«`html
Как преобразовать неструктурированный текст в действенные знания?
Построение графов знаний (Knowledge Graphs, KGs) из неструктурированных данных является сложной задачей из-за трудностей извлечения и структурирования значимой информации из сырого текста. Неструктурированные данные часто содержат неразрешенные или дублированные сущности и несогласованные отношения, что затрудняет их преобразование в согласованный граф знаний. Кроме того, огромное количество неструктурированных данных в различных областях подчеркивает необходимость масштабируемых методов для автоматической обработки, извлечения и структурирования этих данных в графы знаний. Успешное преодоление этих проблем критически важно для обеспечения эффективного рассуждения, выводов и принятия решений на основе данных в областях от научных исследований до анализа веб-данных.
Традиционные методы построения графов знаний из неструктурированного текста в основном полагаются на такие техники, как распознавание именованных сущностей, извлечение отношений и разрешение сущностей. Эти подходы часто ограничиваются необходимостью заранее определенных типов сущностей и отношений, часто зависящих от онтологий, специфичных для области. Кроме того, они обычно включают надзорное обучение, требующее большого количества аннотированных данных. Существенным ограничением этих методов является их склонность к созданию несогласованных графов с дублированными или неразрешенными сущностями, что приводит к избыточности и неоднозначностям, требующим обширной последующей обработки. Кроме того, многие существующие решения зависят от тематики, что ограничивает их применимость в различных областях, что снижает их масштабируемость и адаптивность к новым случаям использования.
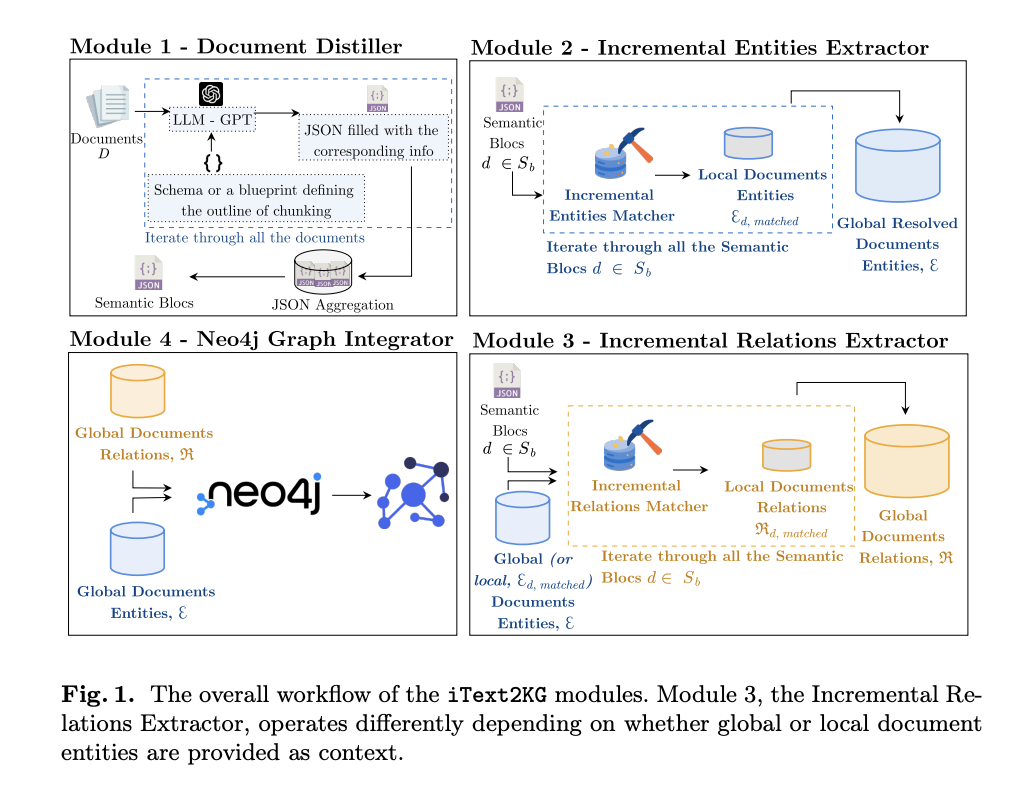
Исследователи из INSA Lyon, CNRS и Universite Claude Bernard Lyon 1 представляют iText2KG, нулевой метод, независимый от темы, для пошагового построения графов знаний (KGs) из неструктурированных данных без необходимости заранее определенных онтологий или последующей обработки. Эта структура состоит из четырех отдельных модулей:
1. Document Distiller: Преобразует сырые документы в семантические блоки с использованием больших языковых моделей (LLMs), управляемых гибкой, определенной пользователем схемой.
2. Incremental Entity Extractor: Извлекает уникальные сущности из семантических блоков, обеспечивая отсутствие дублирования или семантических неоднозначностей.
3. Incremental Relation Extractor: Идентифицирует и извлекает семантически уникальные отношения между сущностями.
4. Graph Integrator: Визуализирует сущности и отношения в KG с использованием Neo4j, обеспечивая структурированное представление данных.
Этот модульный дизайн разделяет задачи извлечения сущностей и отношений, что приводит к улучшению точности и согласованности. Более того, использование парадигмы нулевого обучения обеспечивает адаптивность в различных областях без необходимости тонкой настройки или повторного обучения, делая его гибким, точным и масштабируемым решением для построения KG.
iText2KG обрабатывает документы пошагово, проходя через свои четыре основных модуля. Во-первых, модуль Document Distiller перестраивает сырой текст в семантические блоки на основе гибкой, определенной пользователем схемы, которая может быть адаптирована к различным типам документов, таким как научные статьи, резюме или веб-сайты. Затем эти семантические блоки подаются на вход Incremental Entity Extractor, который идентифицирует и гарантирует уникальность каждой сущности, разрешая потенциальные неоднозначности с использованием мер подобия, таких как косинусное сходство.
Затем Incremental Relation Extractor извлекает отношения между идентифицированными сущностями, используя как локальные, так и глобальные контексты документов для обеспечения точности отношений. Наконец, Graph Integrator объединяет эти сущности и отношения в визуальный граф знаний с использованием Neo4j, обеспечивая согласованное и структурированное представление данных. Производительность системы была протестирована на различных типах документов, демонстрируя ее универсальность в различных случаях использования без необходимости повторного обучения.
iText2KG продемонстрировал превосходную производительность по сравнению с базовыми методами, особенно в согласованности схемы, точности извлечения троек и разрешения сущностей/отношений. Система достигла высокой согласованности в структурировании информации из различных типов документов, таких как научные статьи, веб-сайты и резюме. Точность извлечения соответствующих отношений была заметно высокой при использовании локальных сущностей, обеспечивая минимальное количество ошибок в графе знаний. Кроме того, подход продемонстрировал низкий уровень ложных обнаружений в разрешении сущностей и отношений, особенно с структурированными документами, такими как научные статьи. В целом iText2KG оказался эффективным в построении точных и согласованных графов знаний в различных областях, адаптируясь к различным типам данных без необходимости обширной тонкой настройки или последующей обработки.
В заключение, iText2KG представляет собой значительный прогресс в построении графов знаний, предоставляя гибкий, нулевой подход, способный структурировать неструктурированные данные в согласованные, независимые от темы графы знаний. Модульность задач извлечения сущностей и отношений и применение пошагового процесса позволяет этому методу преодолеть ключевые ограничения традиционных подходов, такие как зависимость от заранее определенных онтологий и обширной последующей обработки. С превосходной производительностью на различных типах документов iText2KG обладает огромным потенциалом для широкого применения в областях, требующих структурированные знания из неструктурированного текста, предлагая надежное, масштабируемое и эффективное решение для построения графов знаний.
«`

























