“`html
Продвижение и преимущества в предсказании специфичности Т-клеточных рецепторов (TCR): от кластеризации до моделей языка белков
Недавние достижения в области иммунного секвенирования и экспериментальных методов генерируют обширные данные репертуара Т-клеточных рецепторов (TCR), позволяя создавать модели для предсказания специфичности связывания TCR. T-клетки играют роль в адаптивной иммунной системе, оркестрируя целенаправленные иммунные ответы через TCR, которые распознают несобственные антигены от патогенов или больных клеток. Разнообразие TCR, необходимое для распознавания разнообразных антигенов, образуется благодаря случайному перегруппировыванию ДНК, включающему сегменты генов V, D и J. В то время как теоретическое разнообразие TCR чрезвычайно высоко, фактическое разнообразие у конкретного индивида намного меньше. TCR взаимодействуют с пептидами на комплексе основной гистосовместимости (pMHC), причем некоторые TCR распознают многочисленные комплексы pMHC.
Эволюция вычислительных моделей для предсказания специфичности TCR
Исследователи из IBM Research Europe, Института вычислительных наук о жизни в Университете прикладных наук Цюриха и Йельской медицинской школы рассматривают эволюцию вычислительных моделей для предсказания специфичности связывания TCR. Подчеркивая машинное обучение, они освещают ранние методы неконтролируемой кластеризации, контролируемые модели и трансформационное воздействие моделей языка белков (PLM) в биоинформатике, особенно в анализе специфичности TCR. Обзор затрагивает смещения наборов данных, проблемы обобщения и недостатки валидации моделей. Он подчеркивает важность улучшения интерпретируемости моделей и извлечения биологических идей из больших, сложных моделей для улучшения предсказаний связывания TCR-pMHC и революционизации разработки иммунотерапии.
Текущие вызовы и практические решения
Данные о специфичности TCR поступают из таких баз данных, как VDJdb и McPas-TCR, но у этих наборов данных есть существенные ограничения. Массовое секвенирование имеет высокую производительность и экономическую эффективность, но не может обнаружить сопряженные α и β цепи, в то время как одноклеточные технологии, способные это сделать, дороги и недостаточно представлены. Большинство наборов данных фокусируются на ограниченном количестве эпитопов, в основном вирусного происхождения и связанных с общими аллелями HLA, что показывает значительное смещение. Кроме того, отсутствие отрицательных данных усложняет разработку контролируемых моделей машинного обучения. Генерация искусственных отрицательных пар вносит смещения, и модели высокой производительности могут запоминать последовательности, приводя к чересчур оптимистичным результатам. Обеспечение того, чтобы сгенерированные отрицательные пары точно отражали истинные небиндящие распределения, остается вызовом.
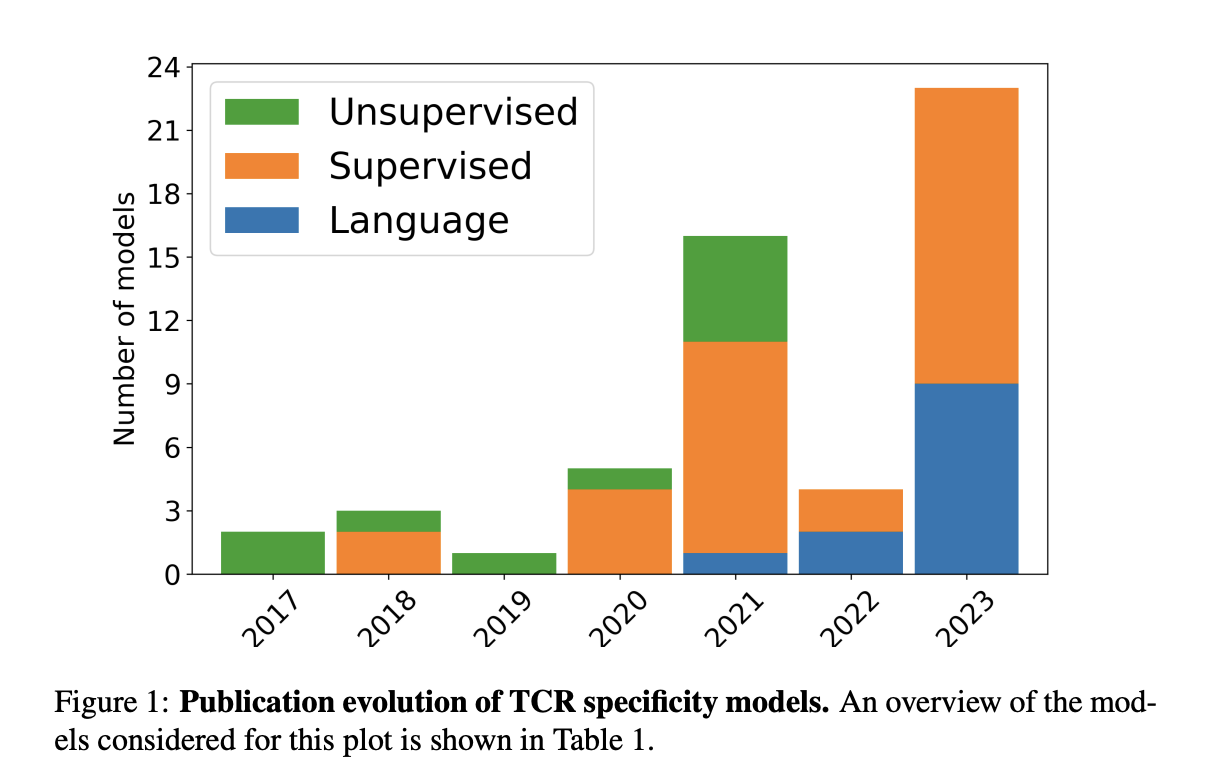
С 2017 года моделирование специфичности TCR значительно продвинулось, начиная с методов неконтролируемой кластеризации. Начальные модели, такие как TCRdist и GLIPH, группировали TCR на основе сходства последовательностей и биохимических свойств. Эти методы продемонстрировали, что последовательности TCR содержат ценную информацию о специфичности, но столкнулись с сложными нелинейными взаимодействиями. Это побудило к разработке контролируемых моделей, которые использовали техники машинного обучения для лучшей обработки растущей сложности данных. Ранние контролируемые модели, включая TCRGP и TCRex, использовали классификаторы, такие как гауссовы процессы и случайные леса, для предсказания специфичности TCR. Тем временем подходы на основе нейронных сетей, такие как NetTCR и DeepTCR, использовали передовые архитектуры для улучшения точности предсказаний.
Введение моделей PLM отметило последний прорыв в предсказании специфичности TCR. Основанные на архитектурах Transformer, эти модели были обучены на обширных наборах данных последовательностей белков и достигли замечательной производительности в различных задачах, связанных с белками. Например, TCR-BERT и STAPLER использовали модели на основе BERT, настроенные для классификации TCR и антигенов, продемонстрировав эффективность PLM в улавливании сложных взаимодействий последовательностей. Несмотря на свой успех, остаются вызовы в решении лексической многозначности и улучшении интерпретируемости моделей. Будущие улучшения в оптимизации встраивания и адаптации методов интерпретируемости, специфичных для последовательностей белков, критичны для дальнейших прорывов в предсказании специфичности TCR.
Точное предсказание специфичности TCR важно для улучшения иммунотерапий и понимания аутоиммунных заболеваний. Ограниченные и смещенные данные, особенно информация об эпитопах, ставят под сомнение текущие модели, затрудняя их обобщение на новые эпитопы. Прорывы в машинном обучении, включая сверточные нейронные сети, рекуррентные нейронные сети, перенос обучения и PLM, значительно улучшили модели предсказания TCR, но остаются вызовы, особенно в предсказании специфичности для новых эпитопов. Бенчмарки, такие как IMMREP22 и IMMREP23, подчеркивают трудности справедливого сравнения моделей и их обобщения. Адаптация моделей TCR для предсказания BCR, включающего нелинейные эпитопы и сложные взаимодействия с антигенами, представляет дополнительные вычислительные вызовы.
“`









