“`html
Кодогенерация: новые методы создания качественных наборов данных
Кодогенерация – область, которая направлена на улучшение процессов разработки программного обеспечения путем создания инструментов, способных автоматически генерировать, интерпретировать и отлаживать код. Эти инструменты повышают эффективность и уменьшают ошибки программирования, что крайне важно для современной разработки программного обеспечения. Прогресс в этой области имеет потенциал значительно повлиять на то, как пишется, тестируется и поддерживается программное обеспечение.
Проблема создания качественных наборов данных для обучения языковых моделей в кодогенерации
Традиционные методы создания наборов данных затратны и времязатратны, часто требуют ручной аннотации или дорогостоящих закрытых моделей. Эта зависимость ограничивает доступность и масштабируемость разработки мощных инструментов кодогенерации, поскольку ручная аннотация больших наборов данных трудоемка и экономически затратна.
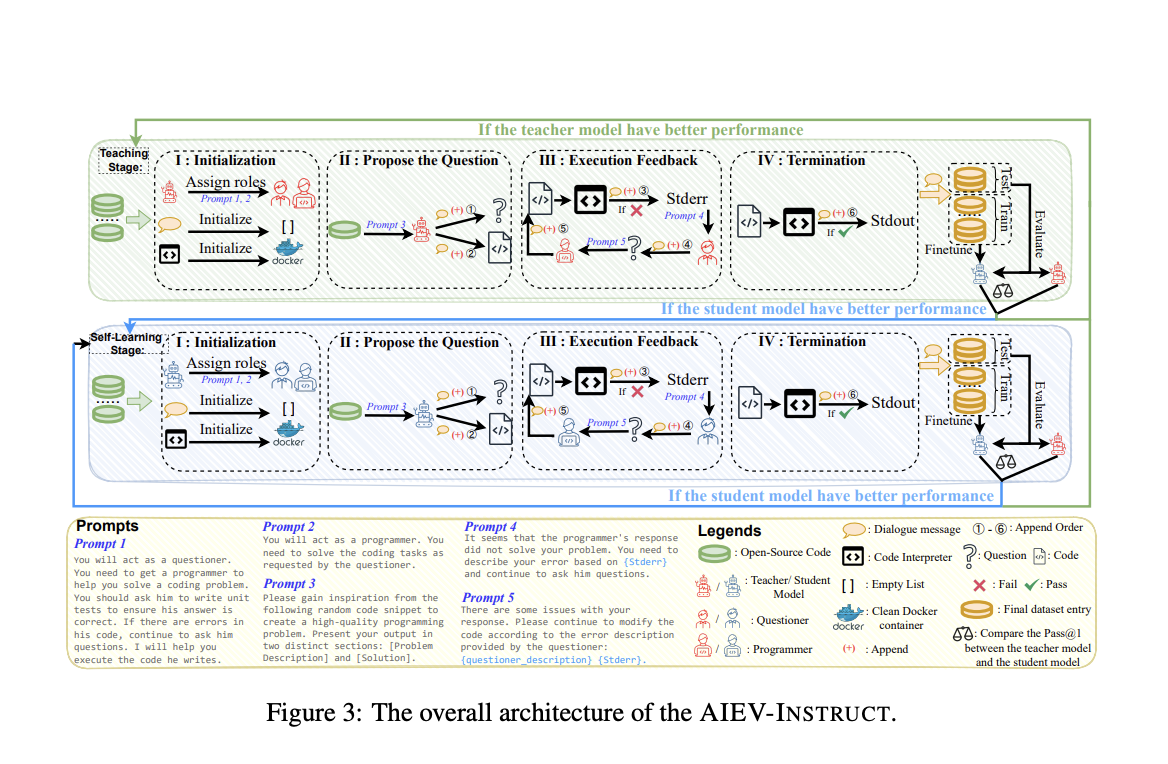
Новый метод – AIEV-INSTRUCT
Исследователи из Университета Коннектикут и AIGCode предложили новый метод под названием AIEV-INSTRUCT, который создает высококачественный набор данных по коду через интерактивный процесс, включающий двух агентов – опрашивающего и программиста – которые моделируют диалоги по кодированию и тестированию. Этот инновационный подход не только решает ограничения существующих методов, но также повышает надежность и точность сгенерированных наборов данных.
Двухэтапный процесс AIEV-INSTRUCT
AIEV-INSTRUCT работает в двух этапах: В этапе обучения используется закрытая модель GPT-4 Turbo для создания и проверки кодовых инструкций. После того как модель-учитель превзойдена моделью-учеником в точности, происходит переход к этапу самообучения, где модель-ученик автономно генерирует и проверяет код.
Превосходство модели AutoCoder
Модель AutoCoder, обученная с помощью AIEV-INSTRUCT, показала впечатляющие результаты, превзойдя существующие модели в ключевых тестах. Это улучшает эффективность задач кодогенерации и предоставляет масштабируемый подход для улучшения языковых моделей в приложениях кодирования. Модель AutoCoder демонстрирует превосходную производительность и способность интерпретации кода, что значительно расширяет ее применимость в реальных сценариях разработки программного обеспечения.
Вывод
Исследование представляет значительное достижение в области кодогенерации, предлагая эффективный и точный метод создания наборов данных по кодированию. Модель AutoCoder, использующая метод AIEV-INSTRUCT, превзошла существующие модели в ключевых тестах. Это улучшение повышает эффективность задач кодогенерации и предоставляет масштабируемый подход к улучшению языковых моделей в разработке программного обеспечения. Вклад Университета Коннектикут и AIGCode демонстрирует потенциал значительных улучшений в процессах разработки программного обеспечения, делая мощные инструменты кодогенерации более доступными и эффективными для разработчиков по всему миру.
“`









