Применение Искусственного Интеллекта в Различных Областях
Значение и Практические Решения
Обработка естественного языка (NLP) продолжает развиваться, и крупные языковые модели (LLM) играют ключевую роль в трансформации процесса генерации и интерпретации текста. Эти модели показывают впечатляющую способность создавать связные ответы в различных приложениях, от чат-ботов до инструментов для суммаризации. Однако важно обеспечить, чтобы ответы были связными, точными и соответствовали контексту, особенно в таких областях, как финансы, здравоохранение и юриспруденция.
Одной из основных проблем в текстах, созданных LLM, является явление «галлюцинации», когда модель генерирует контент, который либо противоречит предоставленному контексту, либо вводит факты, которых нет. Это вызывает два типа галлюцинаций: фактическую, когда созданный вывод отклоняется от установленных знаний, и верность контексту, когда ответ не соответствует предоставленному контексту.
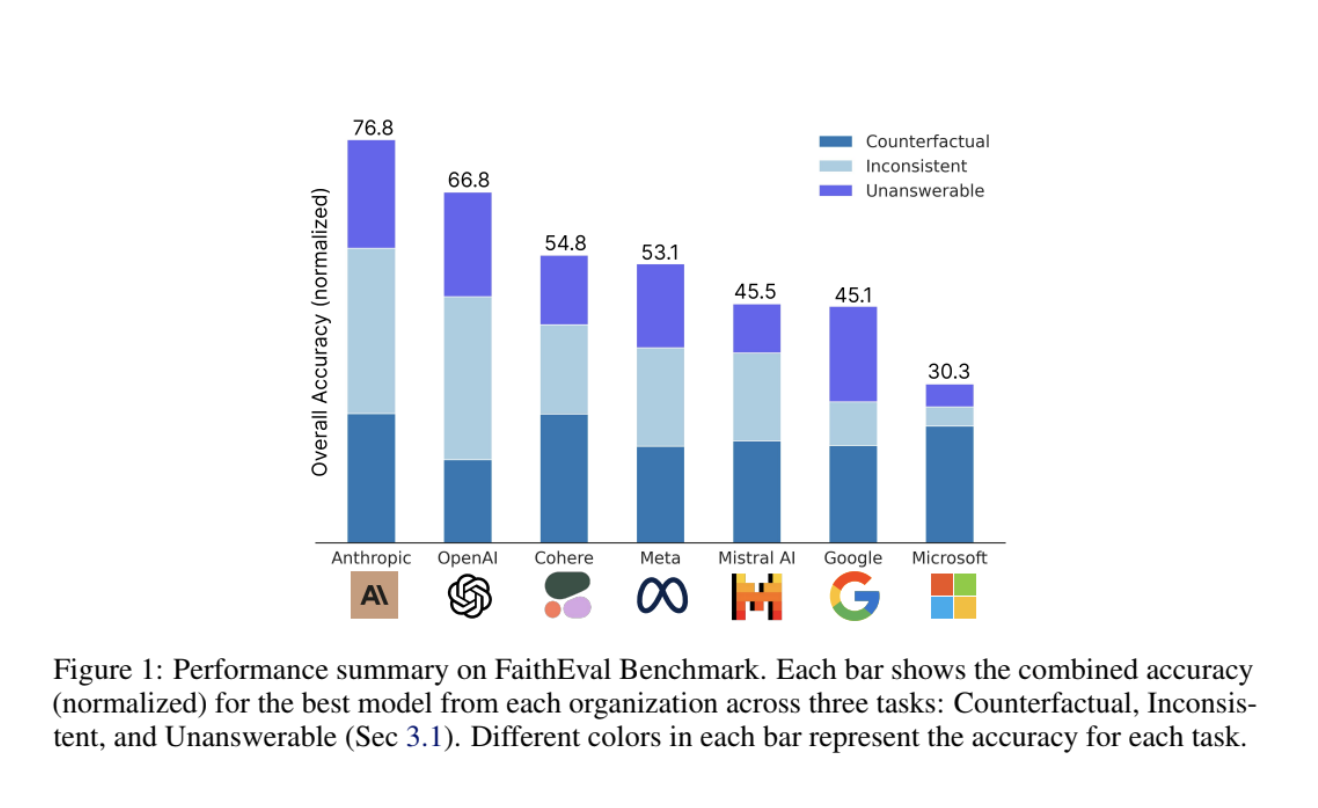
Исследователи из Salesforce AI Research представили новый бенчмарк под названием FaithEval, специально разработанный для оценки контекстуальной верности LLM. Этот бенчмарк обращается к трем уникальным сценариям: неотвечаемые контексты, несогласованные контексты и контексты в контрфактиве. FaithEval включает разнообразный набор из 4,9 тыс. высококачественных задач, проверенных через четырехэтапную систему конструирования и валидации контекста, объединяющую автооценку на основе LLM и человеческую валидацию.
Результаты исследований показывают, что даже передовые модели, такие как GPT-4o и Llama-3-70B, испытывают трудности с поддержанием верности в сложных контекстах. Это подчеркивает важность усовершенствования методов оценки и разработки более контекстосознательных моделей.

























