Оценка надежности крупных языковых моделей (LLMs) в контексте исследования
Практические решения и ценность
Исследование оценивает надежность крупных языковых моделей (LLMs), таких как GPT, LLaMA и BLOOM, широко используемых в различных областях, включая образование, медицину, науку и администрирование. Понимание их ограничений и потенциальных проблем становится ключевым по мере распространения использования этих моделей. Увеличение размера и сложности этих моделей не всегда приводит к улучшению надежности. Вместо этого производительность может снижаться для кажущихся простых задач, что приводит к вводящим в заблуждение результатам, которые могут остаться незамеченными человеческими супервайзерами. Это указывает на необходимость более тщательного изучения надежности LLM за пределами традиционных метрик производительности.
Центральная проблема
Основная проблема, исследуемая в исследовании, заключается в том, что увеличение масштаба LLM делает их более мощными, но также вводит неожиданные поведенческие шаблоны. Эти модели могут становиться менее стабильными и производить ошибочные результаты, которые на первый взгляд кажутся правдоподобными. Это происходит из-за использования настройки на инструкции, обратной связи от людей и обучения с подкреплением для улучшения их производительности. Несмотря на эти достижения, LLM имеют проблемы с поддержанием надежности на различных по сложности задачах, что вызывает опасения относительно их надежности и пригодности для приложений, где важны точность и предсказуемость.
Существующие методологии
Существующие методы для решения этих проблем надежности включают увеличение масштаба моделей, что включает увеличение параметров, данных для обучения и вычислительных ресурсов. Например, размер моделей GPT-3 варьируется от 350 миллионов до 175 миллиардов параметров, в то время как модели LLaMA варьируются от 6,7 миллиарда до 70 миллиардов. Хотя увеличение масштаба привело к улучшениям в обработке сложных запросов, оно также вызвало сбои в более простых случаях, которые пользователи ожидали бы, что будут легко управляемыми. А также формирование моделей с использованием таких техник, как обучение с подкреплением от обратной связи человека, показало разнообразные результаты, часто приводя к моделям, которые генерируют правдоподобные, но неверные ответы вместо простого избегания вопроса.
Результаты исследования
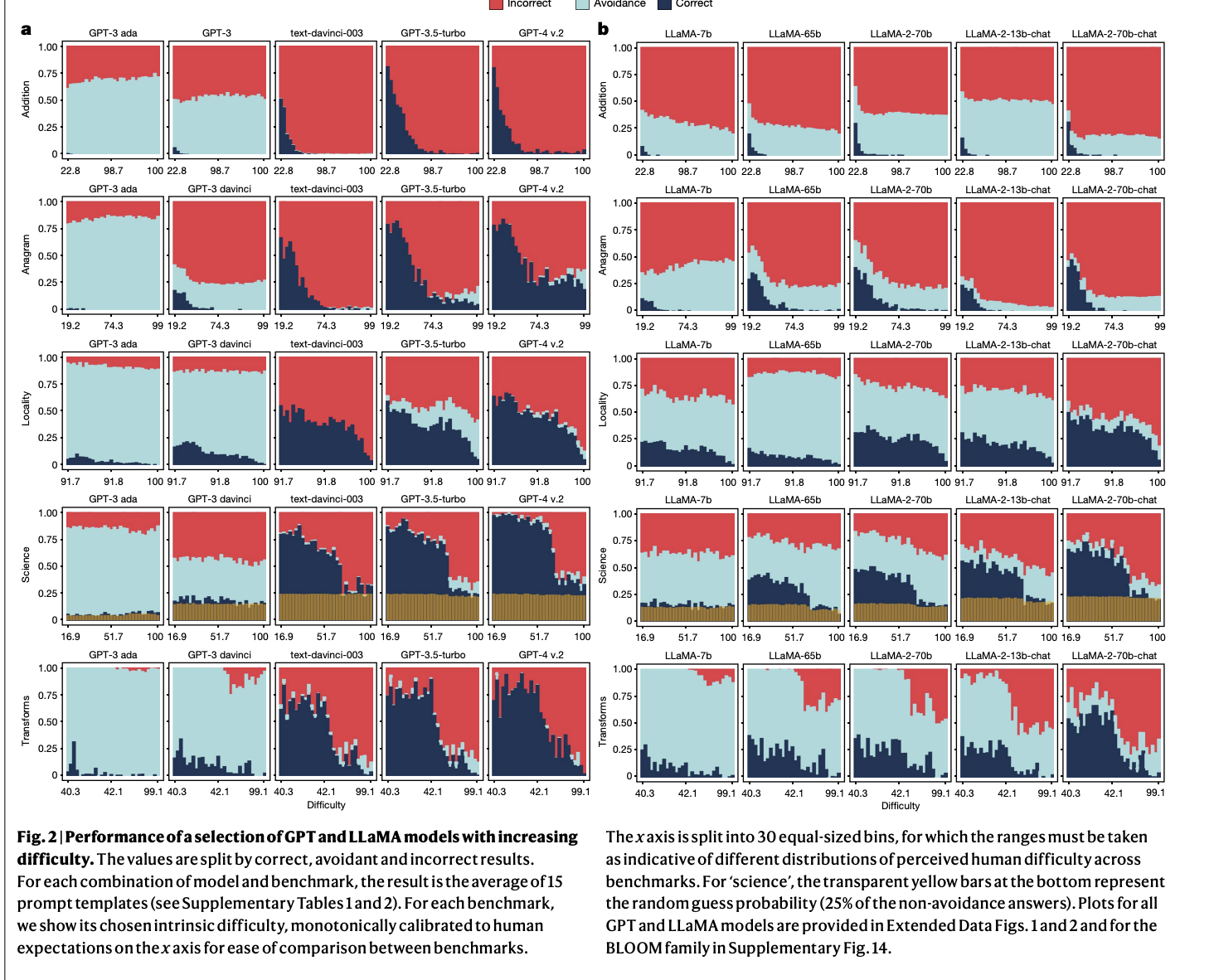
Исследование показывает, что стратегии увеличения масштаба и формирования улучшают производительность LLM на сложных вопросах, но часто ухудшают надежность для более простых. Например, модели, такие как GPT-4 и LLaMA-2, которые отлично справляются с ответами на сложные научные вопросы, все равно допускают базовые ошибки в простых арифметических или перестановочных задачах. Кроме того, производительность LLaMA-2 на вопросах географических знаний, измеряемых с использованием бенчмарка местоположений, указала на высокую чувствительность к небольшим изменениям в формулировке запроса. В результате модели демонстрировали значительную точность для известных городов, но испытывали затруднения при работе с менее популярными местами, что привело к уровню ошибок в 91,7% для городов, не входящих в топ-10% по населению.
Заключение
Исследование подчеркивает необходимость сдвига парадигмы в проектировании и разработке LLM. Предложенная методология оценки ReliabilityBench переходит от общих показателей производительности к более тонкой оценке поведения модели на основе уровней сложности для человека. Этот подход позволяет характеризовать надежность модели, открывая путь для будущих исследований, сосредоточенных на обеспечении последовательной производительности на всех уровнях сложности. Результаты показывают, что несмотря на достижения, LLM пока не достигли уровня надежности, соответствующего ожиданиям людей, что делает их подверженными неожиданным сбоям, которые необходимо решать с помощью улучшенных стратегий обучения и оценки.