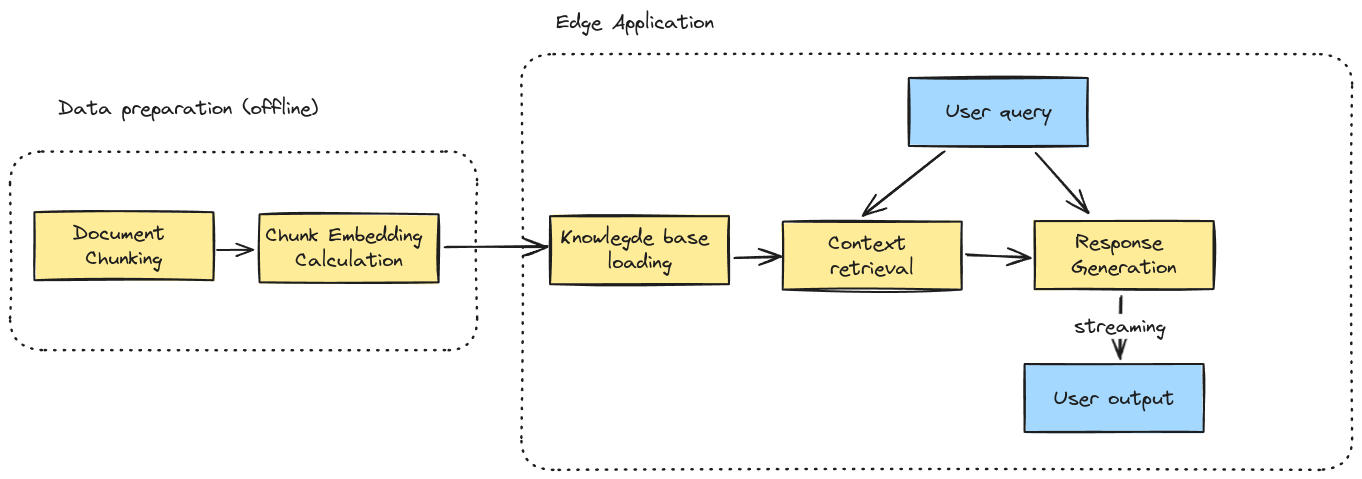
Реализация малых языковых моделей (SLM) с RAG на встроенных устройствах
В сегодняшнем быстро развивающемся мире генеративного искусственного интеллекта (ИИ) важно не только следить за последними технологическими тенденциями, но и стремиться к созданию новых решений. Наше последнее достижение объединяет Advanced Retrieval-Augmented Generation (RAG) с Small Language Models (SLMs) с целью расширения возможностей встроенных устройств за пределами традиционных облачных решений. Однако здесь не только технология важна – это также о бизнес-возможностях: снижение затрат, улучшение конфиденциальности данных и безпроблемное офлайн-функционирование.
Преимущества SLM на встроенных устройствах
В этом разделе мы представляем три убедительных причины, почему компании могут предпочесть применение приложений Small Language Model (SLM) перед их облачными аналогами Large Language Model (LLM):
- Снижение затрат: Расходы на облачное внедрение для Large Language Models могут быть запредельными. Перенос решений на основе LLM непосредственно на встроенные устройства устраняет необходимость облачного внедрения, что приводит к значительной экономии на масштабе. Это снижение затрат может быть основным стимулом для компаний, уже использующих облачные решения на основе LLM на мобильных телефонах или встроенных устройствах.
- Офлайн-функциональность: Развертывание SLM непосредственно на встроенных устройствах устраняет необходимость доступа к интернету, что делает решения на основе SLM подходящими для сценариев с ограниченной интернет-связью.
- Конфиденциальность данных: Иногда возникают опасения относительно облачных сервисов из-за требований по защите данных. Вся обработка происходит локально, что позволяет использовать решения на основе языковых моделей, соблюдая строгие протоколы защиты данных.
Если вам нужна помощь во внедрении решений на основе SLM, обратитесь к нам по адресу https://t.me/flycodetelegram


























