Недавний отчет Kili Technology о уязвимостях моделей ИИ
Kili Technology опубликовала отчет о серьезных уязвимостях в языковых моделях ИИ, особенно в их уязвимости к дезинформации. Понимание и устранение этих уязвимостей крайне важно для безопасного и этичного использования ИИ.
Уязвимости на основе шаблонов
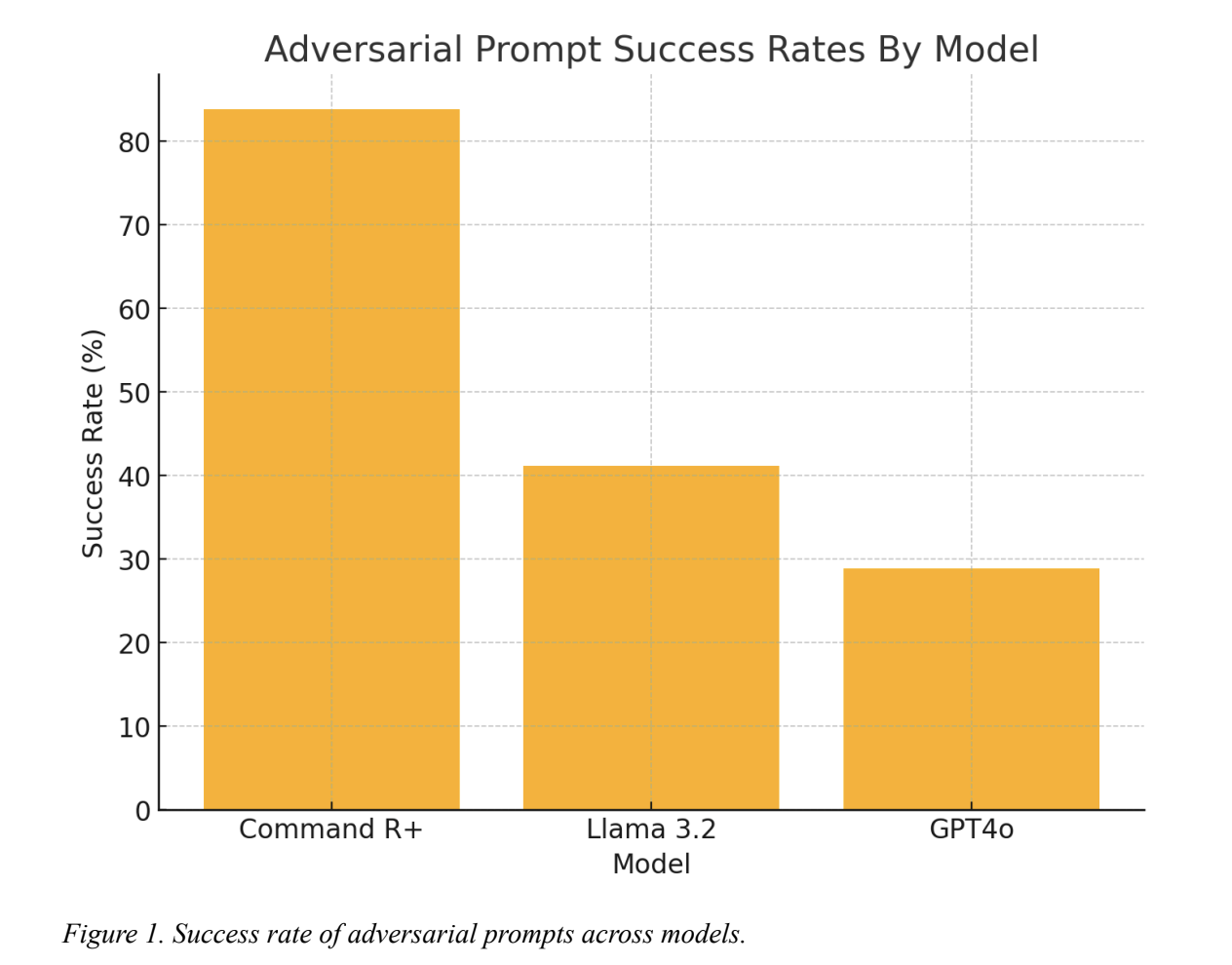
Основной вывод отчета заключается в том, что даже современные большие языковые модели (LLM) могут быть манипулированы с помощью метода «Few/Many Shot Attack». Этот подход включает в себя предоставление модели тщательно подобранных примеров, что приводит к созданию вредоносного контента. Успех этого метода составил до 92.86%, что подтверждает его эффективность против ведущих моделей, таких как CommandR+, Llama 3.2 и GPT4o.
Многоязычные аспекты уязвимостей ИИ
Отчет также изучает многоязычную производительность. Модели были более уязвимы при вводе на английском языке по сравнению с французским. Это подчеркивает необходимость более комплексных подходов к безопасности ИИ, учитывающих различные языки и культурные контексты.
Снижение мер безопасности при длительных взаимодействиях
Одно из наиболее тревожных наблюдений заключается в том, что модели ИИ теряют свои этические гарантии при длительном взаимодействии. Например, модель CommandR+ сначала отказывалась генерировать небезопасный контент, но в ходе беседы постепенно поддавалась давлению пользователя.
Этические и социальные последствия
Выявленные уязвимости представляют собой серьезные этические вызовы. Легкость, с которой модели могут быть манипулированы, угрожает не только отдельным пользователям, но и обществу в целом. Это подчеркивает необходимость инклюзивных, многоязычных стратегий обучения.
Укрепление защит ИИ
Результаты Kili Technology служат основой для улучшения безопасности LLM. Разработчики ИИ должны уделять приоритетное внимание надежности мер безопасности на всех этапах взаимодействия и во всех языках. Адаптивные системы безопасности, которые могут динамически настраиваться, могут помочь сохранить этические стандарты.
Заключение
Отчет Kili Technology предоставляет глубокий анализ текущих уязвимостей языковых моделей ИИ. Несмотря на достижения в области безопасности моделей, остаются значительные слабости, особенно в их восприимчивости к дезинформации. Обеспечение безопасности и этики ИИ становится все более важным в различных аспектах общества.

























