“`html
Продвижение в области дизайна последовательностей белков: использование обучения с подкреплением и языковых моделей
Дизайн последовательности белков критичен в инженерии белков для поиска лекарств. Традиционные методы, такие как эволюционные стратегии и монте-карло симуляции, часто нуждаются в помощи для эффективного изучения огромного комбинаторного пространства последовательностей аминокислот и обобщения на новые последовательности. Обучение с подкреплением предлагает многообещающий подход, обучая политики мутации для генерации новых последовательностей. Недавние достижения в языковых моделях белков (PLM), обученных на обширных наборах данных последовательностей белков, предоставляют другую возможность. Эти модели оценивают белки на основе биологических метрик, таких как TM-оценка, помогая в дизайне белков и предсказаниях складывания. Это важно для понимания клеточных функций и ускорения усилий по разработке лекарств.
Практические решения и ценность
Исследователи из Университета Макгилла, Института искусственного интеллекта Мила-Квебек, ЭТС Монреаля, Университета БРАК, Бангладешского университета инженерии и технологии, Университета Калгари, CIFAR AI Chair и Dreamfold предлагают использовать PLM в качестве функций вознаграждения для генерации новых последовательностей белков. Однако PLM могут быть вычислительно интенсивны из-за своего размера. Для решения этой проблемы они предлагают альтернативный подход, где оптимизация основана на оценках от более маленькой заменяющей модели, периодически донастраиваемой наряду с обучением политик мутации. Их эксперименты на различных длинах последовательностей показывают, что подходы на основе обучения с подкреплением достигают благоприятных результатов биологической правдоподобности и разнообразия последовательностей. Они предоставляют реализацию с открытым исходным кодом, облегчающую интеграцию различных PLM и алгоритмов исследования, нацеленных на продвижение исследований в области дизайна последовательностей белков.
Различные методы были изучены для проектирования биологических последовательностей. Эволюционные алгоритмы, такие как направленная эволюция и AdaLead, сосредотачиваются на итеративном мутировании последовательностей на основе метрик производительности. Covariance Matrix Adaptation Evolution Strategy (CMA-ES) генерирует кандидатские последовательности с использованием многомерного нормального распределения. Proximal Exploration (PEX) способствует выбору последовательностей, близких к дикотипу. Методы обучения с подкреплением, такие как DyNAPPO, оптимизируют заменяющие функции вознаграждения для генерации разнообразных последовательностей. GFlowNets выбирают составы пропорционально их функциям вознаграждения, облегчая разнообразные конечные состояния. Генеративные модели, такие как дискретная диффузия и модели на основе потока, такие как FoldFlow, генерируют белки в последовательности или пространстве структуры. Байесова оптимизация адаптирует заменяющие модели для оптимизации последовательностей, решая многокритериальные задачи проектирования белков. MCMC и байесовский подход выбирают последовательности на основе энергетических моделей и прогнозов структуры.
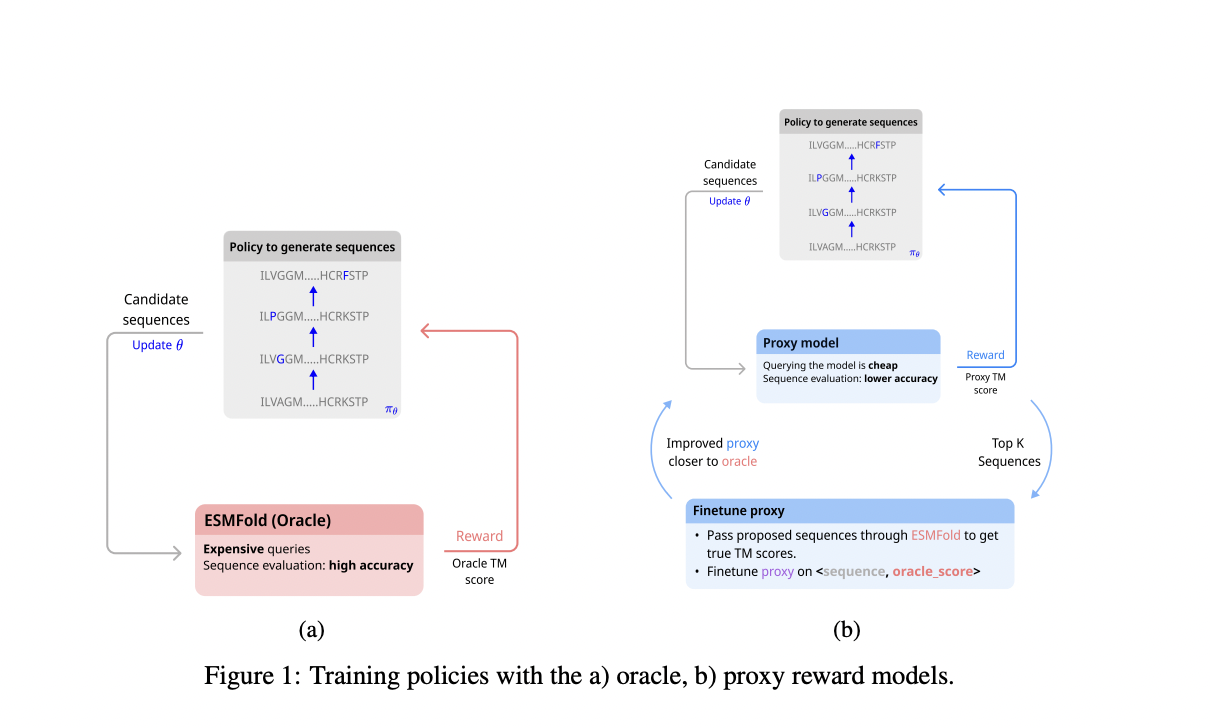
В области дизайна последовательностей белков с использованием обучения с подкреплением задача моделируется как процесс принятия решений Маркова (MDP), где последовательности мутируют на основе действий, выбранных политикой обучения с подкреплением. Последовательности представлены в формате кодирования one-hot, и мутации включают выбор позиций и замену аминокислот. Вознаграждения определяются путем оценки структурной схожести с использованием либо дорогой оракульной модели (ESMFold), либо более дешевой заменяющей модели, периодически донастраиваемой с истинными оценками от оракула. Критерии оценки сосредотачиваются на биологической правдоподобности и разнообразии, оцениваемых через метрики, такие как оценка шаблона (TM) и тест локального расстояния (LDDT), а также меры разнообразия последовательностей и структур.
Различные алгоритмы дизайна последовательностей были оценены с использованием оценок pTM от ESMFold в качестве основной метрики в проведенных экспериментах. Результаты показали, что методы, такие как MCMC, превосходили в прямой оптимизации pTM, в то время как методы обучения с подкреплением и GFlowNets продемонстрировали эффективность, используя заменяющую модель. Эти методы поддерживали высокие оценки pTM, существенно снижая вычислительные затраты. Однако производительность MCMC ухудшилась при донастройке с использованием заменяющей модели, возможно из-за попадания в субоптимальные решения, соответствующие заменяющей модели, но не ESMFold. В целом методы обучения с подкреплением, такие как PPO и SAC, наряду с GFlowNets, предложили надежную производительность по метрикам биологической правдоподобности и разнообразия, доказав свою адаптивность и эффективность для задач генерации последовательностей.
Исследовательские результаты ограничены вычислительными ограничениями для более длинных последовательностей и зависимостью от либо заменяющей модели, либо модели 3B ESMFold для оценки. Неопределенность или несоответствие в модели вознаграждения добавляют сложности, требуя будущего исследования с другими PLM, такими как AlphaFold2 или более крупными вариантами ESMFold. Масштабирование до более крупных заменяющих моделей может улучшить точность для более длинных последовательностей. Хотя исследование не предвидит негативных последствий, оно подчеркивает потенциальное злоупотребление PLM. В целом данная работа демонстрирует эффективность использования PLM для разработки политик мутации для генерации последовательностей белков, показывая глубокие алгоритмы обучения с подкреплением как надежных участников в этой области.
“`

























