«`html
Интеграция передовых прогностических моделей в системы автономного вождения стала критически важной для повышения безопасности и эффективности.
Использование камеры для прогнозирования видео становится ключевым компонентом, предлагая богатые данные из реального мира. Генерация контента с использованием искусственного интеллекта в настоящее время является ведущей областью исследований в области компьютерного зрения и искусственного интеллекта. Однако генерация фотореалистичных и последовательных видеороликов представляет существенные трудности из-за ограниченной памяти и времени вычислений. Кроме того, прогнозирование видеороликов с передней камеры критически важно для систем помощи водителю в автономных транспортных средствах.
Существующие подходы включают диффузионные архитектуры, которые стали популярными для генерации изображений и видеороликов, обладая лучшей производительностью в задачах, таких как генерация изображений, редактирование и перевод. Другие методы, такие как генеративно-состязательные сети (GAN), модели на основе потока, авторегрессионные модели и вариационные автокодировщики (VAE), также использовались для генерации и прогнозирования видеороликов. Модели вероятностной диффузии для устранения шума (DDPM) превосходят традиционные модели генерации по эффективности. Однако генерация длинных видеороликов по-прежнему требует значительных вычислительных ресурсов. Хотя авторегрессионные модели, такие как Phenaki, решают эту проблему, они часто сталкиваются с вызовами в виде нереалистичных переходов сцен и несоответствий в более длинных последовательностях.
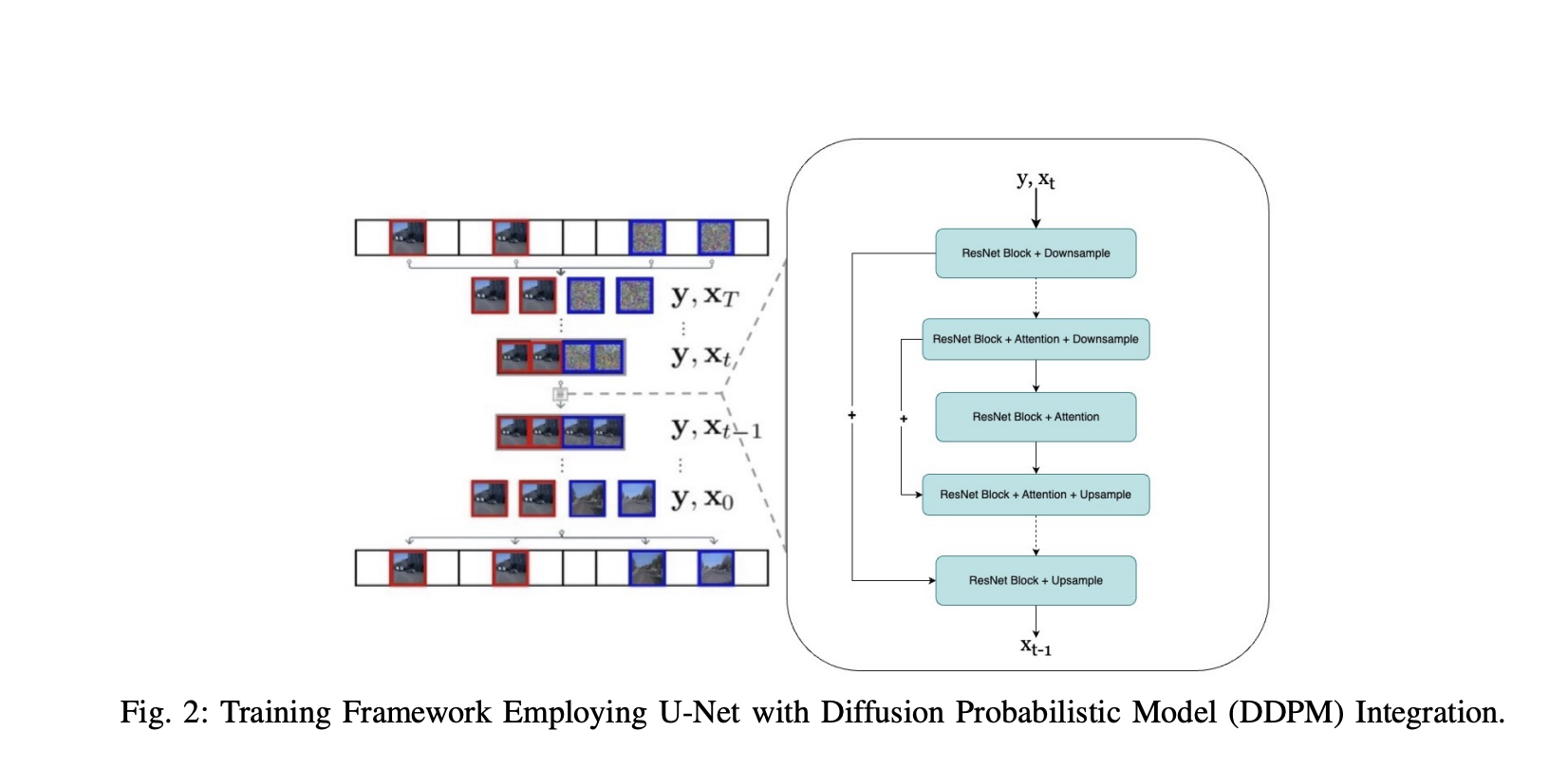
Команда исследователей из Колумбийского университета в Нью-Йорке предложила фреймворк DriveGenVLM для генерации видеороликов вождения и использовала модели видеороликов на основе языкового моделирования (VLM), чтобы их понимать. Фреймворк использует подход к генерации видеороликов на основе моделей вероятностной диффузии для прогнозирования видеороликов из реального мира. Предварительно обученная модель под названием Efficient In-context Learning on Egocentric Videos (EILEV) используется для оценки адекватности сгенерированных видеороликов для VLM. EILEV также предоставляет нарративы для этих сгенерированных видеороликов, потенциально улучшая понимание сцен дорожного движения, помогая в навигации и улучшая возможности планирования в автономном вождении.
Фреймворк DriveGenVLM проверен с использованием набора данных Waymo Open Dataset, который предоставляет разнообразные сценарии реального вождения из нескольких городов. Набор данных разделен на 108 видеороликов для обучения и равномерно распределенных между тремя камерами, и 30 видеороликов для тестирования (по 10 на камеру). Этот фреймворк использует метрику Frechet Video Distance (FVD) для оценки качества сгенерированных видеороликов, где FVD измеряет сходство между распределениями сгенерированных и реальных видеороликов. Эта метрика ценна для оценки временной последовательности и визуального качества, делая ее эффективным инструментом для оценки моделей синтеза видеороликов в задачах, таких как генерация видеороликов и прогнозирование будущих кадров.
Результаты для фреймворка DriveGenVLM на наборе данных Waymo Open Dataset для трех камер показывают, что адаптивный метод выборки иерархии-2 превосходит другие схемы выборки, обеспечивая наименьшие оценки FVD. Прогнозные видеоролики генерируются для каждой камеры с использованием этого превосходного метода выборки, где каждый пример зависит от первых 40 кадров, с реальными кадрами и предсказанными кадрами. Кроме того, обучение гибкой модели диффузии на наборе данных Waymo показывает ее способность к генерации последовательных и фотореалистичных видеороликов. Однако она по-прежнему сталкивается с вызовами в точной интерпретации сложных сцен реального вождения, таких как движение в трафике и среди пешеходов.
В заключение, исследователи из Колумбийского университета представили фреймворк DriveGenVLM для генерации видеороликов вождения. DDPM, обученная на наборе данных Waymo, профессионально генерирует последовательные и реалистичные изображения с передних и боковых камер. Кроме того, предварительно обученная модель EILEV используется для создания нарративов о действиях в видеороликах. Фреймворк DriveGenVLM подчеркивает потенциал интеграции генеративных моделей и VLM для задач автономного вождения. В будущем сгенерированные описания сцен вождения могут использоваться в крупных языковых моделях для предоставления помощи водителю или поддержки алгоритмов на основе языковых моделей.
«`

























