“`html
Методологии Text-to-SQL на основе глубокого обучения
Существующие методологии Text-to-SQL в основном полагаются на модели глубокого обучения, в частности, на модели Sequence-to-Sequence (Seq2Seq), которые стали основными благодаря их способности прямого сопоставления естественного языка с SQL без промежуточных этапов. Эти модели, усиленные предварительно обученными языковыми моделями (PLM), устанавливают современные стандарты в этой области, используя масштабные корпусы для улучшения своих языковых способностей. Однако переход к моделям с большим количеством параметров обещает еще более высокую производительность благодаря их законам масштабирования и вновь появившимся возможностям. Эти модели, с их значительным количеством параметров, способны захватывать сложные шаблоны в данных, что делает их подходящими для задачи Text-to-SQL.
Применение LLM для задачи Text-to-SQL
Новая научная работа из Пекинского университета решает проблему преобразования естественных языковых запросов в SQL-запросы, процесс, известный как Text-to-SQL. Это преобразование критично для создания баз данных доступными для неспециалистов, которые могут не знать SQL, но нуждаются во взаимодействии с базами данных для извлечения информации. Врожденная сложность синтаксиса SQL и тонкости понимания схемы базы данных делают эту задачу значительной проблемой в обработке естественного языка (NLP) и управлении базами данных.
Стратегии использования LLM для задач Text-to-SQL
Предложенный метод в этой работе использует LLM для задач Text-to-SQL через две основные стратегии: инженерия подсказок и настройка. Инженерия подсказок включает в себя такие техники, как Retrieval-Augmented Generation (RAG), обучение с малым количеством данных и рассуждения, которые требуют меньше данных, но могут давать оптимальные результаты не всегда. С другой стороны, настройка LLM с заданными данными может существенно улучшить производительность, но требует большого набора данных для обучения. В работе исследуется баланс между этими подходами с целью найти оптимальную стратегию, максимизирующую производительность LLM в генерации точных SQL-запросов из естественных языковых вводов.
Многошаговые логические шаблоны
В работе рассматриваются различные многошаговые логические шаблоны, которые могут быть применены к LLM для задачи Text-to-SQL. Это включает Chain-of-Thought (CoT), который направляет LLM на шаг-за-шагом генерацию ответов, добавляя конкретные подсказки для разбиения задачи на более простые; Least-to-Most, который разбивает сложную проблему на более простые подпроблемы; и Self-Consistency, который использует стратегию мажоритарного голосования для выбора наиболее часто встречающегося ответа, сгенерированного LLM. Каждый метод помогает LLM генерировать более точные SQL-запросы, имитируя человеческий подход к решению сложных проблем пошагово и итеративно.
Производительность и значимость
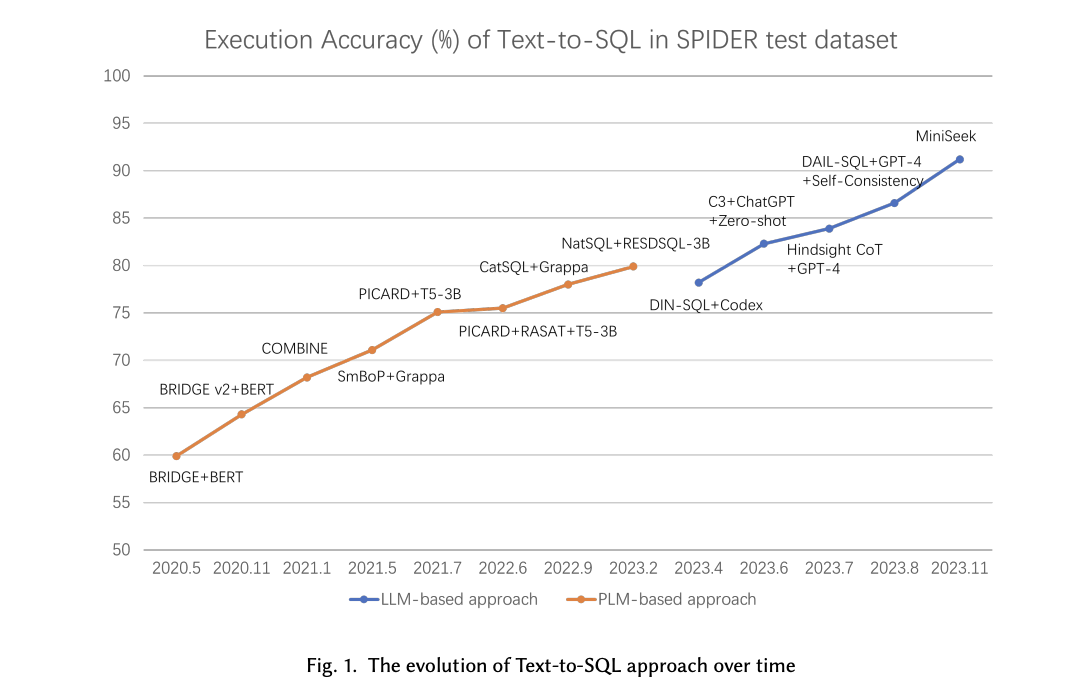
Работа подчеркивает, что применение LLM значительно улучшило точность выполнения задач Text-to-SQL. Например, точность состояния искусства на бенчмарк-наборах данных, таких как Spider, выросла с примерно 73% до 91,2% с использованием LLM. Однако остаются некоторые вызовы, особенно с появлением новых наборов данных, таких как BIRD и Dr.Spider, представляющих более сложные сценарии и тесты на устойчивость. Исследования указывают, что даже продвинутые модели, такие как GPT-4, все еще испытывают трудности с определенными возмущениями, достигая только 54,89% точности на наборе данных BIRD. Это подчеркивает необходимость дальнейших исследований и разработок в этой области.
Работа предоставляет полный обзор применения LLM для задач Text-to-SQL, выделяя потенциал многошаговых логических шаблонов и стратегий настройки для улучшения производительности. Решение проблемы преобразования естественного языка в SQL проложило путь к более доступному и эффективному взаимодействию с базами данных для неспециалистов. Предложенные методы и детальные оценки демонстрируют значительные достижения в этой области, обещая более точные и эффективные решения для прикладных задач. Эта работа продвигает современные стандарты в области Text-to-SQL и подчеркивает важность использования возможностей LLM для сокращения разрыва между пониманием естественного языка и запросами к базам данных.
Источник: MarkTechPost
“`
“`html
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Transforming Database Access: The LLM-based Text-to-SQL Approach.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
“`









