«`html
Создание пользовательского токенизатора с помощью библиотеки tiktoken
В этом руководстве мы научимся создавать пользовательский токенизатор с использованием библиотеки tiktoken. Этот процесс включает в себя:
- Загрузку предобученной модели токенизатора.
- Определение базовых и специальных токенов.
- Инициализацию токенизатора с помощью регулярного выражения для разделения токенов.
- Тестирование его функциональности на примере текста.
Эта настройка необходима для задач обработки естественного языка (NLP), требующих точного контроля над токенизацией текста.
Импорт библиотек
Импортируем необходимые библиотеки для обработки текста и машинного обучения:
- Path из pathlib для удобного управления путями к файлам.
- tiktoken и load_tiktoken_bpe для работы с токенизатором на основе кодирования пар байтов (BPE).
Настройка токенизатора
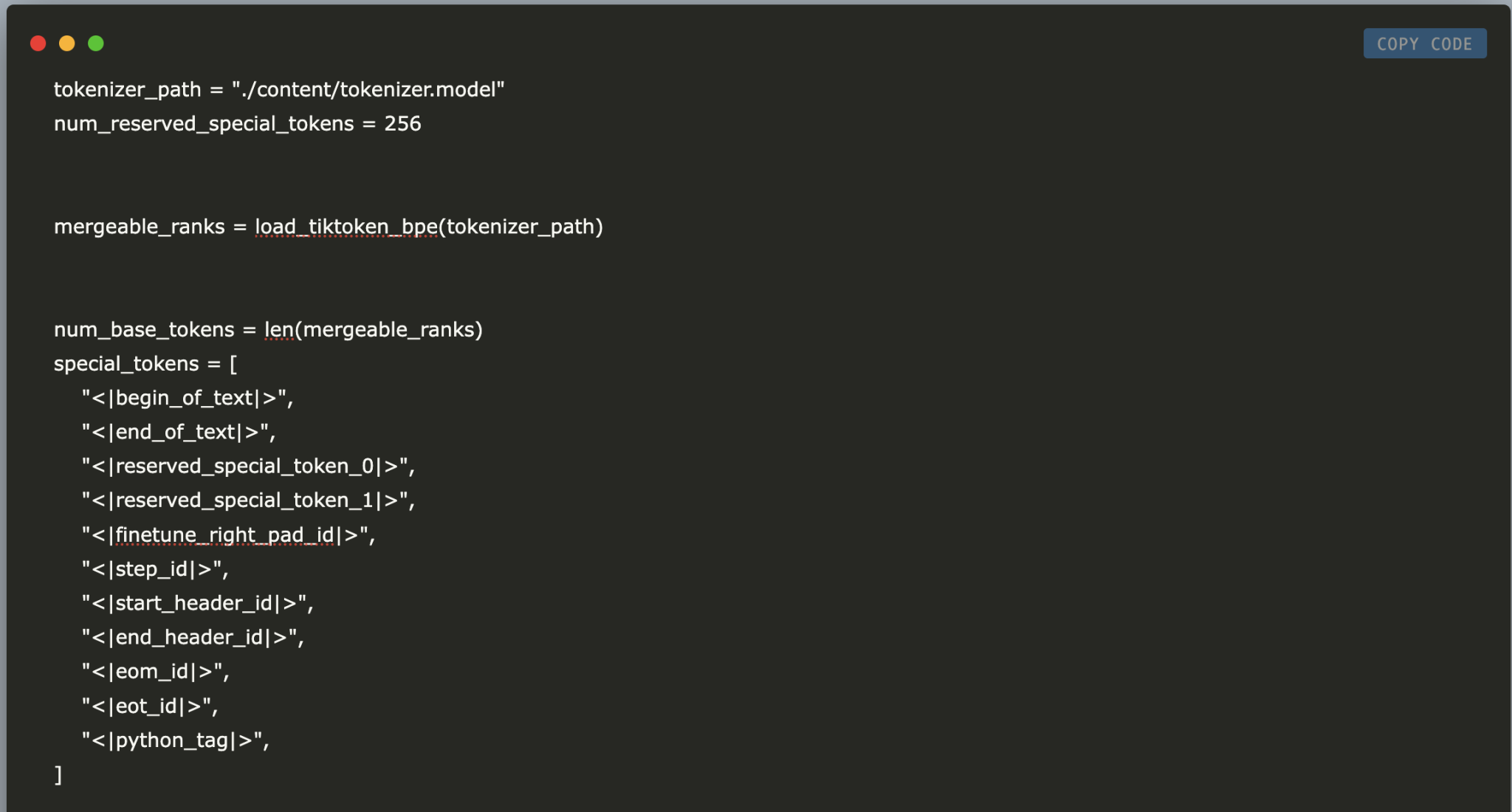
Устанавливаем путь к модели токенизатора и определяем 256 зарезервированных специальных токенов:
tokenizer_path = "./content/tokenizer.model" num_reserved_special_tokens = 256
Загружаем сливаемые ранги, которые формируют базовый словарь, и определяем список специальных токенов для обозначения границ текста.
Создание и инициализация токенизатора
Динамически создаем дополнительные зарезервированные токены и инициализируем токенизатор:
tokenizer = tiktoken.Encoding(
name=Path(tokenizer_path).name,
pat_str=r"(?i:'s|'t|'re|'ve|'m|'ll|'d)|[^rnp{L}p{N}]?p{L}+|p{N}{1,3}| ?[^sp{L}p{N}]+[rn]*|s*[rn]+|s+(?!S)|s+",
mergeable_ranks=mergeable_ranks,
special_tokens={token: len(mergeable_ranks) + i for i, token in enumerate(special_tokens)},
)
Это позволяет нам точно контролировать процесс токенизации текста.
Тестирование токенизатора
Тестируем токенизатор на примере текста:
sample_text = "Hello, this is a test of the updated tokenizer!" encoded = tokenizer.encode(sample_text) decoded = tokenizer.decode(encoded)
Выводим оригинальный текст, закодированные токены и декодированный текст для проверки корректности работы токенизатора.
Заключение
Следуя этому руководству, вы научитесь настраивать пользовательский BPE токенизатор с помощью библиотеки TikToken. Вы увидели, как загрузить предобученную модель токенизатора, определить базовые и специальные токены, а также инициализировать токенизатор с использованием регулярного выражения. Наконец, вы проверили функциональность токенизатора, закодировав и декодировав пример текста.
Как ИИ может помочь вашему бизнесу
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), используйте этот подход для создания токенизатора.
- Анализируйте, как ИИ может изменить вашу работу.
- Определите области для автоматизации.
- Выберите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
Подберите подходящее решение и внедряйте ИИ постепенно, начиная с небольших проектов и анализируя результаты.
Получите помощь по внедрению ИИ
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистент в продажах, который помогает отвечать на вопросы клиентов и генерировать контент для отдела продаж.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























