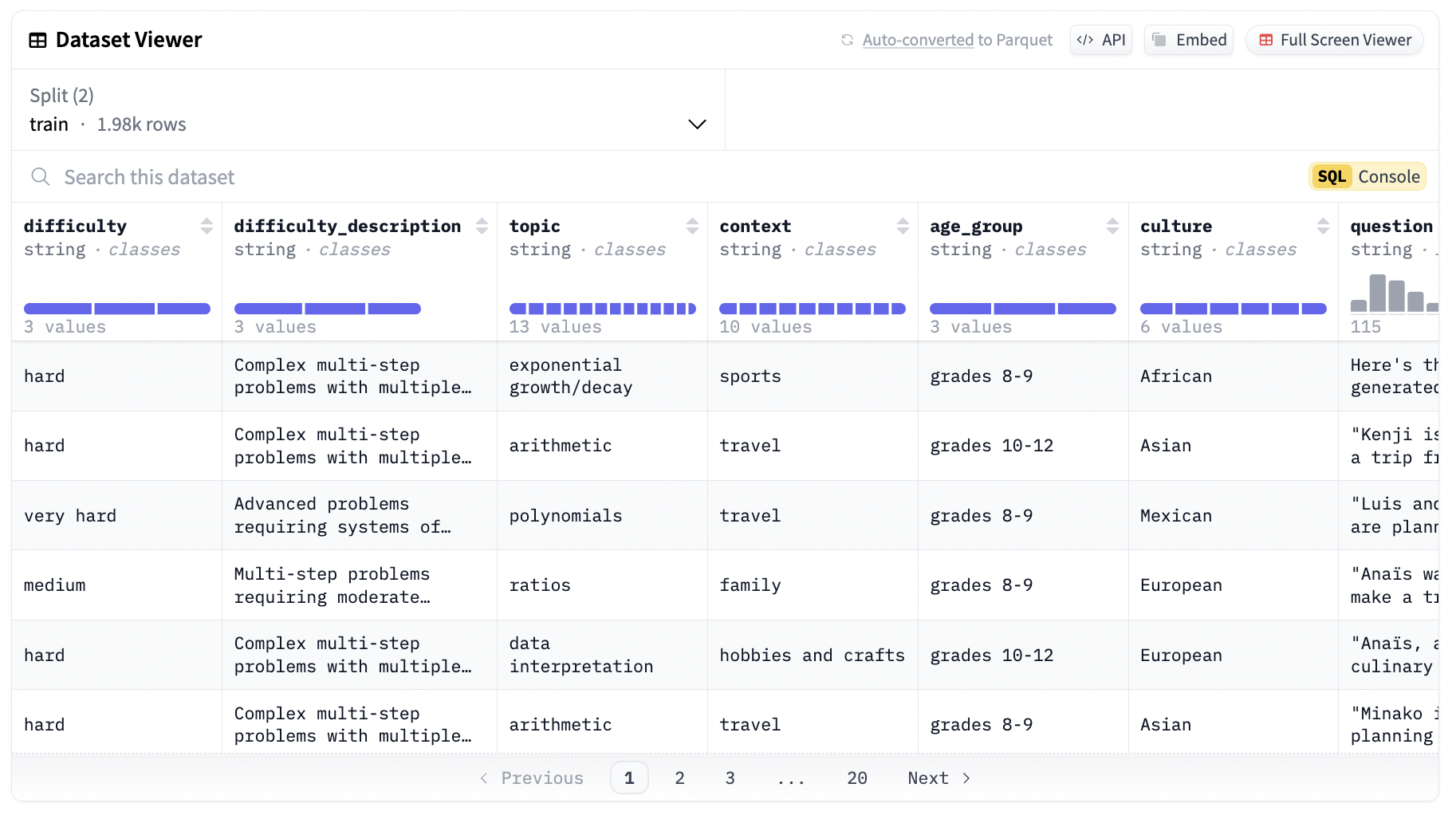
Еще одной ключевой особенностью набора данных Synthetic-GSM8K-reflection-405B является разнообразие его вопросов. Дизайн набора данных обеспечивает стратификацию проблем по сложности и тематике, охватывая широкий спектр реальных контекстов. Это разнообразие делает набор данных высокоуниверсальным и применимым в различных областях, от академических задач до отраслевых сценариев, требующих надежных навыков решения проблем.
Набор данных также выделяется своей тщательно проверенной природой. Все вычисления и процессы решения задач были тщательно проверены с использованием библиотеки sympy Python. Sympy – мощный инструмент для символьной математики, обеспечивающий точность и надежность вычислений в наборе данных. Эта тщательная проверка добавляет дополнительный уровень доверия к набору данных, делая его полезным инструментом для обучения ИИ и надежным для разработки моделей, способных обрабатывать сложные задачи рассуждения с точностью.
Наборы данных для разработки моделей
Набор данных Synthetic-GSM8K-reflection-405B тщательно разработан для поддержки разработки моделей ИИ. Он поставляется как с обучающими, так и тестовыми наборами данных, содержащими в общей сложности 300 примеров. Эти примеры категоризированы по уровням сложности: средний, сложный и очень сложный, обеспечивая возможность моделям, обученным на этом наборе данных, справляться с широким спектром задач рассуждения. Разделение на обучающие и тестовые наборы данных критично для оценки модели. Предоставляя отдельные наборы для обучения и тестирования, набор данных позволяет разработчикам обучать свои модели на одной части данных и оценивать их производительность на другой части. Это разделение помогает оценить, насколько хорошо модель обобщается на невидимые данные, ключевой показатель ее надежности и эффективности.
Потенциальные применения и влияние
Открытие набора данных Synthetic-GSM8K-reflection-405B компанией Gretel.ai готово значительно повлиять на сообщество ИИ и машинного обучения. Его фокус на задачи рассуждения делает его идеальным набором данных для разработки моделей, требующих способности многошагового решения проблем. Эти модели могут быть применены во многих областях, таких как образование, где ИИ может помочь в решении сложных математических задач, или в отраслях, таких как финансы и инженерия, где многошаговое рассуждение критично для процессов принятия решений.
Одним из самых захватывающих аспектов этого набора данных является его способность улучшить разработку моделей ИИ, способных обрабатывать реальные сценарии. Стратификация набора данных по сложности и тематике охватывает различные контексты, от повседневных проблем до высокоспециализированных вызовов. В результате модели, обученные на этом наборе данных, могут быть применены в различных приложениях, предлагая решения для общих и узкоспециализированных проблем.
Более того, использование техник отражения в наборе данных соответствует растущему тренду разработки ИИ-систем, имитирующих мыслительные процессы человека. Разбивая сложные и вызывающие проблемы на более мелкие шаги и отражаясь на каждом из них, модели, обученные на этом наборе данных, более вероятно предложат точные и эффективные решения. Эта способность особенно важна в областях, где точность и логическое мышление имеют первостепенное значение.
Роль Hugging Face в демократизации ИИ
Открытие набора данных Synthetic-GSM8K-reflection-405B на платформе Hugging Face является еще одним шагом к демократизации ИИ. Hugging Face стал центральным хабом для разработчиков и исследователей ИИ, предлагая доступ к множеству моделей и наборов данных. Предоставляя этот набор данных бесплатно, Gretel.ai способствует коллективной природе развития ИИ, где исследователи и разработчики по всему миру могут получить доступ к существующим ресурсам и развивать их.
Платформа Hugging Face также обеспечивает широкую аудиторию для набора данных, от исследователей ИИ в академии до разработчиков в индустрии. Простота доступа и поддержка надежного обучения и оценки моделей делают эту платформу идеальным местом для размещения этого набора данных. Открытый характер набора данных Synthetic-GSM8K-reflection-405B означает, что разработчики могут использовать его для обучения своих моделей, делиться своими результатами и способствовать развитию возможностей рассуждения ИИ.
Заключение
Набор данных Synthetic-GSM8K-reflection-405B компании Gretel.ai представляет собой значительный прогресс в области ИИ и машинного обучения, особенно в задачах рассуждения. Использование синтетической генерации данных, техник отражения и тщательной проверки обеспечивает его высококачественность для обучения моделей ИИ, способных обрабатывать сложные многошаговые задачи. Открытие этого набора данных на платформе Hugging Face демократизирует развитие ИИ, позволяя исследователям и разработчикам по всему миру получить доступ к этому ценному ресурсу.
Благодаря разнообразным контекстам реального мира и тщательно стратифицированным примерам, набор данных Synthetic-GSM8K-reflection-405B сыграет ключевую роль в улучшении способностей рассуждения моделей ИИ. Будь то в академических исследованиях, отраслевых приложениях или разработке моделей для конкретных задач решения проблем, этот набор данных имеет большой потенциал для развития ИИ-систем, способных мыслить и рассуждать, как люди.
“`









