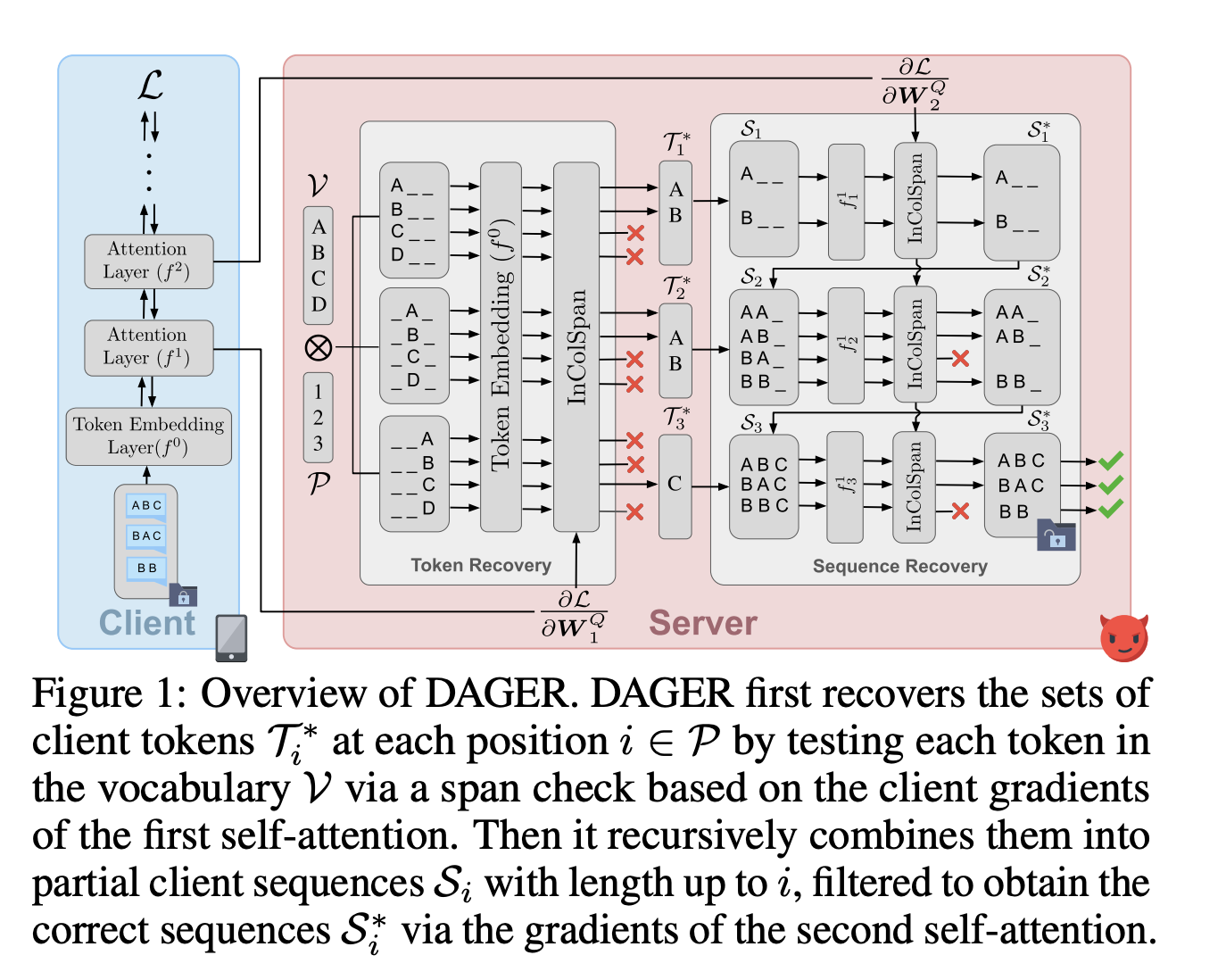
Преодоление проблем инверсии градиента в федеративном обучении: алгоритм DAGER для точной реконструкции текста
Федеративное обучение позволяет совместное обучение моделей путем агрегации градиентов с нескольких клиентов, сохраняя их частные данные. Однако атаки инверсии градиента могут нарушить эту конфиденциальность, восстанавливая исходные данные из общих градиентов. Новый алгоритм DAGER разработан для точной реконструкции текста, преодолевая ограничения предыдущих атак и обеспечивая высокую скорость, масштабируемость и качество восстановления.
Основные особенности алгоритма DAGER:
- Точная реконструкция целых пакетов входного текста
- Использование низкоранговой структуры градиентов слоев самовнимания и дискретной природы вложений токенов
- Эффективность для архитектур кодировщика и декодера
- Превосходство в скорости, масштабируемости и качестве восстановления по сравнению с предыдущими методами
Алгоритм DAGER демонстрирует высокую производительность на моделях GPT-2, LLaMa-2 и BERT, обеспечивая точные реконструкции пакетов размером до 128 на больших языковых моделях. Он также поддерживает большие пакеты и последовательности для трансформеров кодировщика и декодера, демонстрируя точную реконструкцию для языковых моделей на основе трансформеров.
Экспериментальная оценка алгоритма DAGER:
Алгоритм DAGER продемонстрировал свою превосходную производительность по сравнению с предыдущими методами на моделях BERT, GPT-2 и Llama2-7B, а также на наборах данных CoLA, SST-2, Rotten Tomatoes и ECHR. DAGER достиг точных реконструкций последовательностей, превосходя базовые модели декодера и кодировщика. Его эффективность была подтверждена снижением времени вычислений, а также его устойчивость к длинным последовательностям и большим моделям.
В заключение, алгоритм DAGER подчеркивает уязвимость декодеров на основе языковых моделей к утечке данных, что подчеркивает необходимость надежных мер конфиденциальности в совместном обучении.

























