Исследование машинного обучения от Стэнфордского университета и Университета Торонто предлагает наблюдательные законы масштабирования: выявляется удивительная предсказуемость сложных явлений масштабирования
Модели языка (LMs) являются основой исследований в области искусственного интеллекта, сосредоточенных на способности понимать и генерировать человеческий язык. Разработчики стремятся улучшить эти модели для выполнения различных сложных задач, включая обработку естественного языка, перевод и творческое письмо. Это направление изучает, как LMs учатся, адаптируются и масштабируют свои возможности с увеличением вычислительных ресурсов. Понимание этих масштабируемых характеристик является важным для прогнозирования будущих возможностей и оптимизации ресурсов, необходимых для обучения и развертывания этих моделей.
Основные вызовы в исследовании моделей языка
Основное препятствие в исследовании моделей языка заключается в понимании того, как производительность модели масштабируется в зависимости от объема вычислительной мощности и данных, используемых во время обучения. Это масштабирование является ключевым для прогнозирования будущих возможностей и оптимизации использования ресурсов. Традиционные методы требуют обширного обучения на различных уровнях, что является вычислительно затратным и занимает много времени. Это создает значительное препятствие для многих исследователей и инженеров, которым необходимо понять эти взаимосвязи для улучшения разработки и применения моделей.
Практические решения и ценность
Существующие исследования включают различные фреймворки и модели для понимания производительности моделей языка. Значимы среди них законы масштабирования вычислений, которые анализируют отношение между вычислительными ресурсами и возможностями моделей. Инструменты, такие как Open LLM Leaderboard, LM Eval Harness, и бенчмарки, такие как MMLU, ARC-C и HellaSwag, широко используются. Кроме того, модели, такие как LLaMA, GPT-Neo и BLOOM, предоставляют разнообразные примеры того, как законы масштабирования могут быть применены. Эти фреймворки и бенчмарки помогают исследователям оценивать и оптимизировать производительность моделей языка на различных вычислительных уровнях и задачах.
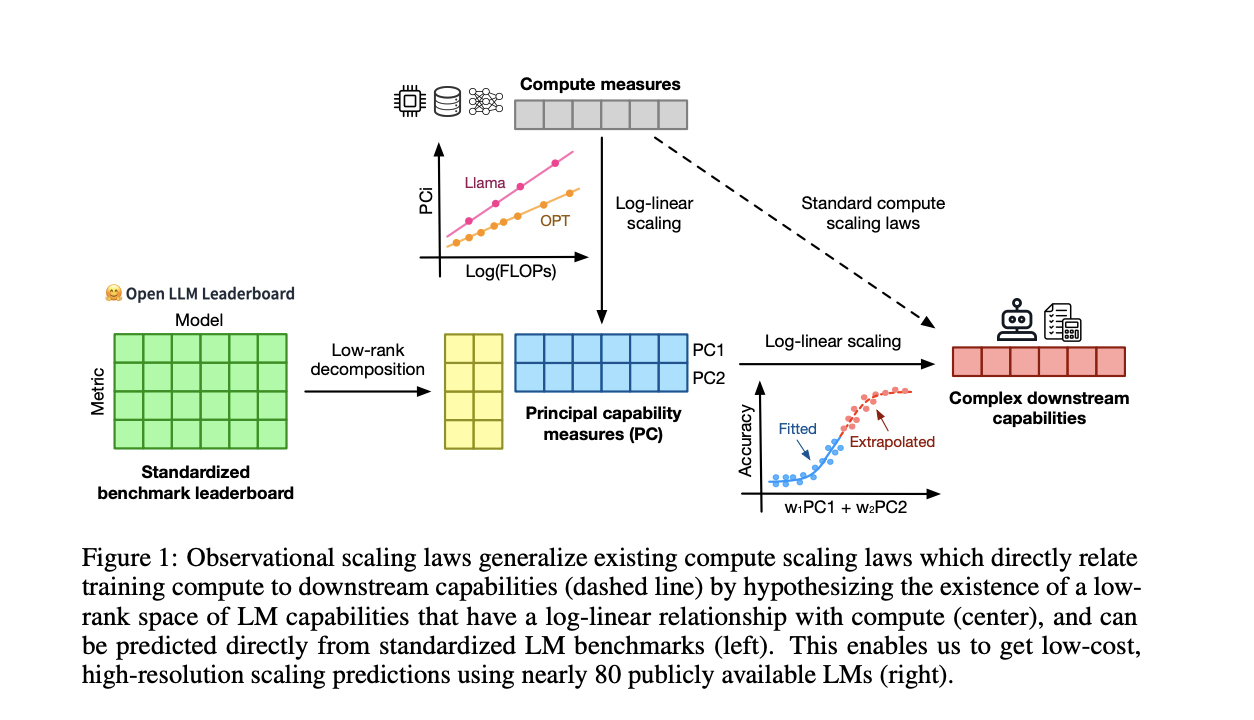
Исследователи из Стэнфордского университета, Университета Торонто и Института Vector представили наблюдательные законы масштабирования для улучшения прогнозирования производительности моделей языка. Этот метод использует публично доступные модели для создания законов масштабирования, сокращая необходимость в обширном обучении. За счет использования существующих данных от приблизительно 80 моделей исследователи смогли создать обобщенный закон масштабирования, учитывающий изменения в эффективности обучения вычислительных ресурсов. Этот инновационный подход предлагает экономически эффективный и эффективный способ прогнозирования производительности модели на различных уровнях и возможностях, выделяя его из традиционных методов масштабирования.
Методология анализирует данные о производительности приблизительно 80 публично доступных моделей языка, включая Open LLM Leaderboard и стандартизированные бенчмарки, такие как MMLU, ARC-C и HellaSwag. Исследователи предположили, что производительность модели может быть отображена в пространство возможностей низкой размерности. Они разработали обобщенный закон масштабирования, исследуя изменения в эффективности обучения вычислительных ресурсов среди различных семейств моделей. Этот процесс включал использование метода анализа главных компонент (PCA) для выявления ключевых показателей возможностей и подгонки этих показателей в логарифмическую зависимость от вычислительных ресурсов, обеспечивая точные и высокоразрешенные прогнозы производительности.
Исследование продемонстрировало значительный успех наблюдательных законов масштабирования. Например, используя более простые модели, метод точно предсказал производительность продвинутых моделей, таких как GPT-4. Количественно законы масштабирования показали высокую корреляцию (R² > 0,9) с фактической производительностью на различных бенчмарках. Возникающие явления, такие как понимание языка и способности к рассуждению, следовали предсказуемому сигмоидальному образцу. Результаты также указывали на то, что воздействие пост-тренировочных вмешательств, таких как Chain-of-Thought и Self-Consistency, можно надежно предсказать, показывая улучшение производительности до 20% в конкретных задачах.
В заключение, исследование представляет наблюдательные законы масштабирования, используя публично доступные данные от примерно 80 моделей для эффективного прогнозирования производительности модели языка. Путем определения пространства возможностей низкой размерности и использования обобщенных законов масштабирования, исследование сокращает необходимость в обширном обучении модели. Результаты показали высокую предсказательную точность для производительности продвинутых моделей и пост-тренировочных вмешательств. Этот подход экономит вычислительные ресурсы и улучшает возможность прогнозирования возможностей модели, предоставляя ценный инструмент для исследователей и инженеров в оптимизации разработки модели языка.
Проверьте Статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, серверу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 42 тысячами подписчиков.
Этот пост был опубликован на MarkTechPost.
Предложение консультаций по внедрению ИИ в ваш бизнес
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте This Machine Learning Paper from Stanford and the University of Toronto Proposes Observational Scaling Laws: Highlighting the Surprising Predictability of Complex Scaling Phenomena.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru

























