Решение проблемы «Потерянное посередине» в больших языковых моделях: прорыв в калибровке внимания
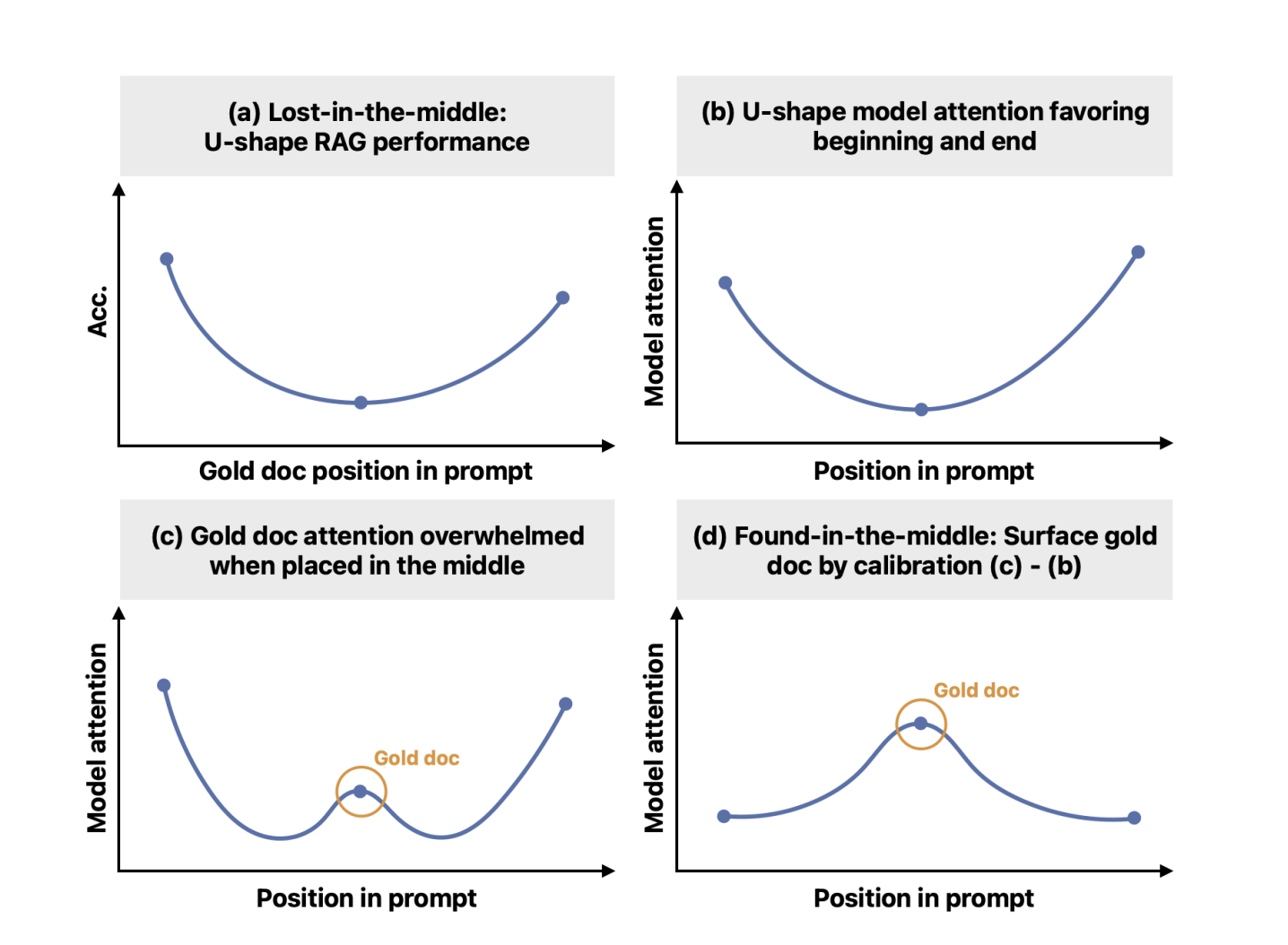
Несмотря на значительные успехи в области больших языковых моделей (LLM), LLM часто нуждаются в помощи с длинными контекстами, особенно там, где информация распределена по всему тексту. LLM теперь могут обрабатывать длинные тексты в качестве входных данных, но они все еще сталкиваются с проблемой «потерянного посередине». Их способность точно находить и использовать информацию в этом контексте ослабевает, поскольку соответствующая информация далека от начала или конца. Они склонны сосредотачиваться на информации в начале и конце, игнорируя то, что находится между ними.
Теоретическая база
Исследователи из Университета Вашингтона, MIT, Google Cloud AI Research и Google объединились, чтобы решить проблему «потерянного посередине». Несмотря на то, что модели обучены обрабатывать большие контексты ввода, у них есть внутренний возрастной биас внимания, который приводит к более высокому вниманию к токенам в начале и в конце ввода. Это снижает точность, когда критическая информация находится посередине. Цель исследования — смягчить возрастной биас, позволяя модели обращаться к контекстам исходя из их релевантности, независимо от их положения в последовательности ввода.
Инновационное решение
Текущие методы решения проблемы «потерянного посередине» зачастую включают повторное ранжирование релевантности документов и перемещение самых подходящих в начало или конец последовательности ввода. Однако эти методы обычно требуют дополнительного контроля или настройки и не решают фундаментально проблему способности LLM эффективно использовать информацию посередине последовательности. Чтобы преодолеть это ограничение, исследователи предлагают новый механизм калибровки под названием «найденное посередине».
Практическое применение
Предложенный механизм «найденное посередине» успешно разрешает возрастной биас, позволяя моделям внимательнее обращаться к контекстам и существенно улучшая производительность в задачах использования долгих контекстов. Это открывает новые возможности для улучшения механизмов внимания и их применения в различных пользовательских приложениях.

























