Гибкая система визуальной памяти для гибкой классификации изображений
Глубокие модели обучения обычно представляют знания статически, что затрудняет их адаптацию к изменяющимся потребностям данных и концепций. Эта жесткость требует частого повторного обучения или тонкой настройки для интеграции новой информации, что может быть не очень практично.
Исследовательская статья “К гибкому восприятию с визуальной памятью” Гейрхоса и др. представляет инновационное решение, которое интегрирует символическую силу глубоких нейронных сетей с адаптивностью базы данных визуальной памяти. Путем разложения классификации изображений на сходство изображений и быстрый поиск ближайших соседей авторы представляют гибкую визуальную память, способную без проблем добавлять и удалять данные.
Практические решения и ценность
Текущие методы классификации изображений часто полагаются на статические модели, требующие повторного обучения для интеграции новых классов или наборов данных. Традиционные методы агрегации, такие как плюрализм и голосование softmax, могут привести к чрезмерной уверенности в прогнозах, особенно при рассмотрении дальних соседей.
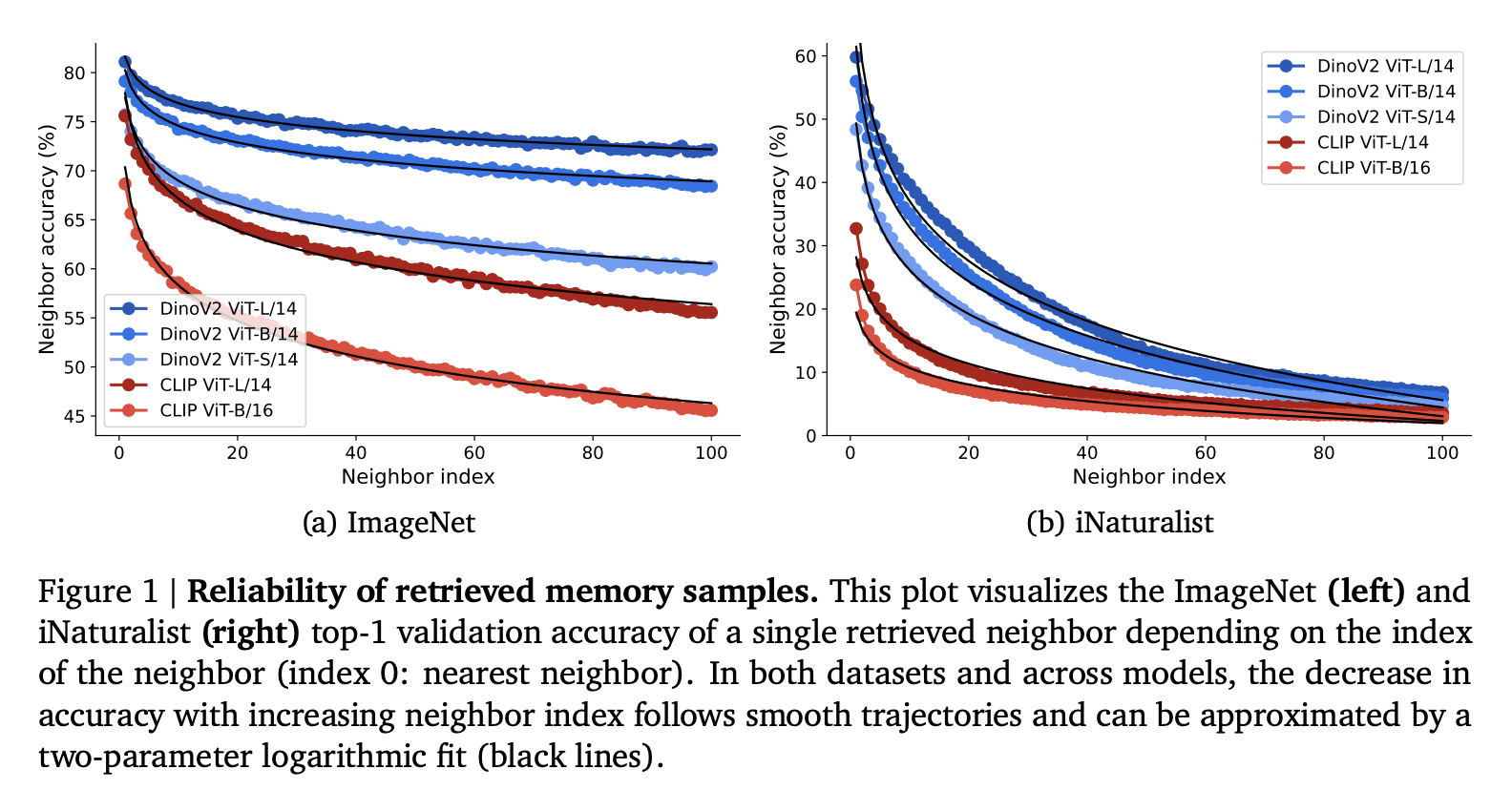
Авторы предлагают систему визуальной памяти на основе поиска, которая создает базу данных пар признак-метка, извлеченных из предварительно обученного кодера изображений, такого как DinoV2 или CLIP. Эта система позволяет быструю классификацию путем извлечения k ближайших соседей на основе косинусного сходства, позволяя модели адаптироваться к новым данным без повторного обучения.
Методология состоит из двух основных шагов: создание визуальной памяти и выполнение вывода на основе ближайших соседей. Визуальная память создается путем извлечения и сохранения признаков из набора данных в базе данных. Когда представляется запрос изображения, его признаки сравниваются с теми, которые есть в визуальной памяти, чтобы извлечь ближайших соседей. Авторы представляют новый метод агрегации под названием RankVoting, который назначает веса соседям на основе ранга, превосходя традиционные методы и улучшая точность классификации.
Предложенная система визуальной памяти демонстрирует впечатляющие метрики производительности. Метод RankVoting эффективно решает ограничения существующих методов агрегации, которые часто страдают от ухудшения производительности при увеличении числа соседей. В отличие от этого, RankVoting улучшает точность с увеличением числа соседей, стабилизируя производительность при большем количестве. Авторы сообщают о достижении выдающейся точности валидации ImageNet на уровне 88,5% с использованием модели Gemini для визуально-языковой модели для переранжирования извлеченных соседей. Это превосходит базовую производительность как DinoV2 ViT-L14 kNN (83,5%), так и линейное зондирование (86,3%).
Гибкость визуальной памяти позволяет масштабироваться до наборов данных масштаба миллиардов без дополнительного обучения, а также удалять устаревшие данные путем разучивания и обрезки памяти. Эта адаптивность критически важна для приложений, требующих непрерывного обучения и обновления в динамических средах. Результаты показывают, что предложенная визуальная память не только улучшает точность классификации, но и предлагает надежную рамку для интеграции новой информации и поддержания актуальности модели со временем, обеспечивая надежное решение для динамических сред обучения.
Значимость и перспективы
Исследование подчеркивает огромный потенциал гибкой системы визуальной памяти в качестве решения для вызовов, предъявляемых статическими моделями глубокого обучения. Путем возможности добавления и удаления данных без повторного обучения предложенный метод решает потребность в адаптивности в машинном обучении. Техника RankVoting и интеграция моделей визуально-языковой обработки демонстрируют значительное улучшение производительности, проложив путь для широкого применения систем визуальной памяти в приложениях глубокого обучения и внушая оптимизм относительно их будущих применений.
Проверьте статью. Вся заслуга за это исследование принадлежит его авторам. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
Ученые из Центра искусственного интеллекта FPT Software представляют XMainframe: современную крупномасштабную языковую модель (LLM), специализированную для модернизации мейнфреймов для решения проблемы модернизации устаревшего кода на сумму в 100 миллиардов долларов.
Пост Google DeepMind Researchers Propose a Dynamic Visual Memory for Flexible Image Classification появилась сначала на MarkTechPost.









